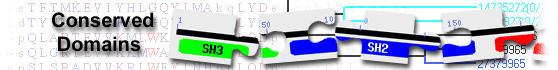M18 family aminopeptidase similar to aspartyl aminopeptidase, which displays specificity towards an acidic amino acid at the N-terminus, with preference to aspartate
M18 peptidase aspartyl aminopeptidase; Peptidase M18 family, aspartyl aminopeptidase (DAP; EC 3.4.11.21) subfamily, is widely distributed in bacteria and eukaryotes. DAP cleaves only unblocked N-terminal acidic amino-acid residues. It is a cytosolic enzyme and is highly conserved; for example, the human enzyme has 51% identity to an aspartyl aminopeptidase-like protein in Arabidopsis thaliana. The mammalian DAP is highly selective for hydrolysis of N-terminal aspartate or glutamate residues from peptides. Unlike glutamyl aminopeptidase (M42), DAP does not cleave simple aminoaryl-arylamide substrates. Although there is lack of understanding of the function of this enzyme, it is thought to act in concert with other aminopeptidases to facilitate protein turnover because of their restricted specificities for the N-terminal aspartic and glutamic acid, which cannot be cleaved by any other aminopeptidases. The mammalian aspartyl aminopeptidase is possibly contributing to the catabolism of peptides, including those produced by the proteasome. It may also trim the N-terminus of peptides that are intended for the MHC class I system. In humans, DAP has been implicated in the specific function of converting angiotensin II to the vasoactive angiotensin III within the brain. Saccharomyces cerevisiae aminopeptidase I (Ape1) is involved in protein degradation in vacuoles (the yeast lysosomes) where it is transported by the unique cytoplasm-to-vacuole targeting (Cvt) pathway under vegetative growth conditions and by the autophagy pathway during starvation. Its N-terminal propeptide region, which mediates higher-order complex formation, serves as a scaffolding cargo critical for the assembly of the Cvt vesicle for vacuolar delivery. Pseudomonas aeruginosa aminopeptidase (PaAP) shows that its activity is dependent on Co2+ rather than Zn2+, and is thus a cocatalytic cobalt peptidase rather than a zinc-dependent peptidase.
:
Pssm-ID: 349908 Cd Length: 439 Bit Score: 790.58 E-value: 0e+00
M18 peptidase aspartyl aminopeptidase; Peptidase M18 family, aspartyl aminopeptidase (DAP; EC 3.4.11.21) subfamily, is widely distributed in bacteria and eukaryotes. DAP cleaves only unblocked N-terminal acidic amino-acid residues. It is a cytosolic enzyme and is highly conserved; for example, the human enzyme has 51% identity to an aspartyl aminopeptidase-like protein in Arabidopsis thaliana. The mammalian DAP is highly selective for hydrolysis of N-terminal aspartate or glutamate residues from peptides. Unlike glutamyl aminopeptidase (M42), DAP does not cleave simple aminoaryl-arylamide substrates. Although there is lack of understanding of the function of this enzyme, it is thought to act in concert with other aminopeptidases to facilitate protein turnover because of their restricted specificities for the N-terminal aspartic and glutamic acid, which cannot be cleaved by any other aminopeptidases. The mammalian aspartyl aminopeptidase is possibly contributing to the catabolism of peptides, including those produced by the proteasome. It may also trim the N-terminus of peptides that are intended for the MHC class I system. In humans, DAP has been implicated in the specific function of converting angiotensin II to the vasoactive angiotensin III within the brain. Saccharomyces cerevisiae aminopeptidase I (Ape1) is involved in protein degradation in vacuoles (the yeast lysosomes) where it is transported by the unique cytoplasm-to-vacuole targeting (Cvt) pathway under vegetative growth conditions and by the autophagy pathway during starvation. Its N-terminal propeptide region, which mediates higher-order complex formation, serves as a scaffolding cargo critical for the assembly of the Cvt vesicle for vacuolar delivery. Pseudomonas aeruginosa aminopeptidase (PaAP) shows that its activity is dependent on Co2+ rather than Zn2+, and is thus a cocatalytic cobalt peptidase rather than a zinc-dependent peptidase.
