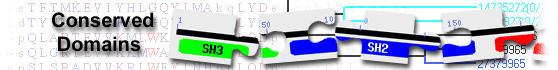|
Name |
Accession |
Description |
Interval |
E-value |
| SKICH |
pfam17751 |
SKICH domain; The SKICH domains of SKIP and PIPP mediate plasma membrane localization. The ... |
17-120 |
1.31e-47 |
|
SKICH domain; The SKICH domains of SKIP and PIPP mediate plasma membrane localization. The functions of the SKICH domains of NDP52 and CALCOCO1 are not known.
Pssm-ID: 465482 Cd Length: 102 Bit Score: 163.57 E-value: 1.31e-47
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 17 VIFQNVAKSYLPNAHLECHYTLTPYIHPHPKDWVGIFKVGWSTARDYYTFLWSpmPEHYVEGSTVNCVLAFQGYYLPNDD 96
Cdd:pfam17751 1 VVFQNVGEWYPPDEDIECSYTLTPDFTPSSWDWIGLFKVGWKSVNDYVTYVWA--KDDEVEGSNSVRQVLFKASYLPKEP 78
|
90 100
....*....|....*....|....
gi 1384071986 97 GEFYQFCYVTHKGEIRGASTPFQF 120
Cdd:pfam17751 79 EGFYQFCYVSNLGSVVGISTPFQF 102
|
|
| CALCOCO1 |
pfam07888 |
Calcium binding and coiled-coil domain (CALCOCO1) like; Proteins found in this family are ... |
125-460 |
1.25e-39 |
|
Calcium binding and coiled-coil domain (CALCOCO1) like; Proteins found in this family are similar to the coiled-coil transcriptional coactivator protein coexpressed by Mus musculus (CoCoA/CALCOCO1). This protein binds to a highly conserved N-terminal domain of p160 coactivators, such as GRIP1, and thus enhances transcriptional activation by a number of nuclear receptors. CALCOCO1 has a central coiled-coil region with three leucine zipper motifs, which is required for its interaction with GRIP1 and may regulate the autonomous transcriptional activation activity of the C-terminal region.
Pssm-ID: 462303 [Multi-domain] Cd Length: 488 Bit Score: 153.13 E-value: 1.25e-39
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 125 PVEELLTME-----DEGNSDMLVVTTKAGLLELKIEKTMKEKEELLKLIAV------------------LEKETAQLREQ 181
Cdd:pfam07888 2 PLDELVTLEeeshgEEGGTDMLLVVPRAELLQNRLEECLQERAELLQAQEAanrqrekekerykrdreqWERQRRELESR 81
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 182 VGRMERELNHEKERCDQLQAEQKGLTEVTQSLKMENEEFKKRFSDATSKAHQLEEDIVSVTHKAIEKETELDSLKDKLKK 261
Cdd:pfam07888 82 VAELKEELRQSREKHEELEEKYKELSASSEELSEEKDALLAQRAAHEARIRELEEDIKTLTQRVLERETELERMKERAKK 161
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 262 AQHereqlecQLKTEKDEKELYKVHLKNTEIENTKLMSEVQTLKNLDGNKESVITHFKEEIGRLQLCLAEKEnlQRTFLL 341
Cdd:pfam07888 162 AGA-------QRKEEEAERKQLQAKLQQTEEELRSLSKEFQELRNSLAQRDTQVLQLQDTITTLTQKLTTAH--RKEAEN 232
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 342 TTsskedtcfLKEQLRKAEEQVQATRQEVVFLAKELSDAVNVRDRTMADLHTARLENEKVKKQLADAVAELK-------- 413
Cdd:pfam07888 233 EA--------LLEELRSLQERLNASERKVEGLGEELSSMAAQRDRTQAELHQARLQAAQLTLQLADASLALRegrarwaq 304
|
330 340 350 360 370 380
....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 414 -----LNAMKKDQDKTDTLEHELRREVEDL--------KLRLQMAADhykekfKECQRLQ 460
Cdd:pfam07888 305 eretlQQSAEADKDRIEKLSAELQRLEERLqeermereKLEVELGRE------KDCNRVQ 358
|
|
| Smc |
COG1196 |
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; ... |
150-448 |
4.46e-13 |
|
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 440809 [Multi-domain] Cd Length: 983 Bit Score: 73.05 E-value: 4.46e-13
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 150 LELKIEKTMKEKEELLKLIAVLEKETAQLREQVGRMERELNHEKERCDQLQAEQKGLTEVTQSLKMENEEFKKRFSDATS 229
Cdd:COG1196 216 RELKEELKELEAELLLLKLRELEAELEELEAELEELEAELEELEAELAELEAELEELRLELEELELELEEAQAEEYELLA 295
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 230 KAHQLEEDIVSVTHKAIEKETELDSLKDKLKKAQHEREQLECQLKTEKDEKELYKVHLKNTEIENTKLMSEVQTLKNLDG 309
Cdd:COG1196 296 ELARLEQDIARLEERRRELEERLEELEEELAELEEELEELEEELEELEEELEEAEEELEEAEAELAEAEEALLEAEAELA 375
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 310 NKESVITHFKEEIGRLQLCLAEKENLQRTFLLTTSSKEDtcfLKEQLRKAEEQVQATRQEVVFLAKELSDAVNVRDRTMA 389
Cdd:COG1196 376 EAEEELEELAEELLEALRAAAELAAQLEELEEAEEALLE---RLERLEEELEELEEALAELEEEEEEEEEALEEAAEEEA 452
|
250 260 270 280 290
....*....|....*....|....*....|....*....|....*....|....*....
gi 1384071986 390 DLhtaRLENEKVKKQLADAVAELKLnamkkDQDKTDTLEHELRREVEDLKLRLQMAADH 448
Cdd:COG1196 453 EL---EEEEEALLELLAELLEEAAL-----LEAALAELLEELAEAAARLLLLLEAEADY 503
|
|
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
145-466 |
2.38e-12 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 70.86 E-value: 2.38e-12
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 145 TKAGLLELKiektmKEKEELLKLIAVLEKETAQLREQVGRMERELNHEKERCDQLQAEQKGLTEVTQSLKMENEEFKKRF 224
Cdd:TIGR02168 668 TNSSILERR-----REIEELEEKIEELEEKIAELEKALAELRKELEELEEELEQLRKELEELSRQISALRKDLARLEAEV 742
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 225 SDATSKAHQLEEDIVSVTHKAIEKETELDSLKDKLKKAQHEREQLECQLKTEKDEkelykvhLKNTEIENTKLMSEVQTL 304
Cdd:TIGR02168 743 EQLEERIAQLSKELTELEAEIEELEERLEEAEEELAEAEAEIEELEAQIEQLKEE-------LKALREALDELRAELTLL 815
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 305 KNLDGNKESvithfkeeigRLQLCLAEKENLQRTFLLTTSSKEDtcfLKEQLRKAEEQVQATRQEVVFLAKELSDAVNVR 384
Cdd:TIGR02168 816 NEEAANLRE----------RLESLERRIAATERRLEDLEEQIEE---LSEDIESLAAEIEELEELIEELESELEALLNER 882
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 385 DRTMADLHTARLENEKVKKQLADavAELKLNAMKKDQDKTDTLEHELRREVEDLKLR---------------LQMAADHY 449
Cdd:TIGR02168 883 ASLEEALALLRSELEELSEELRE--LESKRSELRRELEELREKLAQLELRLEGLEVRidnlqerlseeysltLEEAEALE 960
|
330
....*....|....*..
gi 1384071986 450 KEKFKECQRLQKQINKL 466
Cdd:TIGR02168 961 NKIEDDEEEARRRLKRL 977
|
|
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
127-412 |
4.52e-12 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 70.09 E-value: 4.52e-12
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 127 EELLTMEDEGNSDMLVVTTKAGLLELKIEKTMKEKEELLKLIAVLEKETAQLREQVGRMERELNHEKERCDQLQAEQKGL 206
Cdd:TIGR02168 242 EELQEELKEAEEELEELTAELQELEEKLEELRLEVSELEEEIEELQKELYALANEISRLEQQKQILRERLANLERQLEEL 321
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 207 TEVTQSLKMENEEFKKRFSDATSKAHQLEEDIVSVTHKAIEKETELDSLKDKLKKAQHERE-------QLECQLKTEKDE 279
Cdd:TIGR02168 322 EAQLEELESKLDELAEELAELEEKLEELKEELESLEAELEELEAELEELESRLEELEEQLEtlrskvaQLELQIASLNNE 401
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 280 KELYKVHLKNTEIENTKLMSEVQTLknldgNKESVITHFKEEIGRLQLCLAEKENLQRTFLLTTSSKEDtcfLKEQLRKA 359
Cdd:TIGR02168 402 IERLEARLERLEDRRERLQQEIEEL-----LKKLEEAELKELQAELEELEEELEELQEELERLEEALEE---LREELEEA 473
|
250 260 270 280 290
....*....|....*....|....*....|....*....|....*....|...
gi 1384071986 360 EEQVQATRQEVVFLAKELsDAVNVRDRTMADLHTARLENEKVKKQLADAVAEL 412
Cdd:TIGR02168 474 EQALDAAERELAQLQARL-DSLERLQENLEGFSEGVKALLKNQSGLSGILGVL 525
|
|
| Zn-C2H2_12 |
pfam18112 |
Autophagy receptor zinc finger-C2H2 domain; This domain is found in calcium-binding and ... |
718-744 |
1.52e-11 |
|
Autophagy receptor zinc finger-C2H2 domain; This domain is found in calcium-binding and coiled-coil domain 2/NDP25 (CALCOCO2/NDP25) found in Homo sapiens. CALCOCO2/NDP25 is an ubiquitin-binding autophagy receptor involved in the selective autophagic degradation of invading pathogens. This domain is a typical C2H2-type zinc finger which specifically recognizes mono-ubiquitin or poly-ubiquitin chain. The overall ubiquitin-binding mode utilizes the C-terminal alpha-helix to interact with the solvent-exposed surface of the central beta-sheet of ubiquitin, similar to that observed in the RABGEF1/Rabex-5 or POLN/Pol-eta zinc finger.
Pssm-ID: 407946 Cd Length: 27 Bit Score: 59.20 E-value: 1.52e-11
10 20
....*....|....*....|....*..
gi 1384071986 718 KKCPLCELMFPPNYDQSKFEEHVESHW 744
Cdd:pfam18112 1 KECPLCGEMFSPNIDQSEFEEHVESHF 27
|
|
| Zn-C2H2_TAX1BP1_rpt2 |
cd21970 |
second C2H2-type zinc binding domain found in tax1-binding protein 1 (TAX1BP1) and similar ... |
745-771 |
1.88e-11 |
|
second C2H2-type zinc binding domain found in tax1-binding protein 1 (TAX1BP1) and similar proteins; TAX1BP1, also called TRAF6-binding protein (T6BP), is a novel ubiquitin-binding adaptor protein involved in the negative regulation of the NF-kappaB transcription factor, a key player in inflammatory responses, immunity and tumorigenesis. It inhibits TNF-induced apoptosis by mediating the TNFAIP3 anti-apoptotic activity. It may also play a role in the pro-inflammatory cytokine IL-1 signaling cascade. TAX1BP1 is degraded by caspase-3-like family proteins upon TNF-induced apoptosis. TAX1BP1 contains two C2H2-type zinc binding domains; this model corresponds to the second one.
Pssm-ID: 412016 Cd Length: 27 Bit Score: 59.11 E-value: 1.88e-11
10 20
....*....|....*....|....*..
gi 1384071986 745 KVCPMCSEQFPPDYDQQVFERHVQTHF 771
Cdd:cd21970 1 KVCPMCSEQFPPDCDQQVFERHVQTHF 27
|
|
| Zn-C2H2_TAX1BP1_rpt1 |
cd21969 |
first C2H2-type zinc binding domain found in tax1-binding protein 1 (TAX1BP1) and similar ... |
720-743 |
5.61e-11 |
|
first C2H2-type zinc binding domain found in tax1-binding protein 1 (TAX1BP1) and similar proteins; TAX1BP1, also called TRAF6-binding protein (T6BP), is a novel ubiquitin-binding adaptor protein involved in the negative regulation of the NF-kappaB transcription factor, a key player in inflammatory responses, immunity and tumorigenesis. It inhibits TNF-induced apoptosis by mediating the TNFAIP3 anti-apoptotic activity. It may also play a role in the pro-inflammatory cytokine IL-1 signaling cascade. TAX1BP1 is degraded by caspase-3-like family proteins upon TNF-induced apoptosis. TAX1BP1 contains two C2H2-type zinc binding domains; this model corresponds to the first one.
Pssm-ID: 412015 Cd Length: 24 Bit Score: 57.43 E-value: 5.61e-11
|
| SMC_prok_A |
TIGR02169 |
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ... |
153-469 |
1.70e-10 |
|
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 64.70 E-value: 1.70e-10
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 153 KIEKTMKEKEELLKLIAVLEKETAQLREQVGRMERELNHeKERCDQLQAEqKGLTEVTQSLKmENEEFKKRFSDATSKAH 232
Cdd:TIGR02169 171 KKEKALEELEEVEENIERLDLIIDEKRQQLERLRREREK-AERYQALLKE-KREYEGYELLK-EKEALERQKEAIERQLA 247
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 233 QLEEDIVSVTHKAIEKETELDSLKDKLK------KAQHEREQLECQLKTEKDEKELYK----VHLKNTEIEntKLMSEVQ 302
Cdd:TIGR02169 248 SLEEELEKLTEEISELEKRLEEIEQLLEelnkkiKDLGEEEQLRVKEKIGELEAEIASlersIAEKERELE--DAEERLA 325
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 303 TLKNLDGNKESVITHFKEEIGRLQlclAEKENLQRTFlltTSSKEDTCFLKEQLRKAEEQVQATRQEVVFLAKELSDAVN 382
Cdd:TIGR02169 326 KLEAEIDKLLAEIEELEREIEEER---KRRDKLTEEY---AELKEELEDLRAELEEVDKEFAETRDELKDYREKLEKLKR 399
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 383 VRDRTMADLhtARLENEKVKKQLADAVAELKLNAMKKDQDKTDTLEHELRREVEDLKLRLQMAADHYKEKFKECQRLQKQ 462
Cdd:TIGR02169 400 EINELKREL--DRLQEELQRLSEELADLNAAIAGIEAKINELEEEKEDKALEIKKQEWKLEQLAADLSKYEQELYDLKEE 477
|
....*..
gi 1384071986 463 INKLSDQ 469
Cdd:TIGR02169 478 YDRVEKE 484
|
|
| Smc |
COG1196 |
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; ... |
127-416 |
3.00e-10 |
|
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 440809 [Multi-domain] Cd Length: 983 Bit Score: 63.80 E-value: 3.00e-10
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 127 EELLTMEDEGNSDMLVVTTKAGLLELKIEKTMKEKEELLKLIAVLEKETAQLREQVGRMERELNHEKERCDQLQAEQKGL 206
Cdd:COG1196 242 EELEAELEELEAELEELEAELAELEAELEELRLELEELELELEEAQAEEYELLAELARLEQDIARLEERRRELEERLEEL 321
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 207 TEVTQSLKMENEEFKKRFSDATSKAHQLEEDIVSVTHKAIEKETELDSLKDKLKKAQHEREQLECQLKTEKDEKELYKVH 286
Cdd:COG1196 322 EEELAELEEELEELEEELEELEEELEEAEEELEEAEAELAEAEEALLEAEAELAEAEEELEELAEELLEALRAAAELAAQ 401
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 287 LKNTEIENTKLMSEVQTLKNLDGNKESVITHFKEEIGRLQLCLAEKENLQRTfllttsskedtcfLKEQLRKAEEQVQAT 366
Cdd:COG1196 402 LEELEEAEEALLERLERLEEELEELEEALAELEEEEEEEEEALEEAAEEEAE-------------LEEEEEALLELLAEL 468
|
250 260 270 280 290
....*....|....*....|....*....|....*....|....*....|
gi 1384071986 367 RQEVVFLAKELSDAVNVRDRtMADLHTARLENEKVKKQLADAVAELKLNA 416
Cdd:COG1196 469 LEEAALLEAALAELLEELAE-AAARLLLLLEAEADYEGFLEGVKAALLLA 517
|
|
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
121-412 |
3.10e-10 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 63.92 E-value: 3.10e-10
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 121 RASSPVEELLTMEDEGNSDMLVVTTKAGLLELKIEKTMKEKEELLKLIAVLEKETAQLREQVGRMERELNHEKERCDQLQ 200
Cdd:TIGR02168 737 RLEAEVEQLEERIAQLSKELTELEAEIEELEERLEEAEEELAEAEAEIEELEAQIEQLKEELKALREALDELRAELTLLN 816
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 201 AEQKGLTEVTQSLKMENEEFKKRFSDATSKAHQLEEDIVSVTHKAIEKETELDSLKDKLKKAQHEREQLECQLKTEKDEK 280
Cdd:TIGR02168 817 EEAANLRERLESLERRIAATERRLEDLEEQIEELSEDIESLAAEIEELEELIEELESELEALLNERASLEEALALLRSEL 896
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 281 ELYKVHLKNTEIENTKLMSEVQTLKNLDGNKESVITHFKEEIGRLQLCLAEKENLQRTFLLTTSSKEDTCF--LKEQLRK 358
Cdd:TIGR02168 897 EELSEELRELESKRSELRRELEELREKLAQLELRLEGLEVRIDNLQERLSEEYSLTLEEAEALENKIEDDEeeARRRLKR 976
|
250 260 270 280 290
....*....|....*....|....*....|....*....|....*....|....*...
gi 1384071986 359 AEEQVQATrQEVVFLAKELSDAVNVR----DRTMADLHTARlenekvkKQLADAVAEL 412
Cdd:TIGR02168 977 LENKIKEL-GPVNLAAIEEYEELKERydflTAQKEDLTEAK-------ETLEEAIEEI 1026
|
|
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
150-488 |
6.79e-10 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 62.77 E-value: 6.79e-10
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 150 LELKIEKTMK------EKEELLKLIAVLEKEtaQLREQVGRMERELNHEKERCDQLQAEQKGLTEVTQSLKMENEEFKKR 223
Cdd:TIGR02168 205 LERQAEKAERykelkaELRELELALLVLRLE--ELREELEELQEELKEAEEELEELTAELQELEEKLEELRLEVSELEEE 282
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 224 FSDATSKAHQLEEDIVSVTHKAIEKETELDSLKDKLKKAQHEREQLECQLKTEKDEKELYKVHLKNTEIENTKLMSEVQT 303
Cdd:TIGR02168 283 IEELQKELYALANEISRLEQQKQILRERLANLERQLEELEAQLEELESKLDELAEELAELEEKLEELKEELESLEAELEE 362
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 304 LKNLDGNKESVITHFKEEIGRLqlclaekenlqrtfllttsskedtcflKEQLRKAEEQVQATRQEVVFLAKELSDAVNV 383
Cdd:TIGR02168 363 LEAELEELESRLEELEEQLETL---------------------------RSKVAQLELQIASLNNEIERLEARLERLEDR 415
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 384 RDRTMADlhtarlenekvKKQLADAVAELKLNAMKKDQDKTDTLEHELRREVEDLKLRLQMAADHYKEKFKECQRLQKQI 463
Cdd:TIGR02168 416 RERLQQE-----------IEELLKKLEEAELKELQAELEELEEELEELQEELERLEEALEELREELEEAEQALDAAEREL 484
|
330 340
....*....|....*....|....*
gi 1384071986 464 NKLSDQSANNNNVFTKKTGNQQKVN 488
Cdd:TIGR02168 485 AQLQARLDSLERLQENLEGFSEGVK 509
|
|
| SMC_prok_A |
TIGR02169 |
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ... |
171-468 |
7.69e-10 |
|
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 62.78 E-value: 7.69e-10
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 171 LEKETAQLREQVGRMERELNhekercdQLQAEQKGLTEVTQSLKMENEEFKKRFSDATSKAHQLEEDIVSVTHKAIEKET 250
Cdd:TIGR02169 672 EPAELQRLRERLEGLKRELS-------SLQSELRRIENRLDELSQELSDASRKIGEIEKEIEQLEQEEEKLKERLEELEE 744
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 251 ELDSLKDKLKKAQHEREQLECQLktEKDEKELYKVHLKNTEIENTKLMSEVQTLKNL--DGNK-----ESVITHFKEEIG 323
Cdd:TIGR02169 745 DLSSLEQEIENVKSELKELEARI--EELEEDLHKLEEALNDLEARLSHSRIPEIQAElsKLEEevsriEARLREIEQKLN 822
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 324 RLQLCLA----EKENLQRTFLLTTSSKEDTC----FLKEQLRKAEEQVQATRQEVVFLAKELSDAVNVRDRtmadlHTAR 395
Cdd:TIGR02169 823 RLTLEKEylekEIQELQEQRIDLKEQIKSIEkeieNLNGKKEELEEELEELEAALRDLESRLGDLKKERDE-----LEAQ 897
|
250 260 270 280 290 300 310
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*.
