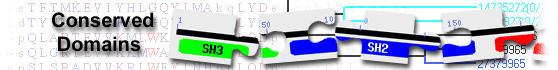


protein WWC2 isoform X3 [Homo sapiens]
Protein Classification

WW and C2_Kibra domain-containing protein( domain architecture ID 13628918)
protein containing domains WW, Smc, C2_Kibra, and PRK10929
List of domain hits
| Name | Accession | Description | Interval | E-value | |||||
| C2_Kibra | cd08680 | C2 domain found in Human protein Kibra; Kibra is thought to be a regulator of the Salvador ... |
700-800 | 2.31e-47 | |||||
C2 domain found in Human protein Kibra; Kibra is thought to be a regulator of the Salvador (Sav)/Warts (Wts)/Hippo (Hpo) (SWH) signaling network, which limits tissue growth by inhibiting cell proliferation and promoting apoptosis. The core of the pathway consists of a MST and LATS family kinase cascade that ultimately phosphorylates and inactivates the YAP/Yorkie (Yki) transcription coactivator. The FERM domain proteins Merlin (Mer) and Expanded (Ex) are part of the upstream regulation controlling pathway mechanism. Kibra colocalizes and associates with Mer and Ex and is thought to transduce an extracellular signal via the SWH network. The apical scaffold machinery that contains Hpo, Wts, and Ex recruits Yki to the apical membrane facilitating its inhibitory phosphorlyation by Wts. Since Kibra associates with Ex and is apically located it is hypothesized that KIBRA is part of the scaffold, helps in the Hpo/Wts complex, and helps recruit Yki for inactivation that promotes SWH pathway activity. Kibra contains two amino-terminal WW domains, an internal C2-like domain, and a carboxy-terminal glutamic acid-rich stretch. The C2 domain was first identified in PKC. C2 domains fold into an 8-standed beta-sandwich that can adopt 2 structural arrangements: Type I and Type II, distinguished by a circular permutation involving their N- and C-terminal beta strands. Many C2 domains are Ca2+-dependent membrane-targeting modules that bind a wide variety of substances including bind phospholipids, inositol polyphosphates, and intracellular proteins. Most C2 domain proteins are either signal transduction enzymes that contain a single C2 domain, such as protein kinase C, or membrane trafficking proteins which contain at least two C2 domains, such as synaptotagmin 1. However, there are a few exceptions to this including RIM isoforms and some splice variants of piccolo/aczonin and intersectin which only have a single C2 domain. C2 domains with a calcium binding region have negatively charged residues, primarily aspartates, that serve as ligands for calcium ions. : Pssm-ID: 176062 Cd Length: 124 Bit Score: 164.33 E-value: 2.31e-47
|
|||||||||
| WW | pfam00397 | WW domain; The WW domain is a protein module with two highly conserved tryptophans that binds ... |
12-41 | 7.41e-11 | |||||
WW domain; The WW domain is a protein module with two highly conserved tryptophans that binds proline-rich peptide motifs in vitro. : Pssm-ID: 459800 [Multi-domain] Cd Length: 30 Bit Score: 57.13 E-value: 7.41e-11
|
|||||||||
| WW | pfam00397 | WW domain; The WW domain is a protein module with two highly conserved tryptophans that binds ... |
59-88 | 4.89e-08 | |||||
WW domain; The WW domain is a protein module with two highly conserved tryptophans that binds proline-rich peptide motifs in vitro. : Pssm-ID: 459800 [Multi-domain] Cd Length: 30 Bit Score: 49.43 E-value: 4.89e-08
|
|||||||||
| Smc super family | cl34174 | Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; ... |
173-430 | 6.79e-06 | |||||
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; The actual alignment was detected with superfamily member COG1196: Pssm-ID: 440809 [Multi-domain] Cd Length: 983 Bit Score: 49.94 E-value: 6.79e-06
|
|||||||||
| Name | Accession | Description | Interval | E-value | ||||||
| C2_Kibra | cd08680 | C2 domain found in Human protein Kibra; Kibra is thought to be a regulator of the Salvador ... |
700-800 | 2.31e-47 | ||||||