Pssm-ID: 349908 Cd Length: 439 Bit Score: 790.58 E-value: 0e+00
M18 peptidase aspartyl aminopeptidase; Peptidase M18 family, aspartyl aminopeptidase (DAP; EC 3.4.11.21) subfamily, is widely distributed in bacteria and eukaryotes. DAP cleaves only unblocked N-terminal acidic amino-acid residues. It is a cytosolic enzyme and is highly conserved; for example, the human enzyme has 51% identity to an aspartyl aminopeptidase-like protein in Arabidopsis thaliana. The mammalian DAP is highly selective for hydrolysis of N-terminal aspartate or glutamate residues from peptides. Unlike glutamyl aminopeptidase (M42), DAP does not cleave simple aminoaryl-arylamide substrates. Although there is lack of understanding of the function of this enzyme, it is thought to act in concert with other aminopeptidases to facilitate protein turnover because of their restricted specificities for the N-terminal aspartic and glutamic acid, which cannot be cleaved by any other aminopeptidases. The mammalian aspartyl aminopeptidase is possibly contributing to the catabolism of peptides, including those produced by the proteasome. It may also trim the N-terminus of peptides that are intended for the MHC class I system. In humans, DAP has been implicated in the specific function of converting angiotensin II to the vasoactive angiotensin III within the brain. Saccharomyces cerevisiae aminopeptidase I (Ape1) is involved in protein degradation in vacuoles (the yeast lysosomes) where it is transported by the unique cytoplasm-to-vacuole targeting (Cvt) pathway under vegetative growth conditions and by the autophagy pathway during starvation. Its N-terminal propeptide region, which mediates higher-order complex formation, serves as a scaffolding cargo critical for the assembly of the Cvt vesicle for vacuolar delivery. Pseudomonas aeruginosa aminopeptidase (PaAP) shows that its activity is dependent on Co2+ rather than Zn2+, and is thus a cocatalytic cobalt peptidase rather than a zinc-dependent peptidase.
Pssm-ID: 349908 Cd Length: 439 Bit Score: 790.58 E-value: 0e+00
M18 peptidase aminopeptidase family; Peptidase M18 aminopeptidase family is widely distributed ...
36-481
0e+00
M18 peptidase aminopeptidase family; Peptidase M18 aminopeptidase family is widely distributed in bacteria and eukaryotes, but only the yeast aminopeptidase I and mammalian aspartyl aminopeptidase have been characterized to date. Yeast aminopeptidase I is active only in its dodecameric form with broad substrate specificity, acting on N-terminal leucine and most other amino acids. In contrast, the mammalian aspartyl aminopeptidase is highly selective for hydrolysis of N-terminal Asp or Glu residues from peptides. These enzymes have two catalytic zinc ions at the active site.
Pssm-ID: 349892 Cd Length: 430 Bit Score: 712.77 E-value: 0e+00
M18 peptidase aminopeptidase I; Peptidase M18 family, aminopeptidase I (vacuolar aminopeptidase I; polypeptidase; Leucine aminopeptidase IV; LAPIV; aminopeptidase III; aminopeptidase yscI; EC 3.4.11.22) subfamily. Aminopeptidase I is widely distributed in bacteria and eukaryotes, but only the yeast enzyme has been characterized to date. It is a vacuolar enzyme, synthesized as a cytosolic proform, and proteolytically matured upon arrival in the vacuole. The pro-aminopeptidase I (proAPI) does not enter the vacuole via the secretory pathway. In non-starved cells, it uses the cytoplasm to vacuole targeting (cvt) pathway and in cells starved for nitrogen, it is targeted to the vacuole via autophagy. Yeast aminopeptidase I is active only in its dodecameric form with broad substrate specificity, acting on all aminoacyl and peptidyl derivatives that contain a free alpha-amino group; this is in contrast to the highly selective M18 mammalian aspartyl aminopeptidase. N-terminal leucine and most other hydrophobic amino acid residues are the best substrates while glycine and charged amino acid residues in P1 position are cleaved much more slowly. This enzyme is strongly and specifically activated by zinc (Zn2+) and chloride (Cl-) ions.
Pssm-ID: 349909 Cd Length: 446 Bit Score: 137.13 E-value: 2.03e-35
Zinc peptidases M18, M20, M28, and M42; Zinc peptidases play vital roles in metabolic and ...