gi 1384071986 396 LENEKVKKQLADAVAELKLNAMKKDQDKTDTLEHELrREVEDLKLRLQ--MAADHYKEKFK-ECQRLQKQINKLSD 468
Cdd:TIGR02169 898 LRELERKIEELEAQIEKKRKRLSELKAKLEALEEEL-SEIEDPKGEDEeiPEEELSLEDVQaELQRVEEEIRALEP 972
|
|
| SMC_prok_A |
TIGR02169 |
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ... |
151-443 |
1.87e-09 |
|
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 61.62 E-value: 1.87e-09
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 151 ELKIEKTMKEKEELLKLIAVLEKETAQLREQVGRMERELNHEKERCDQLQAEqkgLTEVTQSLKMENEEFKKRFSDatsK 230
Cdd:TIGR02169 215 ALLKEKREYEGYELLKEKEALERQKEAIERQLASLEEELEKLTEEISELEKR---LEEIEQLLEELNKKIKDLGEE---E 288
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 231 AHQLEEDIVSVTHKAIEKETELDSLKDKLKKAQHEREQLECQLKTEKDEKELYKVHLKNTEIENTKLMSEVQTLKN---- 306
Cdd:TIGR02169 289 QLRVKEKIGELEAEIASLERSIAEKERELEDAEERLAKLEAEIDKLLAEIEELEREIEEERKRRDKLTEEYAELKEeled 368
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 307 LDGNKESVITHFKEEIGRLQLCLAEKENLQRTFlltTSSKEDTCFLKEQLRKAEEQVQATRQEVVFLAKELSDAVNVRDR 386
Cdd:TIGR02169 369 LRAELEEVDKEFAETRDELKDYREKLEKLKREI---NELKRELDRLQEELQRLSEELADLNAAIAGIEAKINELEEEKED 445
|
250 260 270 280 290
....*....|....*....|....*....|....*....|....*....|....*..
gi 1384071986 387 TMADLHTARLENEKVKKQLADavAELKLNAMKKDQDKTDTLEHELRREVEDLKLRLQ 443
Cdd:TIGR02169 446 KALEIKKQEWKLEQLAADLSK--YEQELYDLKEEYDRVEKELSKLQRELAEAEAQAR 500
|
|
| PRK03918 |
PRK03918 |
DNA double-strand break repair ATPase Rad50; |
145-603 |
4.80e-09 |
|
DNA double-strand break repair ATPase Rad50;
Pssm-ID: 235175 [Multi-domain] Cd Length: 880 Bit Score: 60.08 E-value: 4.80e-09
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 145 TKAGLLELKIEKTMKEKEELLK----LIAVLEKETAQLREQVGRMErELNHEKERCDQLQAEQKGLTEVTQslkmeneEF 220
Cdd:PRK03918 241 EELEKELESLEGSKRKLEEKIReleeRIEELKKEIEELEEKVKELK-ELKEKAEEYIKLSEFYEEYLDELR-------EI 312
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 221 KKRFSDATSKAHQLEEDIvsvtHKAIEKETELDSLKDKLKKAQHEREQLECQLKT-----------------------EK 277
Cdd:PRK03918 313 EKRLSRLEEEINGIEERI----KELEEKEERLEELKKKLKELEKRLEELEERHELyeeakakkeelerlkkrltgltpEK 388
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 278 DEKELYKVHLKNTEIEN--TKLMSEVQTLKNLDGNKESVITHFKEEIGRLQLCLAEKENLQRTFLLTTSSKEDTCFLKEq 355
Cdd:PRK03918 389 LEKELEELEKAKEEIEEeiSKITARIGELKKEIKELKKAIEELKKAKGKCPVCGRELTEEHRKELLEEYTAELKRIEKE- 467
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 356 LRKAEEQVQATRQEVVFLAKELSDAVNV-RDRTMAD----------------LHTARLENEKVKKQLADAVAEL------ 412
Cdd:PRK03918 468 LKEIEEKERKLRKELRELEKVLKKESELiKLKELAEqlkeleeklkkynleeLEKKAEEYEKLKEKLIKLKGEIkslkke 547
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 413 --KLNAMKKD-----------QDKTDTLEHELRRE----VEDLKLRLQMAADHYKEKF------KECQRLQKQI----NK 465
Cdd:PRK03918 548 leKLEELKKKlaelekkldelEEELAELLKELEELgfesVEELEERLKELEPFYNEYLelkdaeKELEREEKELkkleEE 627
|
410 420 430 440 450 460 470 480
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 466 LSDQSANNNNVFTKKTGNQQKVNDASVNTDPATSAStvdvkpspsaaeadfdivTKGQVCEMTKEIADKTEKYNKCKQLL 545
Cdd:PRK03918 628 LDKAFEELAETEKRLEELRKELEELEKKYSEEEYEE------------------LREEYLELSRELAGLRAELEELEKRR 689
|
490 500 510 520 530
....*....|....*....|....*....|....*....|....*....|....*...
gi 1384071986 546 QDEKAKCNKYADELAKMElKWKEQVKIAENVKLELAEVQDNYKELKRSLENPAERKME 603
Cdd:PRK03918 690 EEIKKTLEKLKEELEERE-KAKKELEKLEKALERVEELREKVKKYKALLKERALSKVG 746
|
|
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
146-413 |
7.25e-09 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 59.69 E-value: 7.25e-09
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 146 KAGLLELKIEKTMKEKEELLKLIAVLEKE----TAQLR---EQVGRMERELNHEKERCDQLQAEQKGLTEVTQSLKMENE 218
Cdd:TIGR02168 226 ELALLVLRLEELREELEELQEELKEAEEEleelTAELQeleEKLEELRLEVSELEEEIEELQKELYALANEISRLEQQKQ 305
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 219 EFKKRFSDATSKAHQLEEDIVSVTHKAIEKETELDSLKDKLKKAQHEREQLECQLKTEKDEKELYKVHLKNTEIENTKLM 298
Cdd:TIGR02168 306 ILRERLANLERQLEELEAQLEELESKLDELAEELAELEEKLEELKEELESLEAELEELEAELEELESRLEELEEQLETLR 385
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 299 SEVQTLKnldgNKESVIThfkeeiGRLQLCLAEKENLQRTFLLTTSSKEdtcflkEQLRKAEE-QVQATRQEVVFLAKEL 377
Cdd:TIGR02168 386 SKVAQLE----LQIASLN------NEIERLEARLERLEDRRERLQQEIE------ELLKKLEEaELKELQAELEELEEEL 449
|
250 260 270
....*....|....*....|....*....|....*.
gi 1384071986 378 SDAVNVRDRTMADLHTARLENEKVKKQLADAVAELK 413
Cdd:TIGR02168 450 EELQEELERLEEALEELREELEEAEQALDAAERELA 485
|
|
| Zn-C2H2_12 |
pfam18112 |
Autophagy receptor zinc finger-C2H2 domain; This domain is found in calcium-binding and ... |
745-771 |
1.39e-08 |
|
Autophagy receptor zinc finger-C2H2 domain; This domain is found in calcium-binding and coiled-coil domain 2/NDP25 (CALCOCO2/NDP25) found in Homo sapiens. CALCOCO2/NDP25 is an ubiquitin-binding autophagy receptor involved in the selective autophagic degradation of invading pathogens. This domain is a typical C2H2-type zinc finger which specifically recognizes mono-ubiquitin or poly-ubiquitin chain. The overall ubiquitin-binding mode utilizes the C-terminal alpha-helix to interact with the solvent-exposed surface of the central beta-sheet of ubiquitin, similar to that observed in the RABGEF1/Rabex-5 or POLN/Pol-eta zinc finger.
Pssm-ID: 407946 Cd Length: 27 Bit Score: 50.72 E-value: 1.39e-08
10 20
....*....|....*....|....*..
gi 1384071986 745 KVCPMCSEQFPPDYDQQVFERHVQTHF 771
Cdd:pfam18112 1 KECPLCGEMFSPNIDQSEFEEHVESHF 27
|
|
| SMC_prok_A |
TIGR02169 |
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ... |
229-475 |
2.22e-08 |
|
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 57.77 E-value: 2.22e-08
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 229 SKAHQLEEDIVSVTHKAIEKETELDSLKDKLKKAQHEREQLE--CQLKTEKDEKELYkVHLKNTEIENTKLmseVQTLKN 306
Cdd:TIGR02169 170 RKKEKALEELEEVEENIERLDLIIDEKRQQLERLRREREKAEryQALLKEKREYEGY-ELLKEKEALERQK---EAIERQ 245
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 307 LDGnKESVITHFKEEIGRLQLCLAEKENLQRTFLLTTSSK--EDTCFLKEQLRKAEEQVQATRQEVVFLAKELSDAVNVR 384
Cdd:TIGR02169 246 LAS-LEEELEKLTEEISELEKRLEEIEQLLEELNKKIKDLgeEEQLRVKEKIGELEAEIASLERSIAEKERELEDAEERL 324
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 385 DRTMADLHTARLENEKVKKQLADAVAELK--LNAMKKDQDKTDTLEHEL----------RREVEDLKLRLQMAADHYKEK 452
Cdd:TIGR02169 325 AKLEAEIDKLLAEIEELEREIEEERKRRDklTEEYAELKEELEDLRAELeevdkefaetRDELKDYREKLEKLKREINEL 404
|
250 260
....*....|....*....|...
gi 1384071986 453 FKECQRLQKQINKLSDQSANNNN 475
Cdd:TIGR02169 405 KRELDRLQEELQRLSEELADLNA 427
|
|
| Zn-C2H2_CALCOCO1_TAX1BP1_like |
cd21965 |
autophagy receptor zinc finger-C2H2 domain found in calcium-binding and coiled-coil ... |
747-770 |
2.36e-08 |
|
autophagy receptor zinc finger-C2H2 domain found in calcium-binding and coiled-coil domain-containing proteins, TAX1BP1 and similar proteins; The family includes calcium-binding and coiled-coil domain-containing proteins (CALCOCO1 and CALCOCO2), TAX1BP1 and similar proteins. CALCOCO1, also called calphoglin, or coiled-coil coactivator protein, or Sarcoma antigen NY-SAR-3, functions as a coactivator for aryl hydrocarbon and nuclear receptors (NR). CALCOCO2, also called antigen nuclear dot 52 kDa protein, or nuclear domain 10 protein NDP52, or nuclear domain 10 protein 52, or nuclear dot protein 52, is an ubiquitin-binding autophagy receptor involved in the selective autophagic degradation of invading pathogens. TAX1BP1, also called TRAF6-binding protein (T6BP), is a novel ubiquitin-binding adaptor protein involved in the negative regulation of the NF-kappaB transcription factor, a key player in inflammatory responses, immunity and tumorigenesis. The family also includes Drosophila melanogaster Spindle-F (Spn-F) that is the central mediator of IK2 kinase-dependent dendrite pruning in drosophila sensory neurons. This model corresponds to the C2H2-type zinc binding domain found in family members. It is a typical C2H2-type zinc finger which specifically recognizes mono-ubiquitin or poly-ubiquitin chain. The overall ubiquitin-binding mode utilizes the C-terminal alpha-helix to interact with the solvent-exposed surface of the central beta-sheet of ubiquitin, similar to that observed in the RABGEF1/Rabex-5 or POLN/Pol-eta zinc finger.
Pssm-ID: 412012 Cd Length: 24 Bit Score: 50.26 E-value: 2.36e-08
|
| SCP-1 |
pfam05483 |
Synaptonemal complex protein 1 (SCP-1); Synaptonemal complex protein 1 (SCP-1) is the major ... |
155-589 |
2.64e-08 |
|
Synaptonemal complex protein 1 (SCP-1); Synaptonemal complex protein 1 (SCP-1) is the major component of the transverse filaments of the synaptonemal complex. Synaptonemal complexes are structures that are formed between homologous chromosomes during meiotic prophase.
Pssm-ID: 114219 [Multi-domain] Cd Length: 787 Bit Score: 57.42 E-value: 2.64e-08
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 155 EKTMKEKEELLKLIAVLEKETAQLREQVGRMERELNHEKERCDQLQAEQKGLTEVTQSLKMENEEFKKrfsdaTSKAHQL 234
Cdd:pfam05483 275 EKTKLQDENLKELIEKKDHLTKELEDIKMSLQRSMSTQKALEEDLQIATKTICQLTEEKEAQMEELNK-----AKAAHSF 349
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 235 eedIVSvthkaiEKETELDSLKDKLKKAQHEREQLECQLKTekdekelykvhlknTEIENTKLMSEVQTLKNLDGNKESv 314
Cdd:pfam05483 350 ---VVT------EFEATTCSLEELLRTEQQRLEKNEDQLKI--------------ITMELQKKSSELEEMTKFKNNKEV- 405
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 315 ithfkeEIGRLQLCLAEKENLqrtfllttsskedtCFLKEQLRKAEEQVQATRQEVVFL----AKELSD-AVNVRDRTMA 389
Cdd:pfam05483 406 ------ELEELKKILAEDEKL--------------LDEKKQFEKIAEELKGKEQELIFLlqarEKEIHDlEIQLTAIKTS 465
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 390 DLHTARlENEKVKKQLADavAELKLNAMKKDQDKTDTLEHELRREVEDLKLRLQMAADHYKEKFKECQRLQKQINKLSDQ 469
Cdd:pfam05483 466 EEHYLK-EVEDLKTELEK--EKLKNIELTAHCDKLLLENKELTQEASDMTLELKKHQEDIINCKKQEERMLKQIENLEEK 542
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 470 SANNNNVFT------KKTGNQQKVNDASVNTDPATSASTVDVKPSPSAAEADFDIVTKGQVCEMTKEIADKTEKYNKCKQ 543
Cdd:pfam05483 543 EMNLRDELEsvreefIQKGDEVKCKLDKSEENARSIEYEVLKKEKQMKILENKCNNLKKQIENKNKNIEELHQENKALKK 622
|
410 420 430 440
....*....|....*....|....*....|....*....|....*.
gi 1384071986 544 LLQDEKAKCNKYADELAKMELKwkeqvkiAENVKLELAEVQDNYKE 589
Cdd:pfam05483 623 KGSAENKQLNAYEIKVNKLELE-------LASAKQKFEEIIDNYQK 661
|
|
| Zn-C2H2_TAX1BP1_rpt1 |
cd21969 |
first C2H2-type zinc binding domain found in tax1-binding protein 1 (TAX1BP1) and similar ... |
747-770 |
5.94e-08 |
|
first C2H2-type zinc binding domain found in tax1-binding protein 1 (TAX1BP1) and similar proteins; TAX1BP1, also called TRAF6-binding protein (T6BP), is a novel ubiquitin-binding adaptor protein involved in the negative regulation of the NF-kappaB transcription factor, a key player in inflammatory responses, immunity and tumorigenesis. It inhibits TNF-induced apoptosis by mediating the TNFAIP3 anti-apoptotic activity. It may also play a role in the pro-inflammatory cytokine IL-1 signaling cascade. TAX1BP1 is degraded by caspase-3-like family proteins upon TNF-induced apoptosis. TAX1BP1 contains two C2H2-type zinc binding domains; this model corresponds to the first one.
Pssm-ID: 412015 Cd Length: 24 Bit Score: 48.95 E-value: 5.94e-08
|
| SMC_N |
pfam02463 |
RecF/RecN/SMC N terminal domain; This domain is found at the N terminus of SMC proteins. The ... |
149-475 |
1.06e-07 |
|
RecF/RecN/SMC N terminal domain; This domain is found at the N terminus of SMC proteins. The SMC (structural maintenance of chromosomes) superfamily proteins have ATP-binding domains at the N- and C-termini, and two extended coiled-coil domains separated by a hinge in the middle. The eukaryotic SMC proteins form two kind of heterodimers: the SMC1/SMC3 and the SMC2/SMC4 types. These heterodimers constitute an essential part of higher order complexes, which are involved in chromatin and DNA dynamics. This family also includes the RecF and RecN proteins that are involved in DNA metabolism and recombination.
Pssm-ID: 426784 [Multi-domain] Cd Length: 1161 Bit Score: 55.75 E-value: 1.06e-07
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 149 LLELKIEKTMKEKEELLKLIAVLEKETAQLREQVGRMERELNHEKERCDQLQAEQkgltevtQSLKMENEEFKKRFSDAT 228
Cdd:pfam02463 192 LEELKLQELKLKEQAKKALEYYQLKEKLELEEEYLLYLDYLKLNEERIDLLQELL-------RDEQEEIESSKQEIEKEE 264
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 229 SKAHQLEEDIVSVTHKAIEKETELDSLKDKLKKAQHEREQLECQLKTEKDEKELYKVHLKNTEIENTKLMSEVQTLKNLD 308
Cdd:pfam02463 265 EKLAQVLKENKEEEKEKKLQEEELKLLAKEEEELKSELLKLERRKVDDEEKLKESEKEKKKAEKELKKEKEEIEELEKEL 344
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 309 GNKESVITHFKEEIGRLQLCLAEKENLQRTFLltTSSKEDTCFLKEQLRKAEEQ------VQATRQEVVFLAKELSDAVN 382
Cdd:pfam02463 345 KELEIKREAEEEEEEELEKLQEKLEQLEEELL--AKKKLESERLSSAAKLKEEElelkseEEKEAQLLLELARQLEDLLK 422
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 383 VRDRTMadlhtARLENEKVKKQLADAVAELKLNAMKKDQDKTDTLEHELRREVEDLKLRLQMAADHYKEKfKECQRLQKQ 462
Cdd:pfam02463 423 EEKKEE-----LEILEEEEESIELKQGKLTEEKEELEKQELKLLKDELELKKSEDLLKETQLVKLQEQLE-LLLSRQKLE 496
|
330
....*....|...
gi 1384071986 463 INKLSDQSANNNN 475
Cdd:pfam02463 497 ERSQKESKARSGL 509
|
|
| Mplasa_alph_rch |
TIGR04523 |
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of ... |
153-590 |
1.12e-07 |
|
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of Mycoplasma species. Members average 750 amino acids in length, including signal peptide. Sequences are predicted (Jpred 3) to be almost entirely alpha-helical. These sequences show strong periodicity (consistent with long alpha helical structures) and low complexity rich in D,E,N,Q, and K. Genes encoding these proteins are often found in tandem. The function is unknown.