C2 domain found in Human protein Kibra; Kibra is thought to be a regulator of the Salvador (Sav)/Warts (Wts)/Hippo (Hpo) (SWH) signaling network, which limits tissue growth by inhibiting cell proliferation and promoting apoptosis. The core of the pathway consists of a MST and LATS family kinase cascade that ultimately phosphorylates and inactivates the YAP/Yorkie (Yki) transcription coactivator. The FERM domain proteins Merlin (Mer) and Expanded (Ex) are part of the upstream regulation controlling pathway mechanism. Kibra colocalizes and associates with Mer and Ex and is thought to transduce an extracellular signal via the SWH network. The apical scaffold machinery that contains Hpo, Wts, and Ex recruits Yki to the apical membrane facilitating its inhibitory phosphorlyation by Wts. Since Kibra associates with Ex and is apically located it is hypothesized that KIBRA is part of the scaffold, helps in the Hpo/Wts complex, and helps recruit Yki for inactivation that promotes SWH pathway activity. Kibra contains two amino-terminal WW domains, an internal C2-like domain, and a carboxy-terminal glutamic acid-rich stretch. The C2 domain was first identified in PKC. C2 domains fold into an 8-standed beta-sandwich that can adopt 2 structural arrangements: Type I and Type II, distinguished by a circular permutation involving their N- and C-terminal beta strands. Many C2 domains are Ca2+-dependent membrane-targeting modules that bind a wide variety of substances including bind phospholipids, inositol polyphosphates, and intracellular proteins. Most C2 domain proteins are either signal transduction enzymes that contain a single C2 domain, such as protein kinase C, or membrane trafficking proteins which contain at least two C2 domains, such as synaptotagmin 1. However, there are a few exceptions to this including RIM isoforms and some splice variants of piccolo/aczonin and intersectin which only have a single C2 domain. C2 domains with a calcium binding region have negatively charged residues, primarily aspartates, that serve as ligands for calcium ions. Pssm-ID: 176062 Cd Length: 124 Bit Score: 164.33 E-value: 2.31e-47
|
||||||||||
| WW | pfam00397 | WW domain; The WW domain is a protein module with two highly conserved tryptophans that binds ... |
12-41 | 7.41e-11 | ||||||
WW domain; The WW domain is a protein module with two highly conserved tryptophans that binds proline-rich peptide motifs in vitro. Pssm-ID: 459800 [Multi-domain] Cd Length: 30 Bit Score: 57.13 E-value: 7.41e-11
|
||||||||||
| WW | smart00456 | Domain with 2 conserved Trp (W) residues; Also known as the WWP or rsp5 domain. Binds ... |
11-43 | 6.37e-10 | ||||||
Domain with 2 conserved Trp (W) residues; Also known as the WWP or rsp5 domain. Binds proline-rich polypeptides. Pssm-ID: 197736 [Multi-domain] Cd Length: 33 Bit Score: 54.91 E-value: 6.37e-10
|
||||||||||
| WW | cd00201 | Two conserved tryptophans domain; also known as the WWP or rsp5 domain; around 40 amino acids; ... |
13-43 | 1.84e-09 | ||||||
Two conserved tryptophans domain; also known as the WWP or rsp5 domain; around 40 amino acids; functions as an interaction module in a diverse set of signalling proteins; binds specific proline-rich sequences but at low affinities compared to other peptide recognition proteins such as antibodies and receptors; WW domains have a single groove formed by a conserved Trp and Tyr which recognizes a pair of residues of the sequence X-Pro; variable loops and neighboring domains confer specificity in this domain; there are five distinct groups based on binding: 1) PPXY motifs 2) the PPLP motif; 3) PGM motifs; 4) PSP or PTP motifs; 5) PR motifs. Pssm-ID: 238122 [Multi-domain] Cd Length: 31 Bit Score: 53.30 E-value: 1.84e-09
|
||||||||||
| WW | pfam00397 | WW domain; The WW domain is a protein module with two highly conserved tryptophans that binds ... |
59-88 | 4.89e-08 | ||||||
WW domain; The WW domain is a protein module with two highly conserved tryptophans that binds proline-rich peptide motifs in vitro. Pssm-ID: 459800 [Multi-domain] Cd Length: 30 Bit Score: 49.43 E-value: 4.89e-08
|
||||||||||