262-476
9.97e-25
Zinc peptidases M18, M20, M28, and M42; Zinc peptidases play vital roles in metabolic and signaling pathways throughout all kingdoms of life. This hierarchy contains zinc peptidases that correspond to the MH clan in the MEROPS database, which contains 4 families (M18, M20, M28, M42). The peptidase M20 family includes carboxypeptidases such as the glutamate carboxypeptidase from Pseudomonas, the thermostable carboxypeptidase Ss1 of broad specificity from archaea and yeast Gly-X carboxypeptidase. The dipeptidases include bacterial dipeptidase, peptidase V (PepV), a non-specific eukaryotic dipeptidase, and two Xaa-His dipeptidases (carnosinases). There is also the bacterial aminopeptidase, peptidase T (PepT) that acts only on tripeptide substrates and has therefore been termed a tripeptidase. Peptidase family M28 contains aminopeptidases and carboxypeptidases, and has co-catalytic zinc ions. However, several enzymes in this family utilize other first row transition metal ions such as cobalt and manganese. Each zinc ion is tetrahedrally co-ordinated, with three amino acid ligands plus activated water; one aspartate residue binds both metal ions. The aminopeptidases in this family are also called bacterial leucyl aminopeptidases, but are able to release a variety of N-terminal amino acids. IAP aminopeptidase and aminopeptidase Y preferentially release basic amino acids while glutamate carboxypeptidase II preferentially releases C-terminal glutamates. Glutamate carboxypeptidase II and plasma glutamate carboxypeptidase hydrolyze dipeptides. Peptidase families M18 and M42 contain metallo-aminopeptidases. M18 is widely distributed in bacteria and eukaryotes. However, only yeast aminopeptidase I and mammalian aspartyl aminopeptidase have been characterized in detail. Some M42 (also known as glutamyl aminopeptidase) enzymes exhibit aminopeptidase specificity while others also have acylaminoacyl-peptidase activity (i.e. hydrolysis of acylated N-terminal residues).
Pssm-ID: 349870 [Multi-domain] Cd Length: 200 Bit Score: 101.35 E-value: 9.97e-25
M20, M18 and M42 Zn-peptidases include aminopeptidases and carboxypeptidases; This family ...
262-476
2.69e-20
M20, M18 and M42 Zn-peptidases include aminopeptidases and carboxypeptidases; This family corresponds to the MEROPS MH clan families M18, M20, and M42. The peptidase M20 family contains exopeptidases, including carboxypeptidases such as the glutamate carboxypeptidase from Pseudomonas, the thermostable carboxypeptidase Ss1 of broad specificity from archaea and yeast Gly-X carboxypeptidase, dipeptidases such as bacterial dipeptidase, peptidase V (PepV), a eukaryotic, non-specific dipeptidase, and two Xaa-His dipeptidases (carnosinases). This family also includes the bacterial aminopeptidase peptidase T (PepT) that acts only on tripeptide substrates and has therefore been termed a tripeptidase. These peptidases generally hydrolyze the late products of protein degradation so as to complete the conversion of proteins to free amino acids. Glutamate carboxypeptidase hydrolyzes folate analogs such as methotrexate, and therefore can be used to treat methotrexate toxicity. Peptidase families M18 and M42 contain metallo-aminopeptidases. M18 (aspartyl aminopeptidase, DAP) family cleaves only unblocked N-terminal acidic amino-acid residues and is highly selective for hydrolyzing aspartate or glutamate residues. Some M42 (also known as glutamyl aminopeptidase) enzymes exhibit aminopeptidase specificity while others also have acylaminoacyl-peptidase activity (i.e. hydrolysis of acylated N-terminal residues).
Pssm-ID: 349948 [Multi-domain] Cd Length: 198 Bit Score: 88.64 E-value: 2.69e-20
M42 glutamyl aminopeptidase; These peptidases are found in Archaea and Bacteria. The example ...
246-464
1.47e-04
M42 glutamyl aminopeptidase; These peptidases are found in Archaea and Bacteria. The example in Lactococcus lactis, PepA, aids growth on milk. Pyrococcus horikoshii contain a thermostable de-blocking aminopeptidase member of this family used commercially for N-terminal protein sequencing.