Pssm-ID: 275316 [Multi-domain] Cd Length: 745 Bit Score: 55.41 E-value: 1.12e-07
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 153 KIEKTMKEKEELL----KLIAVLEKETAQLREQVgrmeRELNHEKErcdqlQAEQKGLTEVTQSLKMENEEFKKRFSDAT 228
Cdd:TIGR04523 264 KIKKQLSEKQKELeqnnKKIKELEKQLNQLKSEI----SDLNNQKE-----QDWNKELKSELKNQEKKLEEIQNQISQNN 334
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 229 SKAHQLEEDIVSVTHKAIEKETELDSLKDKLKKAQHEreqlecqLKTEKDEKELYKVHLKNTEIENTKLMSEVQTLKNLD 308
Cdd:TIGR04523 335 KIISQLNEQISQLKKELTNSESENSEKQRELEEKQNE-------IEKLKKENQSYKQEIKNLESQINDLESKIQNQEKLN 407
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 309 GNKESVITHFKEEigrLQLCLAEKENLqrtfllttssKEDTCFLKEQLRKAEEQVQATRQEVVFLAKELSDAVNVRDRTM 388
Cdd:TIGR04523 408 QQKDEQIKKLQQE---KELLEKEIERL----------KETIIKNNSEIKDLTNQDSVKELIIKNLDNTRESLETQLKVLS 474
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 389 ADLHTARLENEKVKKQLADAVAELK-LNAMKKDQDKTDTlehELRREVEDLKLRLQMAADHYKEKFKECQRLQKQINKLs 467
Cdd:TIGR04523 475 RSINKIKQNLEQKQKELKSKEKELKkLNEEKKELEEKVK---DLTKKISSLKEKIEKLESEKKEKESKISDLEDELNKD- 550
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 468 DQSANNNNVFTKKTGNQQKVNDASVNTDpatsastvDVKPSPSAAEADFDIVTKgQVCEMTKEIADKTEKYNKCKQLLQD 547
Cdd:TIGR04523 551 DFELKKENLEKEIDEKNKEIEELKQTQK--------SLKKKQEEKQELIDQKEK-EKKDLIKEIEEKEKKISSLEKELEK 621
|
410 420 430 440
....*....|....*....|....*....|....*....|...
gi 1384071986 548 EKAKCNKYADELAKMELKWKEQVKIAENVKLELAEVQDNYKEL 590
Cdd:TIGR04523 622 AKKENEKLSSIIKNIKSKKNKLKQEVKQIKETIKEIRNKWPEI 664
|
|
| SMC_N |
pfam02463 |
RecF/RecN/SMC N terminal domain; This domain is found at the N terminus of SMC proteins. The ... |
158-470 |
1.36e-07 |
|
RecF/RecN/SMC N terminal domain; This domain is found at the N terminus of SMC proteins. The SMC (structural maintenance of chromosomes) superfamily proteins have ATP-binding domains at the N- and C-termini, and two extended coiled-coil domains separated by a hinge in the middle. The eukaryotic SMC proteins form two kind of heterodimers: the SMC1/SMC3 and the SMC2/SMC4 types. These heterodimers constitute an essential part of higher order complexes, which are involved in chromatin and DNA dynamics. This family also includes the RecF and RecN proteins that are involved in DNA metabolism and recombination.
Pssm-ID: 426784 [Multi-domain] Cd Length: 1161 Bit Score: 55.36 E-value: 1.36e-07
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 158 MKEKEELLKLIAVLEKETAQLREQVGRMERELNHEKERCDQLQAEQKGLTEVtqsLKMENEEFKKRFSDATSKAHQLEEd 237
Cdd:pfam02463 169 RKKKEALKKLIEETENLAELIIDLEELKLQELKLKEQAKKALEYYQLKEKLE---LEEEYLLYLDYLKLNEERIDLLQE- 244
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 238 ivsvthKAIEKETELDSLKDKLKKAQHEREQLECQLKTEKDEKELYKVHLKNTEIENTKLMSEVQTLKNLDGNKESVITH 317
Cdd:pfam02463 245 ------LLRDEQEEIESSKQEIEKEEEKLAQVLKENKEEEKEKKLQEEELKLLAKEEEELKSELLKLERRKVDDEEKLKE 318
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 318 FKEEIGRLQlclaekenlqrtfLLTTSSKEDTCFLKEQLRKAEEQVQATRQEVVFLAKELSDAVNVRDRTMA--DLHTAR 395
Cdd:pfam02463 319 SEKEKKKAE-------------KELKKEKEEIEELEKELKELEIKREAEEEEEEELEKLQEKLEQLEEELLAkkKLESER 385
|
250 260 270 280 290 300 310
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*
gi 1384071986 396 LENEKVKKQLADAVAELKLNAMKKDQDKTDTLEHELRREVEDLKLRLQMaadhyKEKFKECQRLQKQINKLSDQS 470
Cdd:pfam02463 386 LSSAAKLKEEELELKSEEEKEAQLLLELARQLEDLLKEEKKEELEILEE-----EEESIELKQGKLTEEKEELEK 455
|
|
| Zn-C2H2_CALCOCO1_TAX1BP1_like |
cd21965 |
autophagy receptor zinc finger-C2H2 domain found in calcium-binding and coiled-coil ... |
720-743 |
1.48e-07 |
|
autophagy receptor zinc finger-C2H2 domain found in calcium-binding and coiled-coil domain-containing proteins, TAX1BP1 and similar proteins; The family includes calcium-binding and coiled-coil domain-containing proteins (CALCOCO1 and CALCOCO2), TAX1BP1 and similar proteins. CALCOCO1, also called calphoglin, or coiled-coil coactivator protein, or Sarcoma antigen NY-SAR-3, functions as a coactivator for aryl hydrocarbon and nuclear receptors (NR). CALCOCO2, also called antigen nuclear dot 52 kDa protein, or nuclear domain 10 protein NDP52, or nuclear domain 10 protein 52, or nuclear dot protein 52, is an ubiquitin-binding autophagy receptor involved in the selective autophagic degradation of invading pathogens. TAX1BP1, also called TRAF6-binding protein (T6BP), is a novel ubiquitin-binding adaptor protein involved in the negative regulation of the NF-kappaB transcription factor, a key player in inflammatory responses, immunity and tumorigenesis. The family also includes Drosophila melanogaster Spindle-F (Spn-F) that is the central mediator of IK2 kinase-dependent dendrite pruning in drosophila sensory neurons. This model corresponds to the C2H2-type zinc binding domain found in family members. It is a typical C2H2-type zinc finger which specifically recognizes mono-ubiquitin or poly-ubiquitin chain. The overall ubiquitin-binding mode utilizes the C-terminal alpha-helix to interact with the solvent-exposed surface of the central beta-sheet of ubiquitin, similar to that observed in the RABGEF1/Rabex-5 or POLN/Pol-eta zinc finger.
Pssm-ID: 412012 Cd Length: 24 Bit Score: 47.95 E-value: 1.48e-07
|
| EnvC |
COG4942 |
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, ... |
197-413 |
1.61e-07 |
|
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 443969 [Multi-domain] Cd Length: 377 Bit Score: 54.38 E-value: 1.61e-07
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 197 DQLQAEQKGLTEVTQSLKMENEEFKKRFSDATSKAHQLEEDIVSVTHKAIEKETELDSLKDKLKKAQHEREQLECQLKTE 276
Cdd:COG4942 23 AEAEAELEQLQQEIAELEKELAALKKEEKALLKQLAALERRIAALARRIRALEQELAALEAELAELEKEIAELRAELEAQ 102
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 277 KDE-KELYKVHLKNTEIENTKLM----SEVQTLKNLDGNKeSVITHFKEEIGRLQlclAEKENLQRtfllttsskedtcf 351
Cdd:COG4942 103 KEElAELLRALYRLGRQPPLALLlspeDFLDAVRRLQYLK-YLAPARREQAEELR---ADLAELAA-------------- 164
|
170 180 190 200 210 220
....*....|....*....|....*....|....*....|....*....|....*....|..
gi 1384071986 352 LKEQLRKAEEQVQATRQEVVFLAKELSDAVNVRDRTMADLHTARLENEKVKKQLADAVAELK 413
Cdd:COG4942 165 LRAELEAERAELEALLAELEEERAALEALKAERQKLLARLEKELAELAAELAELQQEAEELE 226
|
|
| SMC_prok_A |
TIGR02169 |
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ... |
153-466 |
1.82e-07 |
|
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 55.07 E-value: 1.82e-07
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 153 KIEKTMKEKEELLKLIAVLEKETAQLREQVGRMERELNHEKERCDQLQAEQKGLTEVTQSLKMENEEFKKRFSDATSKAH 232
Cdd:TIGR02169 717 KIGEIEKEIEQLEQEEEKLKERLEELEEDLSSLEQEIENVKSELKELEARIEELEEDLHKLEEALNDLEARLSHSRIPEI 796
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 233 QLEEDIVSVTHKAIEKetELDSLKDKLKKAQHEREQLECQLKTEKDEKElykvhlkntEIENTKLMSEvQTLKNLDGNKE 312
Cdd:TIGR02169 797 QAELSKLEEEVSRIEA--RLREIEQKLNRLTLEKEYLEKEIQELQEQRI---------DLKEQIKSIE-KEIENLNGKKE 864
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 313 SvithFKEEIGRLQLCLAEKEnlqrtfllttSSKEDtcfLKEQLRKAEEQVQATRQEVvflaKELSDAVNVRDRTMADLH 392
Cdd:TIGR02169 865 E----LEEELEELEAALRDLE----------SRLGD---LKKERDELEAQLRELERKI----EELEAQIEKKRKRLSELK 923
|
250 260 270 280 290 300 310
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....
gi 1384071986 393 TARLENEKVKKQLADAVAELK-----LNAMKKDQDKTDTLEHELRReVEDLKLRlqmAADHYKEKFKECQRLQKQINKL 466
Cdd:TIGR02169 924 AKLEALEEELSEIEDPKGEDEeipeeELSLEDVQAELQRVEEEIRA-LEPVNML---AIQEYEEVLKRLDELKEKRAKL 998
|
|
| EnvC |
COG4942 |
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, ... |
251-471 |
2.13e-07 |
|
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 443969 [Multi-domain] Cd Length: 377 Bit Score: 54.00 E-value: 2.13e-07
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 251 ELDSLKDKLKKAQHEREQLECQLKTEKDEKELYKVHLKNTEIENTKLMSEVQTLKNLDGNKESVITHFKEEIGRLQLCLA 330
Cdd:COG4942 21 AAAEAEAELEQLQQEIAELEKELAALKKEEKALLKQLAALERRIAALARRIRALEQELAALEAELAELEKEIAELRAELE 100
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 331 EKENLqrtfllttsskedtcfLKEQLRKAEEQVQATRQEVVFLAKELSDAV----------NVRDRTMADLHTARLENEK 400
Cdd:COG4942 101 AQKEE----------------LAELLRALYRLGRQPPLALLLSPEDFLDAVrrlqylkylaPARREQAEELRADLAELAA 164
|
170 180 190 200 210 220 230
....*....|....*....|....*....|....*....|....*....|....*....|....*....|...
gi 1384071986 401 VKKQLADAVAELK--LNAMKKDQDKTDTLEHELRREVEDLKLRLQMAADHYKEKFKECQRLQKQINKLSDQSA 471
Cdd:COG4942 165 LRAELEAERAELEalLAELEEERAALEALKAERQKLLARLEKELAELAAELAELQQEAEELEALIARLEAEAA 237
|
|
| COG5022 |
COG5022 |
Myosin heavy chain [General function prediction only]; |
156-618 |
4.39e-07 |
|
Myosin heavy chain [General function prediction only];
Pssm-ID: 227355 [Multi-domain] Cd Length: 1463 Bit Score: 53.93 E-value: 4.39e-07
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 156 KTMKEKEELLKLIAVLEKETAQLREQVGRMERELNHEKERCDQLQAEQKGLTEVTQSLKMEN--EEFKKRFSDATSKAHQ 233
Cdd:COG5022 807 GSRKEYRSYLACIIKLQKTIKREKKLRETEEVEFSLKAEVLIQKFGRSLKAKKRFSLLKKETiyLQSAQRVELAERQLQE 886
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 234 LEEDIVSVTHKAiEKETELDSLKDKLKKAQHEREQLECQLKTEKDEKelYKVHLKNTEIENTKLMSEVQtlknldgnkes 313
Cdd:COG5022 887 LKIDVKSISSLK-LVNLELESEIIELKKSLSSDLIENLEFKTELIAR--LKKLLNNIDLEEGPSIEYVK----------- 952
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 314 vithfKEEIGRLQLCLAEKENLQRTFLLTTSSKEDTcflKEQLRKAEEQVQATRQEVVFLAKEL------SDAVNVRDRT 387
Cdd:COG5022 953 -----LPELNKLHEVESKLKETSEEYEDLLKKSTIL---VREGNKANSELKNFKKELAELSKQYgalqesTKQLKELPVE 1024
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 388 MADLHTA--RLENEKVKKQLADAVAELKLNAMKKDQD-KTDTLEHELRRE--VEDLKLRLQMAADHYKEKfkecqRLQKQ 462
Cdd:COG5022 1025 VAELQSAskIISSESTELSILKPLQKLKGLLLLENNQlQARYKALKLRREnsLLDDKQLYQLESTENLLK-----TINVK 1099
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 463 INKLSDQSANNNNVFTKKTGNQQKVNDASVNTDPATSASTVDVKPSPSAAEADFDIVTKGQVCEMTKEIADKTEKYNKCK 542
Cdd:COG5022 1100 DLEVTNRNLVKPANVLQFIVAQMIKLNLLQEISKFLSQLVNTLEPVFQKLSVLQLELDGLFWEANLEALPSPPPFAALSE 1179
|
410 420 430 440 450 460 470
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*.
gi 1384071986 543 QLLQDEKAKCNKYADELAKMELKWKEQVKIAENVKlELAEVQDNYKELKRSLENPAERKMEGQNSQSPQCFKTCSE 618
Cdd:COG5022 1180 KRLYQSALYDEKSKLSSSEVNDLKNELIALFSKIF-SGWPRGDKLKKLISEGWVPTEYSTSLKGFNNLNKKFDTPA 1254
|
|
| CCDC158 |
pfam15921 |
Coiled-coil domain-containing protein 158; CCDC158 is a family of proteins found in eukaryotes. ... |
151-585 |
4.62e-07 |
|
Coiled-coil domain-containing protein 158; CCDC158 is a family of proteins found in eukaryotes. The function is not known.
Pssm-ID: 464943 [Multi-domain] Cd Length: 1112 Bit Score: 53.58 E-value: 4.62e-07
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 151 ELKIEKTMKEK--EELLKLIAVLEKETAQLREQVGRMERELNHEKercDQLQAEQKGLTEVTQSLKMENEEFKKRFSDAT 228
Cdd:pfam15921 332 ELREAKRMYEDkiEELEKQLVLANSELTEARTERDQFSQESGNLD---DQLQKLLADLHKREKELSLEKEQNKRLWDRDT 408
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 229 SKAhqleediVSVTHKAIE---KETELDSLKDKLKKAQHE-REQLECQLKTEKDEKE-LYKVHLKNTEIENTKLM----- 298
Cdd:pfam15921 409 GNS-------ITIDHLRRElddRNMEVQRLEALLKAMKSEcQGQMERQMAAIQGKNEsLEKVSSLTAQLESTKEMlrkvv 481
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 299 -----------SEVQTLKNLDGN---KESVITHFKEEI----GRLQLCLAEKENLQRTFLLTTSSKEDTCFLKEQLRKAE 360
Cdd:pfam15921 482 eeltakkmtleSSERTVSDLTASlqeKERAIEATNAEItklrSRVDLKLQELQHLKNEGDHLRNVQTECEALKLQMAEKD 561
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 361 EQVQATRQEVvflaKELSDAVNVRDRTMADLhtaRLENEKVKKQLADAVAELKlnAMKKDQDKTDTLEHELRREVEDLKL 440
Cdd:pfam15921 562 KVIEILRQQI----ENMTQLVGQHGRTAGAM---QVEKAQLEKEINDRRLELQ--EFKILKDKKDAKIRELEARVSDLEL 632
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 441 -----------RLQMAADHYKEK---FKECQRLQKQINKLSD------QSANNNNVFTKKTGNQQKVNDASVNTDPATSA 500
Cdd:pfam15921 633 ekvklvnagseRLRAVKDIKQERdqlLNEVKTSRNELNSLSEdyevlkRNFRNKSEEMETTTNKLKMQLKSAQSELEQTR 712
|
410 420 430 440 450 460 470 480
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 501 STV------DVKPSPSAAEADFDIVTK-GQVCEMTKEIA---DKTEKYNKCKQLLQDEKAKC-----------NKYADEL 559
Cdd:pfam15921 713 NTLksmegsDGHAMKVAMGMQKQITAKrGQIDALQSKIQfleEAMTNANKEKHFLKEEKNKLsqelstvatekNKMAGEL 792
|
490 500 510
....*....|....*....|....*....|...
gi 1384071986 560 AKM---ELKWKEQVKIAE----NVKLELAEVQD 585
Cdd:pfam15921 793 EVLrsqERRLKEKVANMEvaldKASLQFAECQD 825
|
|
| CCDC158 |
pfam15921 |
Coiled-coil domain-containing protein 158; CCDC158 is a family of proteins found in eukaryotes. ... |
116-447 |
4.73e-07 |
|
Coiled-coil domain-containing protein 158; CCDC158 is a family of proteins found in eukaryotes. The function is not known.
Pssm-ID: 464943 [Multi-domain] Cd Length: 1112 Bit Score: 53.58 E-value: 4.73e-07
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 116 TPFQFRASSPVEELLTMEDEGNSdMLVVTTKAGLLELKiektMKEKEELLKLiavleketaqLREQVGRMERELNHEKER 195
Cdd:pfam15921 520 TKLRSRVDLKLQELQHLKNEGDH-LRNVQTECEALKLQ----MAEKDKVIEI----------LRQQIENMTQLVGQHGRT 584
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 196 CDQLQAEQKGLTEVTQSLKMENEEFKKRFSDATSKAHQLEediVSVTHKAIEKETELDSLKDKL---KKAQHEREQLECQ 272
Cdd:pfam15921 585 AGAMQVEKAQLEKEINDRRLELQEFKILKDKKDAKIRELE---ARVSDLELEKVKLVNAGSERLravKDIKQERDQLLNE 661
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 273 LKTEKDE----KELYKVHLKN-----TEIENTKLMSEVQtLKNLDGNKESVITHFKEEIG------RLQLCLAEKENLQR 337
Cdd:pfam15921 662 VKTSRNElnslSEDYEVLKRNfrnksEEMETTTNKLKMQ-LKSAQSELEQTRNTLKSMEGsdghamKVAMGMQKQITAKR 740
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 338 TFLLTTSSKEDtcFLKEQLRKAEEQVQATRQEVVFLAKELSDAVNVRDRTMADLHTARLENEKVKKQLADAVAELKLNAM 417
Cdd:pfam15921 741 GQIDALQSKIQ--FLEEAMTNANKEKHFLKEEKNKLSQELSTVATEKNKMAGELEVLRSQERRLKEKVANMEVALDKASL 818
|
330 340 350
....*....|....*....|....*....|
gi 1384071986 418 KKDQDKtDTLEhelRREVEDLKLRLQMAAD 447
Cdd:pfam15921 819 QFAECQ-DIIQ---RQEQESVRLKLQHTLD 844
|
|
| HCR |
pfam07111 |
Alpha helical coiled-coil rod protein (HCR); This family consists of several mammalian alpha ... |
123-462 |
6.10e-07 |
|
Alpha helical coiled-coil rod protein (HCR); This family consists of several mammalian alpha helical coiled-coil rod HCR proteins. The function of HCR is unknown but it has been implicated in psoriasis in humans and is thought to affect keratinocyte proliferation.