| Smc | COG1196 | Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; ... |
173-430 | 6.79e-06 | ||||||
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; Pssm-ID: 440809 [Multi-domain] Cd Length: 983 Bit Score: 49.94 E-value: 6.79e-06
|
||||||||||
| WW | cd00201 | Two conserved tryptophans domain; also known as the WWP or rsp5 domain; around 40 amino acids; ... |
62-89 | 1.04e-05 | ||||||
Two conserved tryptophans domain; also known as the WWP or rsp5 domain; around 40 amino acids; functions as an interaction module in a diverse set of signalling proteins; binds specific proline-rich sequences but at low affinities compared to other peptide recognition proteins such as antibodies and receptors; WW domains have a single groove formed by a conserved Trp and Tyr which recognizes a pair of residues of the sequence X-Pro; variable loops and neighboring domains confer specificity in this domain; there are five distinct groups based on binding: 1) PPXY motifs 2) the PPLP motif; 3) PGM motifs; 4) PSP or PTP motifs; 5) PR motifs. Pssm-ID: 238122 [Multi-domain] Cd Length: 31 Bit Score: 42.90 E-value: 1.04e-05
|
||||||||||
| WW | smart00456 | Domain with 2 conserved Trp (W) residues; Also known as the WWP or rsp5 domain. Binds ... |
59-89 | 1.08e-05 | ||||||
Domain with 2 conserved Trp (W) residues; Also known as the WWP or rsp5 domain. Binds proline-rich polypeptides. Pssm-ID: 197736 [Multi-domain] Cd Length: 33 Bit Score: 42.59 E-value: 1.08e-05
|
||||||||||
| PRK03918 | PRK03918 | DNA double-strand break repair ATPase Rad50; |
164-430 | 1.51e-05 | ||||||
DNA double-strand break repair ATPase Rad50; Pssm-ID: 235175 [Multi-domain] Cd Length: 880 Bit Score: 48.52 E-value: 1.51e-05
|
||||||||||
| SMC_prok_B | TIGR02168 | chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
115-415 | 6.84e-05 | ||||||
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins] Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 46.59 E-value: 6.84e-05
|
||||||||||
| DUF5401 | pfam17380 | Family of unknown function (DUF5401); This is a family of unknown function found in ... |
93-418 | 6.26e-04 | ||||||
Family of unknown function (DUF5401); This is a family of unknown function found in Chromadorea. Pssm-ID: 375164 [Multi-domain] Cd Length: 722 Bit Score: 43.19 E-value: 6.26e-04
|
||||||||||
| Name | Accession | Description | Interval | E-value | ||||||
| C2_Kibra | cd08680 | C2 domain found in Human protein Kibra; Kibra is thought to be a regulator of the Salvador ... |
700-800 | 2.31e-47 | ||||||
C2 domain found in Human protein Kibra; Kibra is thought to be a regulator of the Salvador (Sav)/Warts (Wts)/Hippo (Hpo) (SWH) signaling network, which limits tissue growth by inhibiting cell proliferation and promoting apoptosis. The core of the pathway consists of a MST and LATS family kinase cascade that ultimately phosphorylates and inactivates the YAP/Yorkie (Yki) transcription coactivator. The FERM domain proteins Merlin (Mer) and Expanded (Ex) are part of the upstream regulation controlling pathway mechanism. Kibra colocalizes and associates with Mer and Ex and is thought to transduce an extracellular signal via the SWH network. The apical scaffold machinery that contains Hpo, Wts, and Ex recruits Yki to the apical membrane facilitating its inhibitory phosphorlyation by Wts. Since Kibra associates with Ex and is apically located it is hypothesized that KIBRA is part of the scaffold, helps in the Hpo/Wts complex, and helps recruit Yki for inactivation that promotes SWH pathway activity. Kibra contains two amino-terminal WW domains, an internal C2-like domain, and a carboxy-terminal glutamic acid-rich stretch. The C2 domain was first identified in PKC. C2 domains fold into an 8-standed beta-sandwich that can adopt 2 structural arrangements: Type I and Type II, distinguished by a circular permutation involving their N- and C-terminal beta strands. Many C2 domains are Ca2+-dependent membrane-targeting modules that bind a wide variety of substances including bind phospholipids, inositol polyphosphates, and intracellular proteins. Most C2 domain proteins are either signal transduction enzymes that contain a single C2 domain, such as protein kinase C, or membrane trafficking proteins which contain at least two C2 domains, such as synaptotagmin 1. However, there are a few exceptions to this including RIM isoforms and some splice variants of piccolo/aczonin and intersectin which only have a single C2 domain. C2 domains with a calcium binding region have negatively charged residues, primarily aspartates, that serve as ligands for calcium ions. Pssm-ID: 176062 Cd Length: 124 Bit Score: 164.33 E-value: 2.31e-47