Pssm-ID: 428431 [Multi-domain] Cd Length: 292 Bit Score: 43.71 E-value: 1.47e-04
M42 Peptidase, endoglucanases; Peptidase M42 family, Frv (Frv Operon Protein; Endo-1 4-Beta-Glucanase; Cellulase Protein; Endoglucanase; Endo-1 4-Beta-Glucanase Homolog; Glucanase; EC. 3.2.1.4) subfamily. Frv is a co-catalytic metallopeptidase, found in archaea and bacteria, including Pyrococcus horikoshii tetrahedral shaped phTET1 (DAPPh1; FrvX; PhDAP aminopeptidase; PhTET aminopeptidase; deblocking aminopeptidase), phTET2 (DAPPh2) and phTET3 (DAPPh3), Haloarcula marismortui TET (HmTET) as well as Bacillus subtilis YsdC. All of these exhibit aminopeptidase and deblocking activities. The HmTET is a broad substrate aminopeptidase capable of degrading large peptides. PhTET2, which shares 24% identity with HmTET, is a cobalt-activated peptidase and possibly a deblocking aminopeptidase, assembled as a 12-subunit tetrahedral dodecamer, while PhTET1 can be alternatively assembled as a tetrahedral dodecamer or as an octahedral tetracosameric structure. The active site in such a self-compartmentalized complex is located on the inside such that substrate sizes are limited, indicating function as possible peptide scavengers. PhTET2 cleaves polypeptides by a nonprocessive mechanism, preferring N-terminal hydrophobic or uncharged polar amino acids. Streptococcus pneumoniae PepA (SpPepA) also forms dodecamer with tetrahedral architecture, and exhibits selective substrate specificity to acidic amino acids with the preference to glutamic acid, with the substrate binding S1 pocket containing an Arg allows electrostatic interactions with the N-terminal acidic residue in the substrate. The YsdC gene is conserved in a number of thermophiles, archaea and pathogenic bacterial species; the closest structural homolog is Thermotoga maritima FrwX (34% identity), which is annotated as either a cellulase or an endoglucanase, and is possibly involved in polysaccharide biosynthesis or degradation.
Pssm-ID: 349906 [Multi-domain] Cd Length: 337 Bit Score: 40.24 E-value: 2.30e-03
Database: CDSEARCH/cdd Low complexity filter: no Composition Based Adjustment: yes E-value threshold: 0.01
References:
Wang J et al. (2023), "The conserved domain database in 2023", Nucleic Acids Res.51(D)384-8.
Lu S et al. (2020), "The conserved domain database in 2020", Nucleic Acids Res.48(D)265-8.
Marchler-Bauer A et al. (2017), "CDD/SPARCLE: functional classification of proteins via subfamily domain architectures.", Nucleic Acids Res.45(D)200-3.
of the residues that compose this conserved feature have been mapped to the query sequence.
Click on the triangle to view details about the feature, including a multiple sequence alignment
of your query sequence and the protein sequences used to curate the domain model,
where hash marks (#) above the aligned sequences show the location of the conserved feature residues.
The thumbnail image, if present, provides an approximate view of the feature's location in 3 dimensions.
Click on the triangle for interactive 3D structure viewing options.
Functional characterization of the conserved domain architecture found on the query.
Click here to see more details.
This image shows a graphical summary of conserved domains identified on the query sequence.
The Show Concise/Full Display button at the top of the page can be used to select the desired level of detail: only top scoring hits
(labeled illustration) or all hits
(labeled illustration).
Domains are color coded according to superfamilies
to which they have been assigned. Hits with scores that pass a domain-specific threshold
(specific hits) are drawn in bright colors.
Others (non-specific hits) and
superfamily placeholders are drawn in pastel colors.
if a domain or superfamily has been annotated with functional sites (conserved features),
they are mapped to the query sequence and indicated through sets of triangles
with the same color and shade of the domain or superfamily that provides the annotation. Mouse over the colored bars or triangles to see descriptions of the domains and features.
click on the bars or triangles to view your query sequence embedded in a multiple sequence alignment of the proteins used to develop the corresponding domain model.
The table lists conserved domains identified on the query sequence. Click on the plus sign (+) on the left to display full descriptions, alignments, and scores.
Click on the domain model's accession number to view the multiple sequence alignment of the proteins used to develop the corresponding domain model.
To view your query sequence embedded in that multiple sequence alignment, click on the colored bars in the Graphical Summary portion of the search results page,
or click on the triangles, if present, that represent functional sites (conserved features)
mapped to the query sequence.
Concise Display shows only the best scoring domain model, in each hit category listed below except non-specific hits, for each region on the query sequence.
(labeled illustration) Standard Display shows only the best scoring domain model from each source, in each hit category listed below for each region on the query sequence.
(labeled illustration) Full Display shows all domain models, in each hit category below, that meet or exceed the RPS-BLAST threshold for statistical significance.
(labeled illustration) Four types of hits can be shown, as available,
for each region on the query sequence:
specific hits meet or exceed a domain-specific e-value threshold
(illustrated example)
and represent a very high confidence that the query sequence belongs to the same protein family as the sequences use to create the domain model
non-specific hits
meet or exceed the RPS-BLAST threshold for statistical significance (default E-value cutoff of 0.01, or an E-value selected by user via the
advanced search options)
the domain superfamily to which the specific and non-specific hits belong
multi-domain models that were computationally detected and are likely to contain multiple single domains
Retrieve proteins that contain one or more of the domains present in the query sequence, using the Conserved Domain Architecture Retrieval Tool
(CDART).
Modify your query to search against a different database and/or use advanced search options