Pssm-ID: 284517 [Multi-domain] Cd Length: 749 Bit Score: 53.22 E-value: 6.10e-07
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 123 SSPVEELLTMEDEGNSdmlvvttkagLLELKIEKTMKEKEELLKLIAVLEKETAQLREQVGRMERELNHEKERCDQLQAE 202
Cdd:pfam07111 69 SRQLQELRRLEEEVRL----------LRETSLQQKMRLEAQAMELDALAVAEKAGQAEAEGLRAALAGAEMVRKNLEEGS 138
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 203 QKGLTEVtQSLKMEN-----EEFKKRFSDATSKAHQLEEDIVSVTHK---------AIEKETELdsLKDKLKKAQherEQ 268
Cdd:pfam07111 139 QRELEEI-QRLHQEQlssltQAHEEALSSLTSKAEGLEKSLNSLETKrageakqlaEAQKEAEL--LRKQLSKTQ---EE 212
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 269 LECQ------LKTEKDEKELYKVHLKNTEIENTKLMSEVQTLKNLDGNKESVITHFKEEIGRLQLCLAEKENLqrtflLT 342
Cdd:pfam07111 213 LEAQvtlvesLRKYVGEQVPPEVHSQTWELERQELLDTMQHLQEDRADLQATVELLQVRVQSLTHMLALQEEE-----LT 287
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 343 TSSKEDTCFLKEQLRKAEEQVQATRQEVVFLakelsdavnvrdrtMADLHTARLENEKVKKQLADAVAELKLNAMKKD-- 420
Cdd:pfam07111 288 RKIQPSDSLEPEFPKKCRSLLNRWREKVFAL--------------MVQLKAQDLEHRDSVKQLRGQVAELQEQVTSQSqe 353
|
330 340 350 360 370
....*....|....*....|....*....|....*....|....*....|
gi 1384071986 421 --------QDKTDTLEHElRREVEDLKLRLQMAadhykekfKECQRLQKQ 462
Cdd:pfam07111 354 qailqralQDKAAEVEVE-RMSAKGLQMELSRA--------QEARRRQQQ 394
|
|
| YhaN |
COG4717 |
Uncharacterized conserved protein YhaN, contains AAA domain [Function unknown]; |
150-469 |
6.83e-07 |
|
Uncharacterized conserved protein YhaN, contains AAA domain [Function unknown];
Pssm-ID: 443752 [Multi-domain] Cd Length: 641 Bit Score: 52.85 E-value: 6.83e-07
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 150 LELKIEKTMKEKEELLKLIAVLE--KETAQLREQVGRMERELNHEKERCDQLQAEQKGLTEVTQSLKMENEEF---KKRF 224
Cdd:COG4717 107 LEAELEELREELEKLEKLLQLLPlyQELEALEAELAELPERLEELEERLEELRELEEELEELEAELAELQEELeelLEQL 186
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 225 SDATSKA-HQLEEDIVSVTHKAIEKETELDSLKDKLKKAQHEREQLECQLKTEKDEKELYK------------------- 284
Cdd:COG4717 187 SLATEEElQDLAEELEELQQRLAELEEELEEAQEELEELEEELEQLENELEAAALEERLKEarlllliaaallallglgg 266
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 285 ------------------------VHLKNTEIENTKLMSEVQTLKNLDGNKESVITHFKEEIGRlqlclaeKENLQRTFL 340
Cdd:COG4717 267 sllsliltiagvlflvlgllallfLLLAREKASLGKEAEELQALPALEELEEEELEELLAALGL-------PPDLSPEEL 339
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 341 LTTSSK-EDTCFLKEQLRKAEEQVQatRQEVVFLAKELSDAVNVRDRTM-ADLHTARLENEKVKKQLADAVAELKLNAMK 418
Cdd:COG4717 340 LELLDRiEELQELLREAEELEEELQ--LEELEQEIAALLAEAGVEDEEElRAALEQAEEYQELKEELEELEEQLEELLGE 417
|
330 340 350 360 370
....*....|....*....|....*....|....*....|....*....|.
gi 1384071986 419 KDQDKTDTLEHELRREVEDLKLRLQMAADHYKEKFKECQRLQKQINKLSDQ 469
Cdd:COG4717 418 LEELLEALDEEELEEELEELEEELEELEEELEELREELAELEAELEQLEED 468
|
|
| PRK03918 |
PRK03918 |
DNA double-strand break repair ATPase Rad50; |
154-467 |
1.01e-06 |
|
DNA double-strand break repair ATPase Rad50;
Pssm-ID: 235175 [Multi-domain] Cd Length: 880 Bit Score: 52.37 E-value: 1.01e-06
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 154 IEKTMKEKEELLKLIAVLEKETAQLREQVGRMERELNHEKERCDQLQAEQKGLTEvtqsLKMENEEFKKRFSDATSKAHQ 233
Cdd:PRK03918 181 LEKFIKRTENIEELIKEKEKELEEVLREINEISSELPELREELEKLEKEVKELEE----LKEEIEELEKELESLEGSKRK 256
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 234 LEEDIVSVTHKAIEKETELDSLKDKLKKAQHEREQLECQLKTEKdEKELYKVHLKNTEIENTKLMSEVQTLKNL---DGN 310
Cdd:PRK03918 257 LEEKIRELEERIEELKKEIEELEEKVKELKELKEKAEEYIKLSE-FYEEYLDELREIEKRLSRLEEEINGIEERikeLEE 335
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 311 KESVITHFKEEIGRLQLCLAEKENLQRTFllttsskEDTCFLKEQLRKAEEQVQA-TRQEVVFLAKELSDAVNVRDRTMA 389
Cdd:PRK03918 336 KEERLEELKKKLKELEKRLEELEERHELY-------EEAKAKKEELERLKKRLTGlTPEKLEKELEELEKAKEEIEEEIS 408
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 390 DLHTARLENEKVKKQLADAVAELKLNAMK--------KDQDKTDTLEhELRREVEDLKLRLQMAADHYKEKFKECQRLQK 461
Cdd:PRK03918 409 KITARIGELKKEIKELKKAIEELKKAKGKcpvcgrelTEEHRKELLE-EYTAELKRIEKELKEIEEKERKLRKELRELEK 487
|
....*.
gi 1384071986 462 QINKLS 467
Cdd:PRK03918 488 VLKKES 493
|
|
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
150-595 |
1.77e-06 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 51.60 E-value: 1.77e-06
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 150 LELKIEKTMKEKEELLKLIAVLEKETAQLREQVGRMERELNHEKERCDQLQAEQKGLTEVTQS-----LKMENEEFKKRF 224
Cdd:TIGR02168 370 LESRLEELEEQLETLRSKVAQLELQIASLNNEIERLEARLERLEDRRERLQQEIEELLKKLEEaelkeLQAELEELEEEL 449
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 225 SDATSKAHQLEEDIVSVTHKAIEKETELDSLKDKLKKAQHEREQLEcQLKTEKDEKELYKVHLKNTEIENTKLMSEVQTL 304
Cdd:TIGR02168 450 EELQEELERLEEALEELREELEEAEQALDAAERELAQLQARLDSLE-RLQENLEGFSEGVKALLKNQSGLSGILGVLSEL 528
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 305 KNLD------------GNKESVITHFKEEIGRLQLCLAEKENLQRTFLLTTSSKEDTC-FLKEQLRKAEEQVQATRQEVV 371
Cdd:TIGR02168 529 ISVDegyeaaieaalgGRLQAVVVENLNAAKKAIAFLKQNELGRVTFLPLDSIKGTEIqGNDREILKNIEGFLGVAKDLV 608
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 372 FLAKELSDAVN---------------------------------------------VRDRTMADLHTAR--LENEKVKKQ 404
Cdd:TIGR02168 609 KFDPKLRKALSyllggvlvvddldnalelakklrpgyrivtldgdlvrpggvitggSAKTNSSILERRReiEELEEKIEE 688
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 405 LADAVAELK--LNAMKKDQDKTDTLEHELRREVEDLKLRLQMAADHYKEKFKECQRLQKQINKLSDQSANNNNvftKKTG 482
Cdd:TIGR02168 689 LEEKIAELEkaLAELRKELEELEEELEQLRKELEELSRQISALRKDLARLEAEVEQLEERIAQLSKELTELEA---EIEE 765
|
410 420 430 440 450 460 470 480
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 483 NQQKVNDASVNTDpATSASTVDVKPSPSAAEADFDIVT------KGQVCEMTKEIADKTEKYNKckqlLQDEKAKCNKYA 556
Cdd:TIGR02168 766 LEERLEEAEEELA-EAEAEIEELEAQIEQLKEELKALRealdelRAELTLLNEEAANLRERLES----LERRIAATERRL 840
|
490 500 510
....*....|....*....|....*....|....*....
gi 1384071986 557 DELAKmelKWKEQVKIAENVKLELAEVQDNYKELKRSLE 595
Cdd:TIGR02168 841 EDLEE---QIEELSEDIESLAAEIEELEELIEELESELE 876
|
|
| Myosin_tail_1 |
pfam01576 |
Myosin tail; The myosin molecule is a multi-subunit complex made up of two heavy chains and ... |
160-469 |
2.58e-06 |
|
Myosin tail; The myosin molecule is a multi-subunit complex made up of two heavy chains and four light chains it is a fundamental contractile protein found in all eukaryote cell types. This family consists of the coiled-coil myosin heavy chain tail region. The coiled-coil is composed of the tail from two molecules of myosin. These can then assemble into the macromolecular thick filament. The coiled-coil region provides the structural backbone the thick filament.
Pssm-ID: 460256 [Multi-domain] Cd Length: 1081 Bit Score: 51.33 E-value: 2.58e-06
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 160 EKEELLkliAVLEKETAQLREQVGRMERELNHEKERCDQLQAEQKGLTEVTQSLKMENEEfkkrfSDATSKAHQLEEdiV 239
Cdd:pfam01576 58 EAEEMR---ARLAARKQELEEILHELESRLEEEEERSQQLQNEKKKMQQHIQDLEEQLDE-----EEAARQKLQLEK--V 127
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 240 SVTHKAIEKETELDSLKDKLKKAQHEREQLECQLK------TEKDE--KELYKVHLKN----TEIENtKLMSEVQTLKNL 307
Cdd:pfam01576 128 TTEAKIKKLEEDILLLEDQNSKLSKERKLLEERISeftsnlAEEEEkaKSLSKLKNKHeamiSDLEE-RLKKEEKGRQEL 206
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 308 DGNK---ESVITHFKEEIGRLQLCLAEkenlqrtfllttsskedtcfLKEQLRKAEEQVQATRQEV-------VFLAKEL 377
Cdd:pfam01576 207 EKAKrklEGESTDLQEQIAELQAQIAE--------------------LRAQLAKKEEELQAALARLeeetaqkNNALKKI 266
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 378 SDAVNVRDRTMADLHTARLENEKVKKQLADAVAElkLNAMKKD-QDKTDT--LEHELR----REVEDLKLRLQMAADHYK 450
Cdd:pfam01576 267 RELEAQISELQEDLESERAARNKAEKQRRDLGEE--LEALKTElEDTLDTtaAQQELRskreQEVTELKKALEEETRSHE 344
|
330 340
....*....|....*....|
gi 1384071986 451 EKFKEC-QRLQKQINKLSDQ 469
Cdd:pfam01576 345 AQLQEMrQKHTQALEELTEQ 364
|
|
| GumC |
COG3206 |
Exopolysaccharide export protein/domain GumC/Wzc1 [Cell wall/membrane/envelope biogenesis]; |
352-494 |
2.68e-06 |
|
Exopolysaccharide export protein/domain GumC/Wzc1 [Cell wall/membrane/envelope biogenesis];
Pssm-ID: 442439 [Multi-domain] Cd Length: 687 Bit Score: 50.79 E-value: 2.68e-06
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 352 LKEQLRKAEEQVQATRQE--VVFLAKELSDAVNVRDRTMADLHTARLENEKVKKQLADAVAELKLNAMKKDQDKTDTLEH 429
Cdd:COG3206 187 LRKELEEAEAALEEFRQKngLVDLSEEAKLLLQQLSELESQLAEARAELAEAEARLAALRAQLGSGPDALPELLQSPVIQ 266
|
90 100 110 120 130 140
....*....|....*....|....*....|....*....|....*....|....*....|....*
gi 1384071986 430 ELRREVEDLKLRLQMAADHYKEKFKECQRLQKQINKLSDQSANNNNVFTKKTGNQQKVNDASVNT 494
Cdd:COG3206 267 QLRAQLAELEAELAELSARYTPNHPDVIALRAQIAALRAQLQQEAQRILASLEAELEALQAREAS 331
|
|
| Myosin_tail_1 |
pfam01576 |
Myosin tail; The myosin molecule is a multi-subunit complex made up of two heavy chains and ... |
146-592 |
3.16e-06 |
|
Myosin tail; The myosin molecule is a multi-subunit complex made up of two heavy chains and four light chains it is a fundamental contractile protein found in all eukaryote cell types. This family consists of the coiled-coil myosin heavy chain tail region. The coiled-coil is composed of the tail from two molecules of myosin. These can then assemble into the macromolecular thick filament. The coiled-coil region provides the structural backbone the thick filament.
Pssm-ID: 460256 [Multi-domain] Cd Length: 1081 Bit Score: 50.94 E-value: 3.16e-06
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 146 KAGLLELKIEKTMKEkEELLKLIAVLEKETAQ-------LRE---QVGRMERELNHEKERCDQLQAEQKGLTEVTQSLKM 215
Cdd:pfam01576 228 QAQIAELRAQLAKKE-EELQAALARLEEETAQknnalkkIREleaQISELQEDLESERAARNKAEKQRRDLGEELEALKT 306
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 216 ENEEFKkrfsDATSKAHQLE---EDIVSVTHKAIEKETE----------------LDSLKDKLKKAQHEREQLE-CQLKT 275
Cdd:pfam01576 307 ELEDTL----DTTAAQQELRskrEQEVTELKKALEEETRsheaqlqemrqkhtqaLEELTEQLEQAKRNKANLEkAKQAL 382
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 276 EKDEKELyKVHLK-------NTEIENTKLMSEVQTLKNLDGNKESVITHFKEEIGRLQlclAEKENLQrTFLLTTSSK-- 346
Cdd:pfam01576 383 ESENAEL-QAELRtlqqakqDSEHKRKKLEGQLQELQARLSESERQRAELAEKLSKLQ---SELESVS-SLLNEAEGKni 457
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 347 ---EDTCFLKEQLRKAEEQVQA-TRQEVVFLAK--ELSDAVNVRDRTMADLHTARLENEKVKKQLADAVAELKlnamKKD 420
Cdd:pfam01576 458 klsKDVSSLESQLQDTQELLQEeTRQKLNLSTRlrQLEDERNSLQEQLEEEEEAKRNVERQLSTLQAQLSDMK----KKL 533
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 421 QDKTDTLE------HELRREVEDLKLRlqmaadhYKEKFKECQRLQKQINKLsdqsannnnvftkktgnQQKVNDASVNT 494
Cdd:pfam01576 534 EEDAGTLEaleegkKRLQRELEALTQQ-------LEEKAAAYDKLEKTKNRL-----------------QQELDDLLVDL 589
|
410 420 430 440 450 460 470 480
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 495 DpatsastvdvkpspsaaeadfdivTKGQVCemtkeiADKTEKYNKCKQLLQDEKAKCNKYADELAKMELKWKEQVKIAE 574
Cdd:pfam01576 590 D------------------------HQRQLV------SNLEKKQKKFDQMLAEEKAISARYAEERDRAEAEAREKETRAL 639
|
490
....*....|....*...
gi 1384071986 575 NVKLELAEVQDNYKELKR 592
Cdd:pfam01576 640 SLARALEEALEAKEELER 657
|
|
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
220-469 |
5.21e-06 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 50.06 E-value: 5.21e-06
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 220 FKKRFSDATSKAHQLEEDIVSVTHKAIEKETELDSLKDKLKKAQHEREqlecqLKTEKDEKEL---------YKVHLKNT 290
Cdd:TIGR02168 170 YKERRKETERKLERTRENLDRLEDILNELERQLKSLERQAEKAERYKE-----LKAELRELELallvlrleeLREELEEL 244
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 291 EIENTKLMSEVQTLKNLDGNKESVITHFKEEIGRLQlclAEKENLQRTFLLTTSSKEDtcfLKEQLRKAEEQVQATRQEV 370
Cdd:TIGR02168 245 QEELKEAEEELEELTAELQELEEKLEELRLEVSELE---EEIEELQKELYALANEISR---LEQQKQILRERLANLERQL 318
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 371 VFLAKELSDAVNVRDRTMADLHTARLENEKVKKQLADAVAEL-----KLNAMKKDQDKTDTLEHELRREVEDLKLRLQMA 445
Cdd:TIGR02168 319 EELEAQLEELESKLDELAEELAELEEKLEELKEELESLEAELeeleaELEELESRLEELEEQLETLRSKVAQLELQIASL 398
|
250 260
....*....|....*....|....
gi 1384071986 446 ADHYKEKFKECQRLQKQINKLSDQ 469
Cdd:TIGR02168 399 NNEIERLEARLERLEDRRERLQQE 422
|
|
| CwlO1 |
COG3883 |
Uncharacterized N-terminal coiled-coil domain of peptidoglycan hydrolase CwlO [Function ... |
151-303 |
6.27e-06 |
|
Uncharacterized N-terminal coiled-coil domain of peptidoglycan hydrolase CwlO [Function unknown];
Pssm-ID: 443091 [Multi-domain] Cd Length: 379 Bit Score: 49.06 E-value: 6.27e-06
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 151 ELKIEKTMKEKEELLKLIAVLEKETAQLREQVGRMERELNHEKERCDQLQAE----QKGLTEVTQSLKMENEEFKKR--- 223
Cdd:COG3883 15 DPQIQAKQKELSELQAELEAAQAELDALQAELEELNEEYNELQAELEALQAEidklQAEIAEAEAEIEERREELGERara 94
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 224 -------------------FSDATSKAHQLeEDIVSVTHKAIEketELDSLKDKLKKAQHEREQLECQLKTEKDEKELYK 284
Cdd:COG3883 95 lyrsggsvsyldvllgsesFSDFLDRLSAL-SKIADADADLLE---ELKADKAELEAKKAELEAKLAELEALKAELEAAK 170
|
170
....*....|....*....
gi 1384071986 285 VHLKNTEIENTKLMSEVQT 303
Cdd:COG3883 171 AELEAQQAEQEALLAQLSA 189
|
|
| Spc7 |
smart00787 |
Spc7 kinetochore protein; This domain is found in cell division proteins which are required ... |
150-282 |
9.54e-06 |
|
Spc7 kinetochore protein; This domain is found in cell division proteins which are required for kinetochore-spindle association.