|
||||||||||
| WW | pfam00397 | WW domain; The WW domain is a protein module with two highly conserved tryptophans that binds ... |
12-41 | 7.41e-11 | ||||||
WW domain; The WW domain is a protein module with two highly conserved tryptophans that binds proline-rich peptide motifs in vitro. Pssm-ID: 459800 [Multi-domain] Cd Length: 30 Bit Score: 57.13 E-value: 7.41e-11
|
||||||||||
| WW | smart00456 | Domain with 2 conserved Trp (W) residues; Also known as the WWP or rsp5 domain. Binds ... |
11-43 | 6.37e-10 | ||||||
Domain with 2 conserved Trp (W) residues; Also known as the WWP or rsp5 domain. Binds proline-rich polypeptides. Pssm-ID: 197736 [Multi-domain] Cd Length: 33 Bit Score: 54.91 E-value: 6.37e-10
|
||||||||||
| WW | cd00201 | Two conserved tryptophans domain; also known as the WWP or rsp5 domain; around 40 amino acids; ... |
13-43 | 1.84e-09 | ||||||
Two conserved tryptophans domain; also known as the WWP or rsp5 domain; around 40 amino acids; functions as an interaction module in a diverse set of signalling proteins; binds specific proline-rich sequences but at low affinities compared to other peptide recognition proteins such as antibodies and receptors; WW domains have a single groove formed by a conserved Trp and Tyr which recognizes a pair of residues of the sequence X-Pro; variable loops and neighboring domains confer specificity in this domain; there are five distinct groups based on binding: 1) PPXY motifs 2) the PPLP motif; 3) PGM motifs; 4) PSP or PTP motifs; 5) PR motifs. Pssm-ID: 238122 [Multi-domain] Cd Length: 31 Bit Score: 53.30 E-value: 1.84e-09
|
||||||||||
| WW | pfam00397 | WW domain; The WW domain is a protein module with two highly conserved tryptophans that binds ... |
59-88 | 4.89e-08 | ||||||
WW domain; The WW domain is a protein module with two highly conserved tryptophans that binds proline-rich peptide motifs in vitro. Pssm-ID: 459800 [Multi-domain] Cd Length: 30 Bit Score: 49.43 E-value: 4.89e-08
|
||||||||||
| C2C_KIAA1228 | cd04030 | C2 domain third repeat present in uncharacterized human KIAA1228-like proteins; KIAA proteins ... |
698-790 | 7.24e-07 | ||||||
C2 domain third repeat present in uncharacterized human KIAA1228-like proteins; KIAA proteins are uncharacterized human proteins. They were compiled by the Kazusa mammalian cDNA project which identified more than 2000 human genes. They are identified by 4 digit codes that precede the KIAA designation. Many KIAA genes are still functionally uncharacterized including KIAA1228. C2 domains fold into an 8-standed beta-sandwich that can adopt 2 structural arrangements: Type I and Type II, distinguished by a circular permutation involving their N- and C-terminal beta strands. Many C2 domains are Ca2+-dependent membrane-targeting modules that bind a wide variety of substances including bind phospholipids, inositol polyphosphates, and intracellular proteins. Most C2 domain proteins are either signal transduction enzymes that contain a single C2 domain, such as protein kinase C, or membrane trafficking proteins which contain at least two C2 domains, such as synaptotagmin 1. However, there are a few exceptions to this including RIM isoforms and some splice variants of piccolo/aczonin and intersectin which only have a single C2 domain. C2 domains with a calcium binding region have negatively charged residues, primarily aspartates, that serve as ligands for calcium ions. This cd contains the third C2 repeat, C2C, and has a type-II topology. Pssm-ID: 175996 [Multi-domain] Cd Length: 127 Bit Score: 48.81 E-value: 7.24e-07
|
||||||||||
| C2A_Synaptotagmin-8 | cd08387 | C2A domain first repeat present in Synaptotagmin 8; Synaptotagmin is a membrane-trafficking ... |
699-800 | 3.74e-06 | ||||||
C2A domain first repeat present in Synaptotagmin 8; Synaptotagmin is a membrane-trafficking protein characterized by a N-terminal transmembrane region, a linker, and 2 C-terminal C2 domains. Previously all synaptotagmins were thought to be calcium sensors in the regulation of neurotransmitter release and hormone secretion, but it has been shown that not all of them bind calcium. Of the 17 identified synaptotagmins only 8 bind calcium (1-3, 5-7, 9, 10). The function of the two C2 domains that bind calcium are: regulating the fusion step of synaptic vesicle exocytosis (C2A) and binding to phosphatidyl-inositol-3,4,5-triphosphate (PIP3) in the absence of calcium ions and to phosphatidylinositol bisphosphate (PIP2) in their presence (C2B). C2B also regulates also the recycling step of synaptic vesicles. C2 domains fold into an 8-standed beta-sandwich that can adopt 2 structural arrangements: Type I and Type II, distinguished by a circular permutation involving their N- and C-terminal beta strands. Many C2 domains are Ca2+-dependent membrane-targeting modules that bind a wide variety of substances including bind phospholipids, inositol polyphosphates, and intracellular proteins. Most C2 domain proteins are either signal transduction enzymes that contain a single C2 domain, such as protein kinase C, or membrane trafficking proteins which contain at least two C2 domains, such as synaptotagmin 1. However, there are a few exceptions to this including RIM isoforms and some splice variants of piccolo/aczonin and intersectin which only have a single C2 domain. C2 domains with a calcium binding region have negatively charged residues, primarily aspartates, that serve as ligands for calcium ions. This cd contains the first C2 repeat, C2A, and has a type-I topology. Pssm-ID: 176033 [Multi-domain] Cd Length: 124 Bit Score: 46.63 E-value: 3.74e-06
|
||||||||||
| C2A_Synaptotagmin-1-5-6-9-10 | cd08385 | C2A domain first repeat present in Synaptotagmins 1, 5, 6, 9, and 10; Synaptotagmin is a ... |
702-794 | 5.04e-06 | ||||||
C2A domain first repeat present in Synaptotagmins 1, 5, 6, 9, and 10; Synaptotagmin is a membrane-trafficking protein characterized by a N-terminal transmembrane region, a linker, and 2 C-terminal C2 domains. Synaptotagmin 1, a member of class 1 synaptotagmins, is located in the brain and endocranium and localized to the synaptic vesicles and secretory granules. It functions as a Ca2+ sensor for fast exocytosis as do synaptotagmins 5, 6, and 10. It is distinguished from the other synaptotagmins by having an N-glycosylated N-terminus. Synaptotagmins 5, 6, and 10, members of class 3 synaptotagmins, are located primarily in the brain and localized to the active zone and plasma membrane. They is distinguished from the other synaptotagmins by having disulfide bonds at its N-terminus. Synaptotagmin 6 also regulates the acrosome reaction, a unique Ca2+-regulated exocytosis, in sperm. Synaptotagmin 9, a class 5 synaptotagmins, is located in the brain and localized to the synaptic vesicles. It is thought to be a Ca2+-sensor for dense-core vesicle exocytosis. Previously all synaptotagmins were thought to be calcium sensors in the regulation of neurotransmitter release and hormone secretion, but it has been shown that not all of them bind calcium. Of the 17 identified synaptotagmins only 8 bind calcium (1-3, 5-7, 9, 10). The function of the two C2 domains that bind calcium are: regulating the fusion step of synaptic vesicle exocytosis (C2A) and binding to phosphatidyl-inositol-3,4,5-triphosphate (PIP3) in the absence of calcium ions and to phosphatidylinositol bisphosphate (PIP2) in their presence (C2B). C2B also regulates also the recycling step of synaptic