Pssm-ID: 197874 [Multi-domain] Cd Length: 312 Bit Score: 48.48 E-value: 9.54e-06
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 150 LELKIEKTMKEKEELLKLIAVLEKETAQLREQVGRMEREL----NHEKERCDQLQAEQKGLTEVTQSLKMENEEFKKRFS 225
Cdd:smart00787 149 LDENLEGLKEDYKLLMKELELLNSIKPKLRDRKDALEEELrqlkQLEDELEDCDPTELDRAKEKLKKLLQEIMIKVKKLE 228
|
90 100 110 120 130
....*....|....*....|....*....|....*....|....*....|....*..
gi 1384071986 226 DATSKAHQLEEDIVSVTHKAIEKETELDSLKDKLKkaqhereqlECQLKTEKDEKEL 282
Cdd:smart00787 229 ELEEELQELESKIEDLTNKKSELNTEIAEAEKKLE---------QCRGFTFKEIEKL 276
|
|
| COG4372 |
COG4372 |
Uncharacterized protein, contains DUF3084 domain [Function unknown]; |
149-446 |
1.43e-05 |
|
Uncharacterized protein, contains DUF3084 domain [Function unknown];
Pssm-ID: 443500 [Multi-domain] Cd Length: 370 Bit Score: 47.97 E-value: 1.43e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 149 LLELKIEKTMKEKEELLKLIAVLEKETAQLREQVGRMERELNHEKERCDQLQAEQKGLTEVTQSLKMENEEFKKRFSDAT 228
Cdd:COG4372 28 ALSEQLRKALFELDKLQEELEQLREELEQAREELEQLEEELEQARSELEQLEEELEELNEQLQAAQAELAQAQEELESLQ 107
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 229 SKAHQLEEDIVSVthkaiekETELDSLKDKLKKAQHEREQLECQLKTEKDEKELYKVHLKNTEIENTKLMSEVQTLKNLD 308
Cdd:COG4372 108 EEAEELQEELEEL-------QKERQDLEQQRKQLEAQIAELQSEIAEREEELKELEEQLESLQEELAALEQELQALSEAE 180
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 309 GNKEsVITHFKEEIGRLQLCLAEKENLQRTFLLTTSSKEDTCFLKEQLRKAEEQVQATRQEVVFLAKELSDAVNVRDRTM 388
Cdd:COG4372 181 AEQA-LDELLKEANRNAEKEEELAEAEKLIESLPRELAEELLEAKDSLEAKLGLALSALLDALELEEDKEELLEEVILKE 259
|
250 260 270 280 290
....*....|....*....|....*....|....*....|....*....|....*...
gi 1384071986 389 ADLHTARLENEKVKKQLADAVAELKLNAMKKDQDKTDTLEHELRREVEDLKLRLQMAA 446
Cdd:COG4372 260 IEELELAILVEKDTEEEELEIAALELEALEEAALELKLLALLLNLAALSLIGALEDAL 317
|
|
| COG4913 |
COG4913 |
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown]; |
145-274 |
1.45e-05 |
|
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown];
Pssm-ID: 443941 [Multi-domain] Cd Length: 1089 Bit Score: 48.76 E-value: 1.45e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 145 TKAGLLELKIEKTMKEKEELLKLIAVLEKETAQLRE---------------QVGRMERELNHEKERCDQLQAEQKGLTEV 209
Cdd:COG4913 288 RRLELLEAELEELRAELARLEAELERLEARLDALREeldeleaqirgnggdRLEQLEREIERLERELEERERRRARLEAL 367
|
90 100 110 120 130 140
....*....|....*....|....*....|....*....|....*....|....*....|....*
gi 1384071986 210 TQSLKMENEEFKKRFSDATSKAHQLEEDIVSVTHKAiekETELDSLKDKLKKAQHEREQLECQLK 274
Cdd:COG4913 368 LAALGLPLPASAEEFAALRAEAAALLEALEEELEAL---EEALAEAEAALRDLRRELRELEAEIA 429
|
|
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
352-600 |
1.48e-05 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 48.90 E-value: 1.48e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 352 LKEQLRKAEEQVQATRQEVVFLAKELSDAVNVRDRTMADLHTARL---ENEKVKKQLADAVAELK--LNAMKKDQDKTDT 426
Cdd:TIGR02168 731 LRKDLARLEAEVEQLEERIAQLSKELTELEAEIEELEERLEEAEEelaEAEAEIEELEAQIEQLKeeLKALREALDELRA 810
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 427 LEHELRREVEDLKLRLQMAADHYKEKFKECQRLQKQINKLSDQSANNNNVFTKKTGNQQKVNDASVNTDPATSASTVDVK 506
Cdd:TIGR02168 811 ELTLLNEEAANLRERLESLERRIAATERRLEDLEEQIEELSEDIESLAAEIEELEELIEELESELEALLNERASLEEALA 890
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 507 pspsAAEADFDIVTKgQVCEMTKEIADKTEKYNKCKQLLQDEKAKCNKyadelAKMELKWKEQvKIAENVKLELAEVQDN 586
Cdd:TIGR02168 891 ----LLRSELEELSE-ELRELESKRSELRRELEELREKLAQLELRLEG-----LEVRIDNLQE-RLSEEYSLTLEEAEAL 959
|
250
....*....|....
gi 1384071986 587 YKELKRSLENPAER 600
Cdd:TIGR02168 960 ENKIEDDEEEARRR 973
|
|
| Mplasa_alph_rch |
TIGR04523 |
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of ... |
184-479 |
1.55e-05 |
|
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of Mycoplasma species. Members average 750 amino acids in length, including signal peptide. Sequences are predicted (Jpred 3) to be almost entirely alpha-helical. These sequences show strong periodicity (consistent with long alpha helical structures) and low complexity rich in D,E,N,Q, and K. Genes encoding these proteins are often found in tandem. The function is unknown.
Pssm-ID: 275316 [Multi-domain] Cd Length: 745 Bit Score: 48.48 E-value: 1.55e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 184 RMERELNHEKERCDQLQAEQKGL-------TEVTQSLKMENEEFKKRFSDATSKAHQLEEDIVSVTHKAIEKETELDSLK 256
Cdd:TIGR04523 37 QLEKKLKTIKNELKNKEKELKNLdknlnkdEEKINNSNNKIKILEQQIKDLNDKLKKNKDKINKLNSDLSKINSEIKNDK 116
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 257 DKLKKAQHEREQLECQLKTEKDEKELYKVHLKNTEIENTKLMSEVQTLKNLDGNKESVITHFKEEIGRLQLCLAeKENLQ 336
Cdd:TIGR04523 117 EQKNKLEVELNKLEKQKKENKKNIDKFLTEIKKKEKELEKLNNKYNDLKKQKEELENELNLLEKEKLNIQKNID-KIKNK 195
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 337 RTFLLTTSSK-----EDTCFLKEQLRKAEEQVQATRQEVVFLAKELSDAVNVRDRTMADLHTARLENEKVKKQLADAVAE 411
Cdd:TIGR04523 196 LLKLELLLSNlkkkiQKNKSLESQISELKKQNNQLKDNIEKKQQEINEKTTEISNTQTQLNQLKDEQNKIKKQLSEKQKE 275
|
250 260 270 280 290 300
....*....|....*....|....*....|....*....|....*....|....*....|....*...
gi 1384071986 412 LKlNAMKKDQDKTDTLEhELRREVEDLKlrLQMAADHYKEKFKECQRLQKQINKLSDQSANNNNVFTK 479
Cdd:TIGR04523 276 LE-QNNKKIKELEKQLN-QLKSEISDLN--NQKEQDWNKELKSELKNQEKKLEEIQNQISQNNKIISQ 339
|
|
| COG4372 |
COG4372 |
Uncharacterized protein, contains DUF3084 domain [Function unknown]; |
153-448 |
2.00e-05 |
|
Uncharacterized protein, contains DUF3084 domain [Function unknown];
Pssm-ID: 443500 [Multi-domain] Cd Length: 370 Bit Score: 47.59 E-value: 2.00e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 153 KIEKTMKEKEELLKLIAVLEKETAQLREQVGRMERELNHEKERCDQLQAEQKGLTEVTQSLKMENEEFKKRFSDATSKAH 232
Cdd:COG4372 53 ELEQAREELEQLEEELEQARSELEQLEEELEELNEQLQAAQAELAQAQEELESLQEEAEELQEELEELQKERQDLEQQRK 132
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 233 QLEEDIVSVTHKAIEKETELDSLKDKLKKAQHEREQLECQLKTEKDEKELYKVHLKNTEIENTKLMSEVQTLKNLDGNKE 312
Cdd:COG4372 133 QLEAQIAELQSEIAEREEELKELEEQLESLQEELAALEQELQALSEAEAEQALDELLKEANRNAEKEEELAEAEKLIESL 212
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 313 SVITHFKEEIGRLQLCLAEKENLQRTFLLTTSSKEDTCFLKEQLRK-AEEQVQATRQEVVFLAKELSDAVNVRDRTMADL 391
Cdd:COG4372 213 PRELAEELLEAKDSLEAKLGLALSALLDALELEEDKEELLEEVILKeIEELELAILVEKDTEEEELEIAALELEALEEAA 292
|
250 260 270 280 290
....*....|....*....|....*....|....*....|....*....|....*..
gi 1384071986 392 HTARLENEKVKKQLADAVAELKLNAMKKDQDKTDTLEHELRREVEDLKLRLQMAADH 448
Cdd:COG4372 293 LELKLLALLLNLAALSLIGALEDALLAALLELAKKLELALAILLAELADLLQLLLVG 349
|
|
| EnvC |
COG4942 |
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, ... |
150-307 |
2.01e-05 |
|
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 443969 [Multi-domain] Cd Length: 377 Bit Score: 47.45 E-value: 2.01e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 150 LELKIEKTMKEKEELLKLIAVLEKETAQLREQVGRMERELNHEKERCDQLQAEQKGLtevTQSLKMENEEFKKR------ 223
Cdd:COG4942 39 LEKELAALKKEEKALLKQLAALERRIAALARRIRALEQELAALEAELAELEKEIAEL---RAELEAQKEELAELlralyr 115
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 224 ---------------FSDATSKAH----------QLEEDIVSVTHKAIEKETELDSLKDKLKKAQHEREQLECQLKTEKD 278
Cdd:COG4942 116 lgrqpplalllspedFLDAVRRLQylkylaparrEQAEELRADLAELAALRAELEAERAELEALLAELEEERAALEALKA 195
|
170 180 190
....*....|....*....|....*....|...
gi 1384071986 279 EKELY----KVHLKNTEIENTKLMSEVQTLKNL 307
Cdd:COG4942 196 ERQKLlarlEKELAELAAELAELQQEAEELEAL 228
|
|
| COG4913 |
COG4913 |
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown]; |
176-442 |
2.36e-05 |
|
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown];
Pssm-ID: 443941 [Multi-domain] Cd Length: 1089 Bit Score: 47.99 E-value: 2.36e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 176 AQLREQVGRMERELNHEKERCDQLQAEQKGLTEvtqsLKMENEEFKKRFSDatskahqlEEDIVSVTHKAIEKETELDSL 255
Cdd:COG4913 613 AALEAELAELEEELAEAEERLEALEAELDALQE----RREALQRLAEYSWD--------EIDVASAEREIAELEAELERL 680
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 256 K---DKLKKAQHEREQLECQLKTEKDEKELYKVHLKNTEIENTKLMSEVQTLKNLDGNKESVITHFKEEIGRLQLCLAEK 332
Cdd:COG4913 681 DassDDLAALEEQLEELEAELEELEEELDELKGEIGRLEKELEQAEEELDELQDRLEAAEDLARLELRALLEERFAAALG 760
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 333 ENLQRTFLLTTSSKEDTcfLKEQLRKAEEQVQATRQEvvFLAKELSDAVNVrDRTMADLHT-----ARLENEKVKKQLAD 407
Cdd:COG4913 761 DAVERELRENLEERIDA--LRARLNRAEEELERAMRA--FNREWPAETADL-DADLESLPEylallDRLEEDGLPEYEER 835
|
250 260 270
....*....|....*....|....*....|....*
gi 1384071986 408 AvAELKLNAMkkDQDKTDtLEHELRREVEDLKLRL 442
Cdd:COG4913 836 F-KELLNENS--IEFVAD-LLSKLRRAIREIKERI 866
|
|
| Mplasa_alph_rch |
TIGR04523 |
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of ... |
134-296 |
2.87e-05 |
|
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of Mycoplasma species. Members average 750 amino acids in length, including signal peptide. Sequences are predicted (Jpred 3) to be almost entirely alpha-helical. These sequences show strong periodicity (consistent with long alpha helical structures) and low complexity rich in D,E,N,Q, and K. Genes encoding these proteins are often found in tandem. The function is unknown.
Pssm-ID: 275316 [Multi-domain] Cd Length: 745 Bit Score: 47.71 E-value: 2.87e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 134 DEGNSDMLVVTTKAGLLELKIEKTMKEKEELLKLIAVLEKETAQLREQVGRMERELNHEKERC--DQLQAEQKGLTEVTQ 211
Cdd:TIGR04523 492 KSKEKELKKLNEEKKELEEKVKDLTKKISSLKEKIEKLESEKKEKESKISDLEDELNKDDFELkkENLEKEIDEKNKEIE 571
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 212 SLKMENEEFKKRFSDATSKAHQLEEDIVSVTHKAIEKETELDSLKDKLKKAQHEREQLECQLKTEKDEKELYK--VHLKN 289
Cdd:TIGR04523 572 ELKQTQKSLKKKQEEKQELIDQKEKEKKDLIKEIEEKEKKISSLEKELEKAKKENEKLSSIIKNIKSKKNKLKqeVKQIK 651
|
....*..
gi 1384071986 290 TEIENTK 296
Cdd:TIGR04523 652 ETIKEIR 658
|
|
| PRK02224 |
PRK02224 |
DNA double-strand break repair Rad50 ATPase; |
121-463 |
5.04e-05 |
|
DNA double-strand break repair Rad50 ATPase;
Pssm-ID: 179385 [Multi-domain] Cd Length: 880 Bit Score: 46.96 E-value: 5.04e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 121 RASSPVEELLTMEDEgNSDMLvvtTKAGLLELKIEKTMKEKEELLKLIAVLEKETAQLREQVGRMERELNHEKERCDQLQ 200
Cdd:PRK02224 280 EVRDLRERLEELEEE-RDDLL---AEAGLDDADAEAVEARREELEDRDEELRDRLEECRVAAQAHNEEAESLREDADDLE 355
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 201 AEQKGLTEVTQSLKMENEEFKKRFSDATSKAHQLEEDIVS----------------------------VTHKAIEKETEL 252
Cdd:PRK02224 356 ERAEELREEAAELESELEEAREAVEDRREEIEELEEEIEElrerfgdapvdlgnaedfleelreerdeLREREAELEATL 435
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 253 DSLKDKLKKAQHEREQ-------------------LECQLKTEKDEKELYKVHLKNTEIEN--------TKLMSEVQTLK 305
Cdd:PRK02224 436 RTARERVEEAEALLEAgkcpecgqpvegsphvetiEEDRERVEELEAELEDLEEEVEEVEErleraedlVEAEDRIERLE 515
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 306 NLDGNKESVITHFKEEIGRLQLCLAEKEnlQRTFLLTTSSKEDtcflKEQLRKAEEQVQATRQEVVFLAKELSDAVNVRD 385
Cdd:PRK02224 516 ERREDLEELIAERRETIEEKRERAEELR--ERAAELEAEAEEK----REAAAEAEEEAEEAREEVAELNSKLAELKERIE 589
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 386 R--TMADLHTARLENEKVKKQLADAVAEL-KLNAMKKDQ-----DKTDTLEHELRRE-VEDLKLRLQMA-------ADHY 449
Cdd:PRK02224 590 SleRIRTLLAAIADAEDEIERLREKREALaELNDERRERlaekrERKRELEAEFDEArIEEAREDKERAeeyleqvEEKL 669
|
410
....*....|....
gi 1384071986 450 KEKFKECQRLQKQI 463
Cdd:PRK02224 670 DELREERDDLQAEI 683
|
|
| DR0291 |
COG1579 |
Predicted nucleic acid-binding protein DR0291, contains C4-type Zn-ribbon domain [General ... |
150-281 |
5.16e-05 |
|
Predicted nucleic acid-binding protein DR0291, contains C4-type Zn-ribbon domain [General function prediction only];
Pssm-ID: 441187 [Multi-domain] Cd Length: 236 Bit Score: 45.30 E-value: 5.16e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 150 LELKIEKTMKEKEELLKLIAVLEKETAQLREQVGRMERELNHEKERCDQLQAEQKG----LTEVT-----QSLKMENEEF 220
Cdd:COG1579 22 LEHRLKELPAELAELEDELAALEARLEAAKTELEDLEKEIKRLELEIEEVEARIKKyeeqLGNVRnnkeyEALQKEIESL 101
|
90 100 110 120 130 140
....*....|....*....|....*....|....*....|....*....|....*....|.
gi 1384071986 221 KKRFSDatskahqLEEDIVSVTHKAIEKETELDSLKDKLKKAQHEREQLECQLKTEKDEKE 281
Cdd:COG1579 102 KRRISD-------LEDEILELMERIEELEEELAELEAELAELEAELEEKKAELDEELAELE 155
|
|
| SMC_prok_A |
TIGR02169 |
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ... |
150-279 |
5.43e-05 |
|
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 46.98 E-value: 5.43e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 150 LELKIEKTMKEKEELLKLIAVLEKETAQLREQVGRMERELNHEKERCDQLQAEQkgltevtqslkmenEEFKKRFSDATS 229
Cdd:TIGR02169 390 YREKLEKLKREINELKRELDRLQEELQRLSEELADLNAAIAGIEAKINELEEEK--------------EDKALEIKKQEW 455
|
90 100 110 120 130
....*....|....*....|....*....|....*....|....*....|
gi 1384071986 230 KAHQLEEDIVSVTHKAIEKETELDSLKDKLKKAQHEREQLECQLKTEKDE 279
Cdd:TIGR02169 456 KLEQLAADLSKYEQELYDLKEEYDRVEKELSKLQRELAEAEAQARASEER 505
|
|
| DUF3584 |
pfam12128 |
Protein of unknown function (DUF3584); This protein is found in bacteria and eukaryotes. ... |
155-462 |
5.47e-05 |
|
Protein of unknown function (DUF3584); This protein is found in bacteria and eukaryotes. Proteins in this family are typically between 943 to 1234 amino acids in length. This family contains a P-loop motif suggesting it is a nucleotide binding protein. It may be involved in replication.
Pssm-ID: 432349 [Multi-domain] Cd Length: 1191 Bit Score: 46.76 E-value: 5.47e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 155 EKTMKEKEELLKLIAV----LEKETAQLREQVGRMERELNHEKERcdqlqaeqkgltevtqsLKMENEEFKKRFSDATSK 230
Cdd:pfam12128 397 DKLAKIREARDRQLAVaeddLQALESELREQLEAGKLEFNEEEYR-----------------LKSRLGELKLRLNQATAT 459
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 231 AHQLEEDIVSVthkaiekeTELDSLKDKLKKAQHEREQLECQLKTEKDEKELYKVHLKNTEIENTKLMSEVQTLKNLDGN 310
Cdd:pfam12128 460 PELLLQLENFD--------ERIERAREEQEAANAEVERLQSELRQARKRRDQASEALRQASRRLEERQSALDELELQLFP 531
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 311 KESVITHF--------KEEIGRlqlcLAEKENLQRTFL---LTTSSKEDTC------------------FLKEQLR---- 357
Cdd:pfam12128 532 QAGTLLHFlrkeapdwEQSIGK----VISPELLHRTDLdpeVWDGSVGGELnlygvkldlkridvpewaASEEELRerld 607
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 358 KAEEQVQATRQEVVFLAKELSDA---VNVRDRTM---------ADLHTARLENEkvKKQLADAVAELKLNAMKKDQDKTD 425
Cdd:pfam12128 608 KAEEALQSAREKQAAAEEQLVQAngeLEKASREEtfartalknARLDLRRLFDE--KQSEKDKKNKALAERKDSANERLN 685
|
330 340 350
....*....|....*....|....*....|....*..
gi 1384071986 426 TLEHELRRevedLKLRLQMAADHYKEKFKEcQRLQKQ 462
Cdd:pfam12128 686 SLEAQLKQ----LDKKHQAWLEEQKEQKRE-ARTEKQ 717
|
|
| HOOK |
pfam05622 |
HOOK protein coiled-coil region; This family consists of several HOOK1, 2 and 3 proteins from ... |
127-455 |
5.86e-05 |
|
HOOK protein coiled-coil region; This family consists of several HOOK1, 2 and 3 proteins from different eukaryotic organizms. The different members of the human gene family are HOOK1, HOOK2 and HOOK3. Different domains have been identified in the three human HOOK proteins, and it was demonstrated that the highly conserved NH2-domain mediates attachment to microtubules, whereas this central coiled-coil motif mediates homodimerization and the more divergent C-terminal domains are involved in binding to specific organelles (organelle-binding domains). It has been demonstrated that endogenous HOOK3 binds to Golgi membranes, whereas both HOOK1 and HOOK2 are localized to discrete but unidentified cellular structures. In mice the Hook1 gene is predominantly expressed in the testis. Hook1 function is necessary for the correct positioning of microtubular structures within the haploid germ cell. Disruption of Hook1 function in mice causes abnormal sperm head shape and fragile attachment of the flagellum to the sperm head. This entry includes the central coiled-coiled domain and the divergent C-terminal domain.
Pssm-ID: 461694 [Multi-domain] Cd Length: 528 Bit Score: 46.61 E-value: 5.86e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 127 EELLTMEDEGNS-----DMLVVTT-KAGLLELKIE---KTMKEKEELLKLIAVLEKETAQLREQVGRMERELNHekercd 197
Cdd:pfam05622 104 EELTSLAEEAQAlkdemDILRESSdKVKKLEATVEtykKKLEDLGDLRRQVKLLEERNAEYMQRTLQLEEELKK------ 177
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 198 qlqaeqkgltevTQSLKMENEEFKKRFSDATSKaHQLEedivsvTHKAIEKETELDSLKDKLKKAQHEREQL--ECQLKT 275
Cdd:pfam05622 178 ------------ANALRGQLETYKRQVQELHGK-LSEE------SKKADKLEFEYKKLEEKLEALQKEKERLiiERDTLR 238
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 276 EKDEkELYKVHLKNTEIENTKLMSEVQTLKNLDGNKESVITHFKEEIGRLQL---CLAEKENLQRTFLLTTS------SK 346
Cdd:pfam05622 239 ETNE-ELRCAQLQQAELSQADALLSPSSDPGDNLAAEIMPAEIREKLIRLQHenkMLRLGQEGSYRERLTELqqlledAN 317
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 347 EDTCFLKEQLRKAEEQVQATRQEVVFLAKELS-------DAVNVR---DRTMADLHTARLENEKVKKQLADAVAELKLNA 416
Cdd:pfam05622 318 RRKNELETQNRLANQRILELQQQVEELQKALQeqgskaeDSSLLKqklEEHLEKLHEAQSELQKKKEQIEELEPKQDSNL 397
|
330 340 350 360
....*....|....*....|....*....|....*....|..
gi 1384071986 417 MKKdqdkTDTLEHELRREVEDLKlrlqMAADHYK---EKFKE 455
Cdd:pfam05622 398 AQK----IDELQEALRKKDEDMK----AMEERYKkyvEKAKS 431
|
|
| Mplasa_alph_rch |
TIGR04523 |
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of ... |
160-596 |
6.40e-05 |
|
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of Mycoplasma species. Members average 750 amino acids in length, including signal peptide. Sequences are predicted (Jpred 3) to be almost entirely alpha-helical. These sequences show strong periodicity (consistent with long alpha helical structures) and low complexity rich in D,E,N,Q, and K. Genes encoding these proteins are often found in tandem. The function is unknown.