vesicles. C2 domains fold into an 8-standed beta-sandwich that can adopt 2 structural arrangements: Type I and Type II, distinguished by a circular permutation involving their N- and C-terminal beta strands. Many C2 domains are Ca2+-dependent membrane-targeting modules that bind a wide variety of substances including bind phospholipids, inositol polyphosphates, and intracellular proteins. Most C2 domain proteins are either signal transduction enzymes that contain a single C2 domain, such as protein kinase C, or membrane trafficking proteins which contain at least two C2 domains, such as synaptotagmin 1. However, there are a few exceptions to this including RIM isoforms and some splice variants of piccolo/aczonin and intersectin which only have a single C2 domain. C2 domains with a calcium binding region have negatively charged residues, primarily aspartates, that serve as ligands for calcium ions. This cd contains the first C2 repeat, C2A, and has a type-I topology. Pssm-ID: 176031 [Multi-domain] Cd Length: 124 Bit Score: 46.49 E-value: 5.04e-06
|
||||||||||
| Smc | COG1196 | Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; ... |
173-430 | 6.79e-06 | ||||||
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; Pssm-ID: 440809 [Multi-domain] Cd Length: 983 Bit Score: 49.94 E-value: 6.79e-06
|
||||||||||
| WW | cd00201 | Two conserved tryptophans domain; also known as the WWP or rsp5 domain; around 40 amino acids; ... |
62-89 | 1.04e-05 | ||||||
Two conserved tryptophans domain; also known as the WWP or rsp5 domain; around 40 amino acids; functions as an interaction module in a diverse set of signalling proteins; binds specific proline-rich sequences but at low affinities compared to other peptide recognition proteins such as antibodies and receptors; WW domains have a single groove formed by a conserved Trp and Tyr which recognizes a pair of residues of the sequence X-Pro; variable loops and neighboring domains confer specificity in this domain; there are five distinct groups based on binding: 1) PPXY motifs 2) the PPLP motif; 3) PGM motifs; 4) PSP or PTP motifs; 5) PR motifs. Pssm-ID: 238122 [Multi-domain] Cd Length: 31 Bit Score: 42.90 E-value: 1.04e-05
|
||||||||||
| WW | smart00456 | Domain with 2 conserved Trp (W) residues; Also known as the WWP or rsp5 domain. Binds ... |
59-89 | 1.08e-05 | ||||||
Domain with 2 conserved Trp (W) residues; Also known as the WWP or rsp5 domain. Binds proline-rich polypeptides. Pssm-ID: 197736 [Multi-domain] Cd Length: 33 Bit Score: 42.59 E-value: 1.08e-05
|
||||||||||
| C2A_SLP | cd08521 | C2 domain first repeat present in Synaptotagmin-like proteins; All Slp members basically share ... |
701-796 | 1.19e-05 | ||||||
C2 domain first repeat present in Synaptotagmin-like proteins; All Slp members basically share an N-terminal Slp homology domain (SHD) and C-terminal tandem C2 domains (named the C2A domain and the C2B domain) with the SHD and C2 domains being separated by a linker sequence of various length. Slp1/JFC1 and Slp2/exophilin 4 promote granule docking to the plasma membrane. Additionally, their C2A domains are both Ca2+ independent, unlike the case in Slp3 and Slp4/granuphilin in which their C2A domains are Ca2+ dependent. It is thought that SHD (except for the Slp4-SHD) functions as a specific Rab27A/B-binding domain. In addition to Slps, rabphilin, Noc2, and Munc13-4 also function as Rab27-binding proteins. It has been demonstrated that Slp3 and Slp4/granuphilin promote dense-core vesicle exocytosis. Slp5 mRNA has been shown to be restricted to human placenta and liver suggesting a role in Rab27A-dependent membrane trafficking in specific tissues. C2 domains fold into an 8-standed beta-sandwich that can adopt 2 structural arrangements: Type I and Type II, distinguished by a circular permutation involving their N- and C-terminal beta strands. Many C2 domains are Ca2+-dependent membrane-targeting modules that bind a wide variety of substances including bind phospholipids, inositol polyphosphates, and intracellular