Pssm-ID: 275316 [Multi-domain] Cd Length: 745 Bit Score: 46.55 E-value: 6.40e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 160 EKEELLKLIAVLEKETAQLREQVGRMERELNHEKERCDQLQAEQKGLTEVTQSLKMENEEFKKRFSDATSKAHQLEEDIV 239
Cdd:TIGR04523 34 EEKQLEKKLKTIKNELKNKEKELKNLDKNLNKDEEKINNSNNKIKILEQQIKDLNDKLKKNKDKINKLNSDLSKINSEIK 113
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 240 SVTHKAIEKETELDSLKDKLKKaqHEREQLECQLKTEKDEKELYKVHLKNTEIENTK--LMSEVQTLKNLDGNKESVITH 317
Cdd:TIGR04523 114 NDKEQKNKLEVELNKLEKQKKE--NKKNIDKFLTEIKKKEKELEKLNNKYNDLKKQKeeLENELNLLEKEKLNIQKNIDK 191
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 318 FKEEIGRLQLCLaekenlqrTFLLTTSSKEDTcfLKEQLRKAEEQVQATRQEVVFLAKELSDAVNVRDRTMADLHTARLE 397
Cdd:TIGR04523 192 IKNKLLKLELLL--------SNLKKKIQKNKS--LESQISELKKQNNQLKDNIEKKQQEINEKTTEISNTQTQLNQLKDE 261
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 398 NEKVKKQLADAVAELKlNAMKKDQDKTDTLEhELRREVEDLKLrlQMAADHYKEKFKECQRLQKQINKLSDQSANNNNVF 477
Cdd:TIGR04523 262 QNKIKKQLSEKQKELE-QNNKKIKELEKQLN-QLKSEISDLNN--QKEQDWNKELKSELKNQEKKLEEIQNQISQNNKII 337
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 478 T---------KKTGNQQKVNDASVNTDPATSASTV---------------DVKPSPSAAEADFDIVTKgQVCEMTKEIAD 533
Cdd:TIGR04523 338 SqlneqisqlKKELTNSESENSEKQRELEEKQNEIeklkkenqsykqeikNLESQINDLESKIQNQEK-LNQQKDEQIKK 416
|
410 420 430 440 450 460 470
....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 534 KTEKYNKCKQLLQDEKAKCNKYADEL-------AKMELKWKEQVKIAENVKLELAEVQDNYKELKRSLEN 596
Cdd:TIGR04523 417 LQQEKELLEKEIERLKETIIKNNSEIkdltnqdSVKELIIKNLDNTRESLETQLKVLSRSINKIKQNLEQ 486
|
|
| PTZ00121 |
PTZ00121 |
MAEBL; Provisional |
146-603 |
8.13e-05 |
|
MAEBL; Provisional
Pssm-ID: 173412 [Multi-domain] Cd Length: 2084 Bit Score: 46.29 E-value: 8.13e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 146 KAGLLELKIEKTMKEKEELLKLIAVLEK--ETAQLREQVGRMERELNHEKERCDQLQAEQKglTEVTQSLKMENEEfKKR 223
Cdd:PTZ00121 1316 KADEAKKKAEEAKKKADAAKKKAEEAKKaaEAAKAEAEAAADEAEAAEEKAEAAEKKKEEA--KKKADAAKKKAEE-KKK 1392
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 224 FSDATSKAHQLEEDIVSVTHKAIEKEtELDSLKdklKKAQHEREQLECQLKTEKDEK--ELYKVHLKNTEIENTKLMSEV 301
Cdd:PTZ00121 1393 ADEAKKKAEEDKKKADELKKAAAAKK-KADEAK---KKAEEKKKADEAKKKAEEAKKadEAKKKAEEAKKAEEAKKKAEE 1468
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 302 QtlKNLDGNKEsvithfKEEIGRLQLCLAEKENLQRTFLLTTSSKEDTCFLKEQLRKAEEQVQATRQEVVFLAKELSDAV 381
Cdd:PTZ00121 1469 A--KKADEAKK------KAEEAKKADEAKKKAEEAKKKADEAKKAAEAKKKADEAKKAEEAKKADEAKKAEEAKKADEAK 1540
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 382 NVRDRTMAD-LHTArlenEKVKKQLADAVAElklNAMKKDQDKTDTLEH-ELRREVEDLKLRLQMAADHYKEKFKECQRL 459
Cdd:PTZ00121 1541 KAEEKKKADeLKKA----EELKKAEEKKKAE---EAKKAEEDKNMALRKaEEAKKAEEARIEEVMKLYEEEKKMKAEEAK 1613
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 460 QKQINKLSDQSANNNNVFTKKTGNQQKVNDASVNtdpatsastvdvKPSPSAAEADFDIVTKGQVCEMTKEIADKTEKYN 539
Cdd:PTZ00121 1614 KAEEAKIKAEELKKAEEEKKKVEQLKKKEAEEKK------------KAEELKKAEEENKIKAAEEAKKAEEDKKKAEEAK 1681
|
410 420 430 440 450 460
....*....|....*....|....*....|....*....|....*....|....*....|....*..
gi 1384071986 540 KCKQLLQDEKAKCNKYADELAKMEL---KWKEQVKIAENVKLELAEVQDNYKELKRSLENPAERKME 603
Cdd:PTZ00121 1682 KAEEDEKKAAEALKKEAEEAKKAEElkkKEAEEKKKAEELKKAEEENKIKAEEAKKEAEEDKKKAEE 1748
|
|
| COG4913 |
COG4913 |
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown]; |
234-443 |
9.69e-05 |
|
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown];
Pssm-ID: 443941 [Multi-domain] Cd Length: 1089 Bit Score: 46.06 E-value: 9.69e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 234 LEE-DIVSVTHKAIEKETELDSLKDKLKKAQHEREQLEcqlKTEKDEKELYKVHLKNTEIENTKLMSEVQTLKNLDGNKE 312
Cdd:COG4913 218 LEEpDTFEAADALVEHFDDLERAHEALEDAREQIELLE---PIRELAERYAAARERLAELEYLRAALRLWFAQRRLELLE 294
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 313 SVITHFKEEIGRLQlclAEKENLQRTFLLTTSSKEDtcfLKEQLRKAE-EQVQATRQEVVFLAKELSDAVNVRDRTMADL 391
Cdd:COG4913 295 AELEELRAELARLE---AELERLEARLDALREELDE---LEAQIRGNGgDRLEQLEREIERLERELEERERRRARLEALL 368
|
170 180 190 200 210
....*....|....*....|....*....|....*....|....*....|....
gi 1384071986 392 HTARLENEKVKKQLADAVAELK--LNAMKKDQDKTDTLEHELRREVEDLKLRLQ 443
Cdd:COG4913 369 AALGLPLPASAEEFAALRAEAAalLEALEEELEALEEALAEAEAALRDLRRELR 422
|
|
| rad50 |
TIGR00606 |
rad50; All proteins in this family for which functions are known are involvedin recombination, ... |
156-619 |
9.82e-05 |
|
rad50; All proteins in this family for which functions are known are involvedin recombination, recombinational repair, and/or non-homologous end joining.They are components of an exonuclease complex with MRE11 homologs. This family is distantly related to the SbcC family of bacterial proteins.This family is based on the phylogenomic analysis of JA Eisen (1999, Ph.D. Thesis, Stanford University).
Pssm-ID: 129694 [Multi-domain] Cd Length: 1311 Bit Score: 46.19 E-value: 9.82e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 156 KTMKEKEELLKLIAVLEKETAQLREQVGRMERELNHEKE-------RCDQLQAEQKGLTE-VTQSLKMENE--EFKKRFS 225
Cdd:TIGR00606 200 QKVQEHQMELKYLKQYKEKACEIRDQITSKEAQLESSREivksyenELDPLKNRLKEIEHnLSKIMKLDNEikALKSRKK 279
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 226 DATSKAHQLEEDIVSVTHKAIEKETELDSLKDKLKKaQHEREQLECQLKTEKDEKELYKVHLKNTEIENtklmsevqtlk 305
Cdd:TIGR00606 280 QMEKDNSELELKMEKVFQGTDEQLNDLYHNHQRTVR-EKERELVDCQRELEKLNKERRLLNQEKTELLV----------- 347
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 306 nldgnkesvithfkeEIGRLQL------CLAEKENLQRTFLLTTSSK---EDTCFLKEQLRKAEEQVQatrqevvflaKE 376
Cdd:TIGR00606 348 ---------------EQGRLQLqadrhqEHIRARDSLIQSLATRLELdgfERGPFSERQIKNFHTLVI----------ER 402
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 377 LSDAVNVRDRTMADLHtarlENEKVKKQLADAVAELKLNAMKKDQDKTDTLEHElRREVEDLKLRLQMAADHYKEKFKEC 456
Cdd:TIGR00606 403 QEDEAKTAAQLCADLQ----SKERLKQEQADEIRDEKKGLGRTIELKKEILEKK-QEELKFVIKELQQLEGSSDRILELD 477
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 457 QRLQKQINKLSDQSANNNNVFTKKTGNQQKVNDASVNTDPAtsastvdvKPSPSAAEADFDIVTKGQVCEMTKEIADKTE 536
Cdd:TIGR00606 478 QELRKAERELSKAEKNSLTETLKKEVKSLQNEKADLDRKLR--------KLDQEMEQLNHHTTTRTQMEMLTKDKMDKDE 549
|
410 420 430 440 450 460 470 480
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 537 KYNKCKQLLQDEKAKCNKYADELAKMELKWKEQVKIAENVKLELAEVQDNYKEL---KRSLENPAERKMEGQNSQSPQCF 613
Cdd:TIGR00606 550 QIRKIKSRHSDELTSLLGYFPNKKQLEDWLHSKSKEINQTRDRLAKLNKELASLeqnKNHINNELESKEEQLSSYEDKLF 629
|
....*.
gi 1384071986 614 KTCSEQ 619
Cdd:TIGR00606 630 DVCGSQ 635
|
|
| DR0291 |
COG1579 |
Predicted nucleic acid-binding protein DR0291, contains C4-type Zn-ribbon domain [General ... |
150-279 |
1.02e-04 |
|
Predicted nucleic acid-binding protein DR0291, contains C4-type Zn-ribbon domain [General function prediction only];
Pssm-ID: 441187 [Multi-domain] Cd Length: 236 Bit Score: 44.53 E-value: 1.02e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 150 LELKIEKTMKEKEELLKLIAVLEKETAQLREQVGRMERELNHEKERCDQLQA---------EQKGLTEVTQSLKMENEEF 220
Cdd:COG1579 29 LPAELAELEDELAALEARLEAAKTELEDLEKEIKRLELEIEEVEARIKKYEEqlgnvrnnkEYEALQKEIESLKRRISDL 108
|
90 100 110 120 130
....*....|....*....|....*....|....*....|....*....|....*....
gi 1384071986 221 KKRFSDATSKAHQLEEDIVSVTHKAIEKETELDSLKDKLKKAQHEREQLECQLKTEKDE 279
Cdd:COG1579 109 EDEILELMERIEELEEELAELEAELAELEAELEEKKAELDEELAELEAELEELEAEREE 167
|
|
| HMMR_N |
pfam15905 |
Hyaluronan mediated motility receptor N-terminal; HMMR_N is the N-terminal region of ... |
114-296 |
1.23e-04 |
|
Hyaluronan mediated motility receptor N-terminal; HMMR_N is the N-terminal region of eukaryotic hyaluronan-mediated motility receptor proteins. The protein is functionally associated with BRCA1 and thus predicted to be a common, low-penetrance breast cancer candidate.
Pssm-ID: 464932 [Multi-domain] Cd Length: 329 Bit Score: 44.80 E-value: 1.23e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 114 ASTPFQFRASSPVEELLTMEDEGNSDMLVVTTKAGLLELKIEKTMKEKEELlkliavlEKETAQLREQVGRMERELNHEK 193
Cdd:pfam15905 146 SEDGTQKKMSSLSMELMKLRNKLEAKMKEVMAKQEGMEGKLQVTQKNLEHS-------KGKVAQLEEKLVSTEKEKIEEK 218
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 194 ERCDQLQAEQKGLTEVTQSLKMENEEFKKRFSDATSKAHQLEEDIVSVTHKAIEKETELDSLKDKLKKAQHEREQLEcql 273
Cdd:pfam15905 219 SETEKLLEYITELSCVSEQVEKYKLDIAQLEELLKEKNDEIESLKQSLEEKEQELSKQIKDLNEKCKLLESEKEELL--- 295
|
170 180
....*....|....*....|...
gi 1384071986 274 kTEKDEKElykvHLKNTEIENTK 296
Cdd:pfam15905 296 -REYEEKE----QTLNAELEELK 313
|
|
| DR0291 |
COG1579 |
Predicted nucleic acid-binding protein DR0291, contains C4-type Zn-ribbon domain [General ... |
157-322 |
1.26e-04 |
|
Predicted nucleic acid-binding protein DR0291, contains C4-type Zn-ribbon domain [General function prediction only];
Pssm-ID: 441187 [Multi-domain] Cd Length: 236 Bit Score: 44.15 E-value: 1.26e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 157 TMKEKEELLKLIAVLEKETAQLREQVGRMERELNHEKERCDQLQAEQKGLTEVTQSLKMENEEFKKRFSDATSKAHQLEE 236
Cdd:COG1579 1 AMPEDLRALLDLQELDSELDRLEHRLKELPAELAELEDELAALEARLEAAKTELEDLEKEIKRLELEIEEVEARIKKYEE 80
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 237 DIVSVT----HKAIEKE-----TELDSLKDKLKKAQHEREQLECQLKTEKDEKELYKVHLKNTEIENTKLMSEVQT-LKN 306
Cdd:COG1579 81 QLGNVRnnkeYEALQKEieslkRRISDLEDEILELMERIEELEEELAELEAELAELEAELEEKKAELDEELAELEAeLEE 160
|
170
....*....|....*.
gi 1384071986 307 LDGNKESVITHFKEEI 322
Cdd:COG1579 161 LEAEREELAAKIPPEL 176
|
|
| Mplasa_alph_rch |
TIGR04523 |
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of ... |
150-596 |
1.41e-04 |
|
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of Mycoplasma species. Members average 750 amino acids in length, including signal peptide. Sequences are predicted (Jpred 3) to be almost entirely alpha-helical. These sequences show strong periodicity (consistent with long alpha helical structures) and low complexity rich in D,E,N,Q, and K. Genes encoding these proteins are often found in tandem. The function is unknown.
Pssm-ID: 275316 [Multi-domain] Cd Length: 745 Bit Score: 45.40 E-value: 1.41e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 150 LELKIEKTMKEKEELLKLIAVLEKETAQLREQVGRMERELNHEKErcdQLQAEQKGLTeVTQSLKMENEEFKKRFSDATS 229
Cdd:TIGR04523 150 KEKELEKLNNKYNDLKKQKEELENELNLLEKEKLNIQKNIDKIKN---KLLKLELLLS-NLKKKIQKNKSLESQISELKK 225
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 230 KAHQLEEDIVSVTHKAIEKETELDSLKDKLKKAQHEREQLECQLKTEKDEKELYKVHLKNTEIENTKLMSEVQTLKNldg 309
Cdd:TIGR04523 226 QNNQLKDNIEKKQQEINEKTTEISNTQTQLNQLKDEQNKIKKQLSEKQKELEQNNKKIKELEKQLNQLKSEISDLNN--- 302
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 310 NKESVIT-HFKEEIgrlqlclaekenlqrtflltTSSKEDTCFLKEQLRKAEEQVQATRQEVVFLAKELSDAVNvrdrtm 388
Cdd:TIGR04523 303 QKEQDWNkELKSEL--------------------KNQEKKLEEIQNQISQNNKIISQLNEQISQLKKELTNSES------ 356
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 389 adlhtarlENEKVKKQLADAVAELKlNAMKKDQDKTDTLEhELRREVEDLKLRLQMAADHYKEKFKECQRLQKQINKLSD 468
Cdd:TIGR04523 357 --------ENSEKQRELEEKQNEIE-KLKKENQSYKQEIK-NLESQINDLESKIQNQEKLNQQKDEQIKKLQQEKELLEK 426
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 469 QSANnnnvfTKKTGNQQkvndasvntdpatsastvdvkpspsaaeadfdivtKGQVCEMTKEIADKTEKYNKCKQLLQDE 548
Cdd:TIGR04523 427 EIER-----LKETIIKN-----------------------------------NSEIKDLTNQDSVKELIIKNLDNTRESL 466
|
410 420 430 440
....*....|....*....|....*....|....*....|....*...
gi 1384071986 549 KAKCNKYADELAKMELKWKEQVKIAENVKLELAEVQDNYKELKRSLEN 596
Cdd:TIGR04523 467 ETQLKVLSRSINKIKQNLEQKQKELKSKEKELKKLNEEKKELEEKVKD 514
|
|
| SMC_prok_A |
TIGR02169 |
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ... |
150-300 |
1.49e-04 |
|
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 45.44 E-value: 1.49e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 150 LELKIEKTMKEKEELLKLIAVLEKETAQLREQVGRMERELNhekercdQLQAEQKGLTEVTQSLKMENEEFKKRFSDATS 229
Cdd:TIGR02169 362 LKEELEDLRAELEEVDKEFAETRDELKDYREKLEKLKREIN-------ELKRELDRLQEELQRLSEELADLNAAIAGIEA 434
|
90 100 110 120 130 140 150
....*....|....*....|....*....|....*....|....*....|....*....|....*....|.
gi 1384071986 230 KAHQLEEDIVSVTHKAIEKETELDSLKDKLKKAQHEREQLECQLktEKDEKELYKVHLKNTEIENTKLMSE 300
Cdd:TIGR02169 435 KINELEEEKEDKALEIKKQEWKLEQLAADLSKYEQELYDLKEEY--DRVEKELSKLQRELAEAEAQARASE 503
|
|
| HMMR_N |
pfam15905 |
Hyaluronan mediated motility receptor N-terminal; HMMR_N is the N-terminal region of ... |
135-403 |
1.91e-04 |
|
Hyaluronan mediated motility receptor N-terminal; HMMR_N is the N-terminal region of eukaryotic hyaluronan-mediated motility receptor proteins. The protein is functionally associated with BRCA1 and thus predicted to be a common, low-penetrance breast cancer candidate.