proteins. Most C2 domain proteins are either signal transduction enzymes that contain a single C2 domain, such as protein kinase C, or membrane trafficking proteins which contain at least two C2 domains, such as synaptotagmin 1. However, there are a few exceptions to this including RIM isoforms and some splice variants of piccolo/aczonin and intersectin which only have a single C2 domain. C2 domains with a calcium binding region have negatively charged residues, primarily aspartates, that serve as ligands for calcium ions. This cd contains the first C2 repeat, C2A, and has a type-I topology. Pssm-ID: 176056 [Multi-domain] Cd Length: 123 Bit Score: 45.32 E-value: 1.19e-05
|
||||||||||
| PRK03918 | PRK03918 | DNA double-strand break repair ATPase Rad50; |
164-430 | 1.51e-05 | ||||||
DNA double-strand break repair ATPase Rad50; Pssm-ID: 235175 [Multi-domain] Cd Length: 880 Bit Score: 48.52 E-value: 1.51e-05
|
||||||||||
| C2B_Synaptotagmin | cd00276 | C2 domain second repeat present in Synaptotagmin; Synaptotagmin is a membrane-trafficking ... |
700-800 | 4.24e-05 | ||||||
C2 domain second repeat present in Synaptotagmin; Synaptotagmin is a membrane-trafficking protein characterized by a N-terminal transmembrane region, a linker, and 2 C-terminal C2 domains. There are several classes of Synaptotagmins. Previously all synaptotagmins were thought to be calcium sensors in the regulation of neurotransmitter release and hormone secretion, but it has been shown that not all of them bind calcium. Of the 17 identified synaptotagmins only 8 bind calcium (1-3, 5-7, 9, 10). The function of the two C2 domains that bind calcium are: regulating the fusion step of synaptic vesicle exocytosis (C2A) and binding to phosphatidyl-inositol-3,4,5-triphosphate (PIP3) in the absence of calcium ions and to phosphatidylinositol bisphosphate (PIP2) in their presence (C2B). C2B also regulates also the recycling step of synaptic vesicles. C2 domains fold into an 8-standed beta-sandwich that can adopt 2 structural arrangements: Type I and Type II, distinguished by a circular permutation involving their N- and C-terminal beta strands. Many C2 domains are Ca2+-dependent membrane-targeting modules that bind a wide variety of substances including bind phospholipids, inositol polyphosphates, and intracellular proteins. Most C2 domain proteins are either signal transduction enzymes that contain a single C2 domain, such as protein kinase C, or membrane trafficking proteins which contain at least two C2 domains, such as synaptotagmin 1. However, there are a few exceptions to this including RIM isoforms and some splice variants of piccolo/aczonin and intersectin which only have a single C2 domain. C2 domains with a calcium binding region have negatively charged residues, primarily aspartates, that serve as ligands for calcium ions. This cd contains the second C2 repeat, C2B, and has a type-I topology. Pssm-ID: 175975 [Multi-domain] Cd Length: 134 Bit Score: 44.11 E-value: 4.24e-05
|
||||||||||
| EnvC | COG4942 | Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, ... |
176-453 | 5.60e-05 | ||||||
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, cell division, chromosome partitioning]; Pssm-ID: 443969 [Multi-domain] Cd Length: 377 Bit Score: 46.30 E-value: 5.60e-05
|
||||||||||
| EnvC | COG4942 | Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, ... |
164-385 | 5.85e-05 | ||||||
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, cell division, chromosome partitioning]; Pssm-ID: 443969 [Multi-domain] Cd Length: 377 Bit Score: 46.30 E-value: 5.85e-05
|
||||||||||
| SMC_prok_B | TIGR02168 | chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
115-415 | 6.84e-05 | ||||||
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins] Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 46.59 E-value: 6.84e-05
|
||||||||||
| SMC_prok_A | TIGR02169 | chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ... |
162-432 | 1.13e-04 | ||||||
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins] Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 45.83 E-value: 1.13e-04
|
||||||||||
| SMC_prok_B | TIGR02168 | chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
165-418 | 1.86e-04 | ||||||
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins] Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 45.05 E-value: 1.86e-04
|
||||||||||
| SMC_prok_A | TIGR02169 | chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ... |
206-417 | 2.94e-04 | ||||||
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins] Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 44.67 E-value: 2.94e-04
|
||||||||||
| YhaN | COG4717 | Uncharacterized conserved protein YhaN, contains AAA domain [Function unknown]; |
78-432 | 4.17e-04 | ||||||
Uncharacterized conserved protein YhaN, contains AAA domain [Function unknown]; Pssm-ID: 443752 [Multi-domain] Cd Length: 641 Bit Score: 43.99 E-value: 4.17e-04
|
||||||||||
| SMC_prok_A | TIGR02169 | chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ... |
164-415 | 4.43e-04 | ||||||
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins] Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 43.90 E-value: 4.43e-04
|
||||||||||
| DUF5401 | pfam17380 | Family of unknown function (DUF5401); This is a family of unknown function found in ... |
93-418 | 6.26e-04 | ||||||
Family of unknown function (DUF5401); This is a family of unknown function found in Chromadorea. Pssm-ID: 375164 [Multi-domain] Cd Length: 722 Bit Score: 43.19 E-value: 6.26e-04
|
||||||||||
| SMC_prok_A | TIGR02169 | chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ... |
162-415 | 6.71e-04 | ||||||
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins] Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 43.52 E-value: 6.71e-04
|
||||||||||
| SMC_prok_A | TIGR02169 | chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ... |
95-419 | 1.06e-03 | ||||||
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins] Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 42.75 E-value: 1.06e-03
|
||||||||||
| HMMR_N | pfam15905 | Hyaluronan mediated motility receptor N-terminal; HMMR_N is the N-terminal region of ... |
137-417 | 1.21e-03 | ||||||
Hyaluronan mediated motility receptor N-terminal; HMMR_N is the N-terminal region of eukaryotic hyaluronan-mediated motility receptor proteins. The protein is functionally associated with BRCA1 and thus predicted to be a common, low-penetrance breast cancer candidate. Pssm-ID: 464932 [Multi-domain] Cd Length: 329 Bit Score: 41.72 E-value: 1.21e-03
|
||||||||||
| YhaN | COG4717 | Uncharacterized conserved protein YhaN, contains AAA domain [Function unknown]; |
84-432 | 1.90e-03 | ||||||
Uncharacterized conserved protein YhaN, contains AAA domain [Function unknown]; Pssm-ID: 443752 [Multi-domain] Cd Length: 641 Bit Score: 41.68 E-value: 1.90e-03
|
||||||||||
| COG4026 | COG4026 | Uncharacterized conserved protein, contains TOPRIM domain, potential nuclease [General ... |
338-420 | 2.09e-03 | ||||||
Uncharacterized conserved protein, contains TOPRIM domain, potential nuclease [General function prediction only]; Pssm-ID: 443204 [Multi-domain] Cd Length: 287 Bit Score: 40.87 E-value: 2.09e-03
|
||||||||||
| SMC_prok_B | TIGR02168 | chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
307-432 | 2.70e-03 | ||||||
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins] Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 41.58 E-value: 2.70e-03
|
||||||||||
| COG4372 | COG4372 | Uncharacterized protein, contains DUF3084 domain [Function unknown]; |
299-432 | 3.73e-03 | ||||||
Uncharacterized protein, contains DUF3084 domain [Function unknown]; Pssm-ID: 443500 [Multi-domain] Cd Length: 370 Bit Score: 40.66 E-value: 3.73e-03
|
||||||||||
| Smc | COG1196 | Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; ... |
303-432 | 8.68e-03 | ||||||
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; Pssm-ID: 440809 [Multi-domain] Cd Length: 983 Bit Score: 39.92 E-value: 8.68e-03
|
||||||||||
| Blast search parameters | ||||
|