Pssm-ID: 464932 [Multi-domain] Cd Length: 329 Bit Score: 44.42 E-value: 1.91e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 135 EGNSDMLVVTTKAGLLELKieKTMKEKEELLKLIAVLEKETAQLREQVGRMERELNHEKERCDQLQA-------EQKGLT 207
Cdd:pfam15905 44 SKDASTPATARKVKSLELK--KKSQKNLKESKDQKELEKEIRALVQERGEQDKRLQALEEELEKVEAklnaavrEKTSLS 121
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 208 EVTQSLKME-------NEEFKKRFSDATSKA-------------HQLEEDIVSVTHKAIEKETELDSLKDKLKKAQHERE 267
Cdd:pfam15905 122 ASVASLEKQlleltrvNELLKAKFSEDGTQKkmsslsmelmklrNKLEAKMKEVMAKQEGMEGKLQVTQKNLEHSKGKVA 201
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 268 QLECQLKTEKDEKELYKVHLKNTEIENTKLMSEVQTLKNldgnkesvithFKEEIGRLQLCLAEKEnlQRTFLLTTSSKE 347
Cdd:pfam15905 202 QLEEKLVSTEKEKIEEKSETEKLLEYITELSCVSEQVEK-----------YKLDIAQLEELLKEKN--DEIESLKQSLEE 268
|
250 260 270 280 290
....*....|....*....|....*....|....*....|....*....|....*..
gi 1384071986 348 DTCFLKEQLRKAEEQVQATRQEVVFLAKELSDAVNVRDRTMADL-HTARLENEKVKK 403
Cdd:pfam15905 269 KEQELSKQIKDLNEKCKLLESEKEELLREYEEKEQTLNAELEELkEKLTLEEQEHQK 325
|
|
| YhaN |
COG4717 |
Uncharacterized conserved protein YhaN, contains AAA domain [Function unknown]; |
153-469 |
1.97e-04 |
|
Uncharacterized conserved protein YhaN, contains AAA domain [Function unknown];
Pssm-ID: 443752 [Multi-domain] Cd Length: 641 Bit Score: 44.76 E-value: 1.97e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 153 KIEKTMKEKEELLKLIAVLEKETAQLREQVGRMERELNHEKERCDQLQAEQK--GLTEVTQSLKMENEEFKKRFSDATSK 230
Cdd:COG4717 75 ELEEELKEAEEKEEEYAELQEELEELEEELEELEAELEELREELEKLEKLLQllPLYQELEALEAELAELPERLEELEER 154
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 231 A---HQLEEDIVSVTHKAIEKETELDSLKDKLKKAQHER-EQLECQLKTEKDEKELYKVHLKNTEIENTKLMSEVQTLKN 306
Cdd:COG4717 155 LeelRELEEELEELEAELAELQEELEELLEQLSLATEEElQDLAEELEELQQRLAELEEELEEAQEELEELEEELEQLEN 234
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 307 --------------------------LDGNKESVITHFKEEIGRLQLCLA----EKENLQRTFLLTTSSKEDTCFLKEQL 356
Cdd:COG4717 235 eleaaaleerlkearlllliaaallaLLGLGGSLLSLILTIAGVLFLVLGllalLFLLLAREKASLGKEAEELQALPALE 314
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 357 RKAEEQVQATRQEVVFLAKELSDAVNVRDRTMADLHTARLENEKVKKQLADAVAELKLNAMKKDQDKTDtlEHELRREVe 436
Cdd:COG4717 315 ELEEEELEELLAALGLPPDLSPEELLELLDRIEELQELLREAEELEEELQLEELEQEIAALLAEAGVED--EEELRAAL- 391
|
330 340 350
....*....|....*....|....*....|...
gi 1384071986 437 dlklrlqmaadhykEKFKECQRLQKQINKLSDQ 469
Cdd:COG4717 392 --------------EQAEEYQELKEELEELEEQ 410
|
|
| ADIP |
pfam11559 |
Afadin- and alpha -actinin-Binding; This family is found in mammals where it is localized at ... |
131-261 |
2.09e-04 |
|
Afadin- and alpha -actinin-Binding; This family is found in mammals where it is localized at cell-cell adherens junctions, and in Sch. pombe and other fungi where it anchors spindle-pole bodies to spindle microtubules. It is a coiled-coil structure, and in pombe, it is required for anchoring the minus end of spindle microtubules to the centrosome equivalent, the spindle-pole body. The name ADIP derives from the family being composed of Afadin- and alpha -Actinin-Binding Proteins localized at Cell-Cell Adherens Junctions.
Pssm-ID: 463295 [Multi-domain] Cd Length: 151 Bit Score: 42.30 E-value: 2.09e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 131 TMEDEGNSDMLVVTTKAGLLeLKIEKTMKEKEELLKLIAVLE-------KETAQLREQVGRMERELNHEKERCDQLQAEQ 203
Cdd:pfam11559 25 TAEGVEENIARIINVIYELL-QQRDRDLEFRESLNETIRTLEaeierlqSKIERLKTQLEDLERELALLQAKERQLEKKL 103
|
90 100 110 120 130
....*....|....*....|....*....|....*....|....*....|....*...
gi 1384071986 204 KGLtevTQSLKMENEEFKKRFSDATSKAHQLeedivsvTHKAIEKETELDSLKDKLKK 261
Cdd:pfam11559 104 KTL---EQKLKNEKEELQRLKNALQQIKTQF-------AHEVKKRDREIEKLKERLAQ 151
|
|
| Zn-C2H2_CALCOCO2 |
cd21968 |
C2H2-type zinc binding domain found in calcium-binding and coiled-coil domain-containing ... |
745-772 |
2.43e-04 |
|
C2H2-type zinc binding domain found in calcium-binding and coiled-coil domain-containing protein 2 (CALCOCO2) and similar proteins; CALCOCO2, also called antigen nuclear dot 52 kDa protein, or nuclear domain 10 protein NDP52, or nuclear domain 10 protein 52, or nuclear dot protein 52, is an Xenophagy-specific receptor required for autophagy-mediated intracellular bacteria degradation. It acts as an effector protein of galectin-sensed membrane damage that restricts the proliferation of infecting pathogens such as Salmonella typhimurium upon entry into the cytosol by targeting LGALS8-associated bacteria for autophagy. It may play a role in ruffle formation and actin cytoskeleton organization and seems to negatively regulate constitutive secretion. CALCOCO2 contains a C2H2-type zinc binding domain.
Pssm-ID: 412014 Cd Length: 27 Bit Score: 38.97 E-value: 2.43e-04
10 20
....*....|....*....|....*...
gi 1384071986 745 KVCPMCSEQFPpDYDQQVFERHVQTHFD 772
Cdd:cd21968 1 FECPICSKIFE-ATSKQEFEDHVFCHSL 27
|
|
| Zn-C2H2_spn-F |
cd21971 |
C2H2-type zinc binding domain found in Drosophila melanogaster Spindle-F (Spn-F) and similar ... |
745-772 |
2.61e-04 |
|
C2H2-type zinc binding domain found in Drosophila melanogaster Spindle-F (Spn-F) and similar proteins; spn-F is the central mediator of IK2 kinase-dependent dendrite pruning in drosophila sensory neurons. It acts downstream of IKK-related kinase Ik2 in the same pathway for dendrite pruning. Spn-F is a coil-coiled protein containing a C2H2-type zinc binding domain.
Pssm-ID: 412017 Cd Length: 30 Bit Score: 38.66 E-value: 2.61e-04
10 20
....*....|....*....|....*...
gi 1384071986 745 KVCPMCSEQFPPDYDQQVFERHVQTHFD 772
Cdd:cd21971 2 RTCPMCGKQFSDQVSFHEFREHVEMHFI 29
|
|
| PRK02224 |
PRK02224 |
DNA double-strand break repair Rad50 ATPase; |
145-469 |
2.72e-04 |
|
DNA double-strand break repair Rad50 ATPase;
Pssm-ID: 179385 [Multi-domain] Cd Length: 880 Bit Score: 44.65 E-value: 2.72e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 145 TKAGLLELKIEKTMKEKEELLKLIAVLEKETAQLREQVGRMERELNHEKERCDQLQaeqkgltevtqSLKMENEEFKKRF 224
Cdd:PRK02224 185 QRGSLDQLKAQIEEKEEKDLHERLNGLESELAELDEEIERYEEQREQARETRDEAD-----------EVLEEHEERREEL 253
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 225 SDatskahqLEEDIVSVTHKAIEKETELDSLKDKLKKAQHEREQLECQL-----KTEKDEKELYKVHLKNTEIENTK--L 297
Cdd:PRK02224 254 ET-------LEAEIEDLRETIAETEREREELAEEVRDLRERLEELEEERddllaEAGLDDADAEAVEARREELEDRDeeL 326
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 298 MSEVQTLKNLDGNKESVITHFKEEIGRLQLCLAEKENLQRTFlltTSSKEDTcflKEQLRKAEEQVQATRQEVVFLAKEL 377
Cdd:PRK02224 327 RDRLEECRVAAQAHNEEAESLREDADDLEERAEELREEAAEL---ESELEEA---REAVEDRREEIEELEEEIEELRERF 400
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 378 SDAVNVRDRTMADLHTARLENEKVKKQLADAVAELK------------LNAMK--------KDQDKTDTLEH------EL 431
Cdd:PRK02224 401 GDAPVDLGNAEDFLEELREERDELREREAELEATLRtarerveeaealLEAGKcpecgqpvEGSPHVETIEEdrerveEL 480
|
330 340 350
....*....|....*....|....*....|....*...
gi 1384071986 432 RREVEDLKLRlQMAADHYKEKFKECQRLQKQINKLSDQ 469
Cdd:PRK02224 481 EAELEDLEEE-VEEVEERLERAEDLVEAEDRIERLEER 517
|
|
| PTZ00121 |
PTZ00121 |
MAEBL; Provisional |
151-333 |
3.55e-04 |
|
MAEBL; Provisional
Pssm-ID: 173412 [Multi-domain] Cd Length: 2084 Bit Score: 44.36 E-value: 3.55e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 151 ELKIEKTMKEKEELLKLIAVLEKEtaQLREQVGRMERELNHEKERCDQLQAEQKGLTEVTQSLKMENEEFKKRFSDATSk 230
Cdd:PTZ00121 1606 KMKAEEAKKAEEAKIKAEELKKAE--EEKKKVEQLKKKEAEEKKKAEELKKAEEENKIKAAEEAKKAEEDKKKAEEAKK- 1682
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 231 ahqlEEDIVSVTHKAIEKETELDSLKDKLKKAQHEREQLECQLKTEKDEKELYKVHLKNTEIENTKLMSEvqtLKNLDGN 310
Cdd:PTZ00121 1683 ----AEEDEKKAAEALKKEAEEAKKAEELKKKEAEEKKKAEELKKAEEENKIKAEEAKKEAEEDKKKAEE---AKKDEEE 1755
|
170 180
....*....|....*....|...
gi 1384071986 311 KESVITHFKEEIGRLQLCLAEKE 333
Cdd:PTZ00121 1756 KKKIAHLKKEEEKKAEEIRKEKE 1778
|
|
| SMC_prok_A |
TIGR02169 |
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ... |
192-595 |
3.90e-04 |
|
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 44.29 E-value: 3.90e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 192 EKERCDQLQAEQKGLTEVTQSLKMENEEFKKRFSDATSKAHQLEEDIVsvthkaiEKETELDSLKDKLKKAQHEREQLEC 271
Cdd:TIGR02169 672 EPAELQRLRERLEGLKRELSSLQSELRRIENRLDELSQELSDASRKIG-------EIEKEIEQLEQEEEKLKERLEELEE 744
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 272 QLKTEKDEKELYKvhlknteientklmSEVQTLknldgnkESVITHFKEEIGRLQLCLAEKENlqrtfllttsskedtcf 351
Cdd:TIGR02169 745 DLSSLEQEIENVK--------------SELKEL-------EARIEELEEDLHKLEEALNDLEA----------------- 786
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 352 lkeqlRKAEEQVQATRQEVVFLAKELSDAvnvrdrtmaDLHTARLENEKVKKQLADAVAELKLNAMKKDQDKTDTLEHEL 431
Cdd:TIGR02169 787 -----RLSHSRIPEIQAELSKLEEEVSRI---------EARLREIEQKLNRLTLEKEYLEKEIQELQEQRIDLKEQIKSI 852
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 432 RREVEDLKLRLQmaadhykEKFKECQRLQKQINKLSDQSANnnnvftkktgnqqkvndasvntdpatsastvdvkpspsa 511
Cdd:TIGR02169 853 EKEIENLNGKKE-------ELEEELEELEAALRDLESRLGD--------------------------------------- 886
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 512 AEADFDIVtKGQVCEMTKEIADKTEKYNKCKQLLQDEKAKCNKYADELAKMELKWKEQVKIAENVkLELAEVQDNYKELK 591
Cdd:TIGR02169 887 LKKERDEL-EAQLRELERKIEELEAQIEKKRKRLSELKAKLEALEEELSEIEDPKGEDEEIPEEE-LSLEDVQAELQRVE 964
|
....
gi 1384071986 592 RSLE 595
Cdd:TIGR02169 965 EEIR 968
|
|
| DR0291 |
COG1579 |
Predicted nucleic acid-binding protein DR0291, contains C4-type Zn-ribbon domain [General ... |
247-411 |
4.10e-04 |
|
Predicted nucleic acid-binding protein DR0291, contains C4-type Zn-ribbon domain [General function prediction only];
Pssm-ID: 441187 [Multi-domain] Cd Length: 236 Bit Score: 42.60 E-value: 4.10e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 247 EKETELDSLKDKLKKAQHEREQLECQLKTEKDEKELYKVHLKNTEIENTKLMSEVQT-----------LKNLDGNKEsvI 315
Cdd:COG1579 14 ELDSELDRLEHRLKELPAELAELEDELAALEARLEAAKTELEDLEKEIKRLELEIEEvearikkyeeqLGNVRNNKE--Y 91
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 316 THFKEEIGRLQLCLAEKENLQRTFLlttsskedtcflkEQLRKAEEQVQATRQEVVFLAKELSDAVNVRDRTMADLHTAR 395
Cdd:COG1579 92 EALQKEIESLKRRISDLEDEILELM-------------ERIEELEEELAELEAELAELEAELEEKKAELDEELAELEAEL 158
|
170
....*....|....*.
gi 1384071986 396 LENEKVKKQLADAVAE 411
Cdd:COG1579 159 EELEAEREELAAKIPP 174
|
|
| Zn-C2H2_CALCOCO1 |
cd21967 |
C2H2-type zinc binding domain found in calcium-binding and coiled-coil domain-containing ... |
745-771 |
4.11e-04 |
|
C2H2-type zinc binding domain found in calcium-binding and coiled-coil domain-containing protein 1 (CALCOCO1) and similar proteins; CALCOCO1, also called calphoglin, or coiled-coil coactivator protein, or Sarcoma antigen NY-SAR-3, functions as a coactivator for aryl hydrocarbon and nuclear receptors (NR). It is recruited to promoters through its contact with the N-terminal basic helix-loop-helix-Per-Arnt-Sim (PAS) domain of transcription factors or coactivators, such as NCOA2. During ER-activation CALCOCO1 acts synergistically in combination with other NCOA2-binding proteins, such as EP300, CREBBP and CARM1. It is involved in the transcriptional activation of target genes in the Wnt/CTNNB1 pathway. It functions as a secondary coactivator in LEF1-mediated transcriptional activation via its interaction with CTNNB1. In association with CCAR1, CALCOCO1 enhances GATA1- and MED1-mediated transcriptional activation from the gamma-globin promoter during erythroid differentiation of K562 erythroleukemia cells. CALCOCO1 contains a C2H2-type zinc binding domain.
Pssm-ID: 412013 Cd Length: 29 Bit Score: 38.25 E-value: 4.11e-04
10 20
....*....|....*....|....*..
gi 1384071986 745 KVCPMCSEQFPPDYDQQVFERHVQTHF 771
Cdd:cd21967 1 KECPICKERFPLECDKDALEDHIDSHF 27
|
|
| PTZ00121 |
PTZ00121 |
MAEBL; Provisional |
153-595 |
4.43e-04 |
|
MAEBL; Provisional
Pssm-ID: 173412 [Multi-domain] Cd Length: 2084 Bit Score: 43.98 E-value: 4.43e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 153 KIEKTMKEKEELLKLIAVLEKETAQLREQVGRMERELNHEKERCDQLQAEQKGLTEVTQSLKMENeefkKRFSDATSKAH 232
Cdd:PTZ00121 1110 KAEEARKAEEAKKKAEDARKAEEARKAEDARKAEEARKAEDAKRVEIARKAEDARKAEEARKAED----AKKAEAARKAE 1185
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 233 QLEedivsvthKAIEKETELDSLK-DKLKKAQHEREQLEC-QLKTEKDEKELYKVHLKNTEIENTKLMSEVQTLKNLDGN 310
Cdd:PTZ00121 1186 EVR--------KAEELRKAEDARKaEAARKAEEERKAEEArKAEDAKKAEAVKKAEEAKKDAEEAKKAEEERNNEEIRKF 1257
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 311 KESVITHFKEEIGRLQlcLAEKENLQRTFLLTTSSKEDTCFLKEQLRKAEEQVQAT--RQEVVFLAKELSDAVNVRDRTM 388
Cdd:PTZ00121 1258 EEARMAHFARRQAAIK--AEEARKADELKKAEEKKKADEAKKAEEKKKADEAKKKAeeAKKADEAKKKAEEAKKKADAAK 1335
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 389 ADLHTARLENEKVKKQLADAVAELKLNAMKKDQDKTDTLEHELRREVEDLKLRLQMAADHYKEKFKECQRLQKQINKLSD 468
Cdd:PTZ00121 1336 KKAEEAKKAAEAAKAEAEAAADEAEAAEEKAEAAEKKKEEAKKKADAAKKKAEEKKKADEAKKKAEEDKKKADELKKAAA 1415
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 469 QSANNNNVfTKKTGNQQKVNDASVNTDPATSASTVDVKPSPS-AAEADFDIVTKGQVCEMTKEIADKTEKYNKCKQLLQD 547
Cdd:PTZ00121 1416 AKKKADEA-KKKAEEKKKADEAKKKAEEAKKADEAKKKAEEAkKAEEAKKKAEEAKKADEAKKKAEEAKKADEAKKKAEE 1494
|
410 420 430 440 450 460
....*....|....*....|....*....|....*....|....*....|....*....|..
gi 1384071986 548 EKAKCN---------KYADELAKMELKWK-EQVKIAENVK----LELAEVQDNYKELKRSLE 595
Cdd:PTZ00121 1495 AKKKADeakkaaeakKKADEAKKAEEAKKaDEAKKAEEAKkadeAKKAEEKKKADELKKAEE 1556
|
|
| DUF3584 |
pfam12128 |
Protein of unknown function (DUF3584); This protein is found in bacteria and eukaryotes. ... |
165-447 |
4.46e-04 |
|
Protein of unknown function (DUF3584); This protein is found in bacteria and eukaryotes. Proteins in this family are typically between 943 to 1234 amino acids in length. This family contains a P-loop motif suggesting it is a nucleotide binding protein. It may be involved in replication.
Pssm-ID: 432349 [Multi-domain] Cd Length: 1191 Bit Score: 44.06 E-value: 4.46e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 165 LKLIAVLEKETAQLREQvgrMERELNHEKERCDQLQAEQKGLTEVTQSLKMENEEFKKRFSDATSKAHQLEEDIVSVThk 244
Cdd:pfam12128 585 LDLKRIDVPEWAASEEE---LRERLDKAEEALQSAREKQAAAEEQLVQANGELEKASREETFARTALKNARLDLRRLF-- 659
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 245 aIEKETELD----SLKDKLKKAQHEREQLECQLKTEKDEKELYKVHLKNTEIENTklMSEVQTLKNLDGNKESVITHFKE 320
Cdd:pfam12128 660 -DEKQSEKDkknkALAERKDSANERLNSLEAQLKQLDKKHQAWLEEQKEQKREAR--TEKQAYWQVVEGALDAQLALLKA 736
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 321 EIGRLQLCL-AEKENLQRTFLLTTSSK---EDTCF-LKEQLRKAE---EQVQATRQEV----VFLAKELSDAvnvRDRTM 388
Cdd:pfam12128 737 AIAARRSGAkAELKALETWYKRDLASLgvdPDVIAkLKREIRTLErkiERIAVRRQEVlryfDWYQETWLQR---RPRLA 813
|
250 260 270 280 290 300
....*....|....*....|....*....|....*....|....*....|....*....|.
gi 1384071986 389 ADLHTARLENEKVKKQLADAVAELKLN--AMKKDQDKTDTLEHELRREVEDLKLRLQMAAD 447
Cdd:pfam12128 814 TQLSNIERAISELQQQLARLIADTKLRraKLEMERKASEKQQVRLSENLRGLRCEMSKLAT 874
|
|
| HOOK |
pfam05622 |
HOOK protein coiled-coil region; This family consists of several HOOK1, 2 and 3 proteins from ... |
188-471 |
4.78e-04 |
|
HOOK protein coiled-coil region; This family consists of several HOOK1, 2 and 3 proteins from different eukaryotic organizms. The different members of the human gene family are HOOK1, HOOK2 and HOOK3. Different domains have been identified in the three human HOOK proteins, and it was demonstrated that the highly conserved NH2-domain mediates attachment to microtubules, whereas this central coiled-coil motif mediates homodimerization and the more divergent C-terminal domains are involved in binding to specific organelles (organelle-binding domains). It has been demonstrated that endogenous HOOK3 binds to Golgi membranes, whereas both HOOK1 and HOOK2 are localized to discrete but unidentified cellular structures. In mice the Hook1 gene is predominantly expressed in the testis. Hook1 function is necessary for the correct positioning of microtubular structures within the haploid germ cell. Disruption of Hook1 function in mice causes abnormal sperm head shape and fragile attachment of the flagellum to the sperm head. This entry includes the central coiled-coiled domain and the divergent C-terminal domain.
Pssm-ID: 461694 [Multi-domain] Cd Length: 528 Bit Score: 43.52 E-value: 4.78e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 188 ELNHEKE----RCDQLQAEQKGLTEVTQSLKMENEEFKKRFSdatskahQLE--EDIVSVTH-KAIEKETELDSLKDKLK 260
Cdd:pfam05622 4 EAQEEKDelaqRCHELDQQVSLLQEEKNSLQQENKKLQERLD-------QLEsgDDSGTPGGkKYLLLQKQLEQLQEENF 76
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 261 KAQHEREQLecQLKTEKDEKELYKVHLKNTEIenTKLMSEVQTLknldgnkesvithfKEEIGRLQLClAEKENLQRTFL 340
Cdd:pfam05622 77 RLETARDDY--RIKCEELEKEVLELQHRNEEL--TSLAEEAQAL--------------KDEMDILRES-SDKVKKLEATV 137
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 341 LTTSSK-EDTCFLKEQLRKAEEQVQATRQEVVFLAKELSDAVNVRD------RTMADLHtARLENEKVKkqladavAELK 413
Cdd:pfam05622 138 ETYKKKlEDLGDLRRQVKLLEERNAEYMQRTLQLEEELKKANALRGqletykRQVQELH-GKLSEESKK-------ADKL 209
|
250 260 270 280 290
....*....|....*....|....*....|....*....|....*....|....*...
gi 1384071986 414 LNAMKKDQDKTDTLEHElrrevedlKLRLQMAADHYKEKFKECQRLQKQINKLSDQSA 471
Cdd:pfam05622 210 EFEYKKLEEKLEALQKE--------KERLIIERDTLRETNEELRCAQLQQAELSQADA 259
|
|
| COG4372 |
COG4372 |
Uncharacterized protein, contains DUF3084 domain [Function unknown]; |
159-493 |
4.78e-04 |
|
Uncharacterized protein, contains DUF3084 domain [Function unknown];
Pssm-ID: 443500 [Multi-domain] Cd Length: 370 Bit Score: 43.35 E-value: 4.78e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 159 KEKEELLKLIAVLEKETAQLREQVGRMERELNHEKErcdQLQAEQKGLTEVTQSLKMENEEFKKRFSDATSKAHQLEEdi 238
Cdd:COG4372 31 EQLRKALFELDKLQEELEQLREELEQAREELEQLEE---ELEQARSELEQLEEELEELNEQLQAAQAELAQAQEELES-- 105
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 239 vsvthkaieKETELDSLKDKLKKAQHEREQLECQLKtekdekelykvhlknteientKLMSEVQTLKNLDGNKESVITHF 318
Cdd:COG4372 106 ---------LQEEAEELQEELEELQKERQDLEQQRK---------------------QLEAQIAELQSEIAEREEELKEL 155
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 319 KEEIGRLQLCLAEKENLQRTFLLTTSSKEDTCFLKEQLRKAEEQVQATRQEVVFLAKELSDAVNVRDRTMADLHTARLEN 398
Cdd:COG4372 156 EEQLESLQEELAALEQELQALSEAEAEQALDELLKEANRNAEKEEELAEAEKLIESLPRELAEELLEAKDSLEAKLGLAL 235
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 399 EKVKKQLADAVAELKLNAMKKDQDKTDTLEHELRREVEDLKLRLQMAADHYK-EKFKECQRLQKQINKLSDQSANNNNVF 477
Cdd:COG4372 236 SALLDALELEEDKEELLEEVILKEIEELELAILVEKDTEEEELEIAALELEAlEEAALELKLLALLLNLAALSLIGALED 315
|
330
....*....|....*.
gi 1384071986 478 TKKTGNQQKVNDASVN 493
Cdd:COG4372 316 ALLAALLELAKKLELA 331
|
|
| DR0291 |
COG1579 |
Predicted nucleic acid-binding protein DR0291, contains C4-type Zn-ribbon domain [General ... |
152-281 |
5.84e-04 |
|
Predicted nucleic acid-binding protein DR0291, contains C4-type Zn-ribbon domain [General function prediction only];
Pssm-ID: 441187 [Multi-domain] Cd Length: 236 Bit Score: 42.22 E-value: 5.84e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 152 LKIEKTMKEKEELLKLIAVLEKETAQLREQVGRMERELNHEKERCDQLQAEQKGLTEVTQSLKMENEEFKKRFSDATS-- 229
Cdd:COG1579 10 LDLQELDSELDRLEHRLKELPAELAELEDELAALEARLEAAKTELEDLEKEIKRLELEIEEVEARIKKYEEQLGNVRNnk 89
|
90 100 110 120 130
....*....|....*....|....*....|....*....|....*....|....*....
gi 1384071986 230 --KAHQ-----LEEDIVSVTHKAIEKETELDSLKDKLKKAQHEREQLECQLKTEKDEKE 281
Cdd:COG1579 90 eyEALQkeiesLKRRISDLEDEILELMERIEELEEELAELEAELAELEAELEEKKAELD 148
|
|
| YhaN |
COG4717 |
Uncharacterized conserved protein YhaN, contains AAA domain [Function unknown]; |
218-414 |
5.89e-04 |
|
Uncharacterized conserved protein YhaN, contains AAA domain [Function unknown];
Pssm-ID: 443752 [Multi-domain] Cd Length: 641 Bit Score: 43.22 E-value: 5.89e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 218 EEFKKRFSDATSKAHQLEEDIvsvtHKAIEKETELDSLKDKLKKAQHEREQLECQLKTEKDEKELYKV--HLKNTEIENT 295
Cdd:COG4717 74 KELEEELKEAEEKEEEYAELQ----EELEELEEELEELEAELEELREELEKLEKLLQLLPLYQELEALeaELAELPERLE 149
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 296 KLMSEVQTLKNLDGNKESVithfKEEIGRLQlclAEKENLQRTFLLTTsskedtcflKEQLRKAEEQVQATRQEVVFLAK 375
Cdd:COG4717 150 ELEERLEELRELEEELEEL----EAELAELQ---EELEELLEQLSLAT---------EEELQDLAEELEELQQRLAELEE 213
|
170 180 190
....*....|....*....|....*....|....*....
gi 1384071986 376 ELSDAVNVRDRTMADLhtARLENEKVKKQLADAVAELKL 414
Cdd:COG4717 214 ELEEAQEELEELEEEL--EQLENELEAAALEERLKEARL 250
|
|
| SMC_prok_A |
TIGR02169 |
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ... |
150-281 |
6.28e-04 |
|
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 43.52 E-value: 6.28e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 150 LELKIEKTMKEKEELLKLIAVLEKETAQLREQVGRMERELNH-------------EKERCDQ-------------LQAEQ 203
Cdd:TIGR02169 749 LEQEIENVKSELKELEARIEELEEDLHKLEEALNDLEARLSHsripeiqaelsklEEEVSRIearlreieqklnrLTLEK 828
|
90 100 110 120 130 140 150
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*...
gi 1384071986 204 KGLTEVTQSLKMENEEFKKRFSDATSKAHQLEEDIVSVTHKAIEKETELDSLKDKLKKAQHEREQLECQLKTEKDEKE 281
Cdd:TIGR02169 829 EYLEKEIQELQEQRIDLKEQIKSIEKEIENLNGKKEELEEELEELEAALRDLESRLGDLKKERDELEAQLRELERKIE 906
|
|
| PRK03918 |
PRK03918 |
DNA double-strand break repair ATPase Rad50; |
197-466 |
7.14e-04 |
|
DNA double-strand break repair ATPase Rad50;
Pssm-ID: 235175 [Multi-domain] Cd Length: 880 Bit Score: 43.13 E-value: 7.14e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 197 DQLQAEQKGLTEVTQSLKMENEEFKKRFSdatsKAHQLEEDIVSVTHKAIEKETELDSLKDKLKKAQHEREQLECQLKTE 276
Cdd:PRK03918 158 DDYENAYKNLGEVIKEIKRRIERLEKFIK----RTENIEELIKEKEKELEEVLREINEISSELPELREELEKLEKEVKEL 233
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 277 KDEKELykvhLKNTEIENTKLMSEVQTLKNLDGNKESVITHFKEEIGRLQLCLAEKENLQRTFLLTTSSKEDTCFLKEQL 356
Cdd:PRK03918 234 EELKEE----IEELEKELESLEGSKRKLEEKIRELEERIEELKKEIEELEEKVKELKELKEKAEEYIKLSEFYEEYLDEL 309
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 357 RKAEEQVQATRQEVVFLAKELSDAVNVRDRTMadlhtarlENEKVKKQLADAVAELK-----LNAMKKDQDKTDTLEHEL 431
Cdd:PRK03918 310 REIEKRLSRLEEEINGIEERIKELEEKEERLE--------ELKKKLKELEKRLEELEerhelYEEAKAKKEELERLKKRL 381
|
250 260 270
....*....|....*....|....*....|....*.
gi 1384071986 432 R-REVEDLKLRLQMAADHYKEKFKECQRLQKQINKL 466
Cdd:PRK03918 382 TgLTPEKLEKELEELEKAKEEIEEEISKITARIGEL 417
|
|
| Mplasa_alph_rch |
TIGR04523 |
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of ... |
150-475 |
7.43e-04 |
|
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of Mycoplasma species. Members average 750 amino acids in length, including signal peptide. Sequences are predicted (Jpred 3) to be almost entirely alpha-helical. These sequences show strong periodicity (consistent with long alpha helical structures) and low complexity rich in D,E,N,Q, and K. Genes encoding these proteins are often found in tandem. The function is unknown.
Pssm-ID: 275316 [Multi-domain] Cd Length: 745 Bit Score: 43.09 E-value: 7.43e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 150 LELKIEKTMKEKEELLKLIAVLEKETAQLREQVGRMERELNHEKERCDQLQAEQKGLTEVTQSLKMENEEFKKRFSDATS 229
Cdd:TIGR04523 326 IQNQISQNNKIISQLNEQISQLKKELTNSESENSEKQRELEEKQNEIEKLKKENQSYKQEIKNLESQINDLESKIQNQEK 405
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 230 KAHQLEEDIVSVTHKAIEKETELDSLKDKLKKAQHEREQLEcqlKTEKDEKELYKVHLKNTEIENTKLMSEVQTLKNLDG 309
Cdd:TIGR04523 406 LNQQKDEQIKKLQQEKELLEKEIERLKETIIKNNSEIKDLT---NQDSVKELIIKNLDNTRESLETQLKVLSRSINKIKQ 482
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 310 NKESVITHFKEEIGRLQLCLAEKENLqrtfllttssKEDTCFLKEQLRKAEEQVQATRQEVVFLAKELSDAVNVRDRTMA 389
Cdd:TIGR04523 483 NLEQKQKELKSKEKELKKLNEEKKEL----------EEKVKDLTKKISSLKEKIEKLESEKKEKESKISDLEDELNKDDF 552
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 390 DLHTARLENEKVKKQlaDAVAELKLN--AMKKDQDKTDTLEHELRREVEDLKLRLQMAADHYKEKFKECQRLQKQINKLS 467
Cdd:TIGR04523 553 ELKKENLEKEIDEKN--KEIEELKQTqkSLKKKQEEKQELIDQKEKEKKDLIKEIEEKEKKISSLEKELEKAKKENEKLS 630
|
....*...
gi 1384071986 468 DQSANNNN 475
Cdd:TIGR04523 631 SIIKNIKS 638
|
|
| SCP-1 |
pfam05483 |
Synaptonemal complex protein 1 (SCP-1); Synaptonemal complex protein 1 (SCP-1) is the major ... |
150-601 |
9.55e-04 |
|
Synaptonemal complex protein 1 (SCP-1); Synaptonemal complex protein 1 (SCP-1) is the major component of the transverse filaments of the synaptonemal complex. Synaptonemal complexes are structures that are formed between homologous chromosomes during meiotic prophase.
Pssm-ID: 114219 [Multi-domain] Cd Length: 787 Bit Score: 42.79 E-value: 9.55e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 150 LELKIEKTMKEKEELLK-------LIAVLEKETAQLREQVGRMERE----------LNHEKERCD------QLQAEQK-- 204
Cdd:pfam05483 132 VSLKLEEEIQENKDLIKennatrhLCNLLKETCARSAEKTKKYEYEreetrqvymdLNNNIEKMIlafeelRVQAENArl 211
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 205 ----GLTEVTQSLKMENEEFKKRFSDatsKAHQLEEDIVSVThkaiEKETELDSLKDKLKKAQHEREQLE--CQLKTEKD 278
Cdd:pfam05483 212 emhfKLKEDHEKIQHLEEEYKKEIND---KEKQVSLLLIQIT----EKENKMKDLTFLLEESRDKANQLEekTKLQDENL 284
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 279 EKELYKVHLKNTEIENTK--LMSEVQTLKNLDGNKEsVITHFKEEIGRLQLCLAEKENLQRTF--LLTTSSKEDTCFLKE 354
Cdd:pfam05483 285 KELIEKKDHLTKELEDIKmsLQRSMSTQKALEEDLQ-IATKTICQLTEEKEAQMEELNKAKAAhsFVVTEFEATTCSLEE 363
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 355 QLRKAEEQVQATRQEVVFLAKEL----------SDAVNVRDRTMADLHTARLENEKV---KKQLADAVAELKlnamKKDQ 421
Cdd:pfam05483 364 LLRTEQQRLEKNEDQLKIITMELqkksseleemTKFKNNKEVELEELKKILAEDEKLldeKKQFEKIAEELK----GKEQ 439
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 422 DKTDTLEHElRREVEDLKLRL---QMAADHYKEKFKECQ-RLQKQINKLSDQSANNNNVFTKKTGNQQKVNDASVNTDPA 497
Cdd:pfam05483 440 ELIFLLQAR-EKEIHDLEIQLtaiKTSEEHYLKEVEDLKtELEKEKLKNIELTAHCDKLLLENKELTQEASDMTLELKKH 518
|
410 420 430 440 450 460 470 480
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 498 TSastvDVKPSPSAAEADFDIVTKGQVCEMT---------KEIADKTEKYnKCKQLLQDEKAKCNKYadELAKMELKWKE 568
Cdd:pfam05483 519 QE----DIINCKKQEERMLKQIENLEEKEMNlrdelesvrEEFIQKGDEV-KCKLDKSEENARSIEY--EVLKKEKQMKI 591
|
490 500 510
....*....|....*....|....*....|...
gi 1384071986 569 QVKIAENVKLELAEVQDNYKELKRslENPAERK 601
Cdd:pfam05483 592 LENKCNNLKKQIENKNKNIEELHQ--ENKALKK 622
|
|
| CwlO1 |
COG3883 |
Uncharacterized N-terminal coiled-coil domain of peptidoglycan hydrolase CwlO [Function ... |
150-302 |
1.03e-03 |
|
Uncharacterized N-terminal coiled-coil domain of peptidoglycan hydrolase CwlO [Function unknown];
Pssm-ID: 443091 [Multi-domain] Cd Length: 379 Bit Score: 42.12 E-value: 1.03e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 150 LELKIEKTMKEKEELLKLIAVLEKETAQLREQVGRMERELNHEKERCDQLQA--EQKGLTEVTQSLkmeneEFKKRFSDA 227
Cdd:COG3883 56 LQAELEALQAEIDKLQAEIAEAEAEIEERREELGERARALYRSGGSVSYLDVllGSESFSDFLDRL-----SALSKIADA 130
|
90 100 110 120 130 140 150
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*.
gi 1384071986 228 TSKA-HQLEEDIVSVTHKAIEKETELDSLKDKLKKAQHEREQLECQLKTEKDEKELYKVHLKNTEIENTKLMSEVQ 302
Cdd:COG3883 131 DADLlEELKADKAELEAKKAELEAKLAELEALKAELEAAKAELEAQQAEQEALLAQLSAEEAAAEAQLAELEAELA 206
|
|
| PRK02224 |
PRK02224 |
DNA double-strand break repair Rad50 ATPase; |
150-475 |
1.26e-03 |
|
DNA double-strand break repair Rad50 ATPase;
Pssm-ID: 179385 [Multi-domain] Cd Length: 880 Bit Score: 42.33 E-value: 1.26e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 150 LELKIEKTMKEKEELlkliavlEKETAQLREQVGRMERELNHEKERCDQLQAEQKGLTEVTQSLKMENEEFKKRFSD--- 226
Cdd:PRK02224 263 LRETIAETEREREEL-------AEEVRDLRERLEELEEERDDLLAEAGLDDADAEAVEARREELEDRDEELRDRLEEcrv 335
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 227 -----------ATSKAHQLEEDIVSVTHKAIEKETELDSLKDKLKKAQHEREQLECQLKTEKDEKELYKVHLKNTEIENT 295
Cdd:PRK02224 336 aaqahneeaesLREDADDLEERAEELREEAAELESELEEAREAVEDRREEIEELEEEIEELRERFGDAPVDLGNAEDFLE 415
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 296 KLMSEvqtLKNLDGNKESVITHFKEEIGRlqlcLAEKENLQrtflltTSSKEDTCflkEQLRKAEEQVQAT---RQEVVF 372
Cdd:PRK02224 416 ELREE---RDELREREAELEATLRTARER----VEEAEALL------EAGKCPEC---GQPVEGSPHVETIeedRERVEE 479
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 373 LAKELSDAVNVRDRTMADLHTA--------RLENEKVKKQLADAVAELKLNAMKKDQDKTDtlehELRREVEDLKLRLQM 444
Cdd:PRK02224 480 LEAELEDLEEEVEEVEERLERAedlveaedRIERLEERREDLEELIAERRETIEEKRERAE----ELRERAAELEAEAEE 555
|
330 340 350
....*....|....*....|....*....|.
gi 1384071986 445 AADHYKEKFKECQRLQKQINKLSDQSANNNN 475
Cdd:PRK02224 556 KREAAAEAEEEAEEAREEVAELNSKLAELKE 586
|
|
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
410-607 |
1.32e-03 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 42.35 E-value: 1.32e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 410 AELKLNAMKKDQDKTDTLEHELRREVEdlKLRLQM-AADHYKEKFKECQRLQKQINKLSDQSANNN--NVFTKKTGNQQK 486
Cdd:TIGR02168 177 TERKLERTRENLDRLEDILNELERQLK--SLERQAeKAERYKELKAELRELELALLVLRLEELREEleELQEELKEAEEE 254
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 487 VNDASVNTDPATSA-STVDVKPSPSAAEAD------FDIVTKGQVCEMTKEIADKTEKYNKCKQL-----LQDEKAKCNK 554
Cdd:TIGR02168 255 LEELTAELQELEEKlEELRLEVSELEEEIEelqkelYALANEISRLEQQKQILRERLANLERQLEeleaqLEELESKLDE 334
|
170 180 190 200 210
....*....|....*....|....*....|....*....|....*....|...
gi 1384071986 555 YADELAKMELKWKEQVKIAENVKLELAEVQDNYKELKRSLENpAERKMEGQNS 607
Cdd:TIGR02168 335 LAEELAELEEKLEELKEELESLEAELEELEAELEELESRLEE-LEEQLETLRS 386
|
|
| SCP-1 |
pfam05483 |
Synaptonemal complex protein 1 (SCP-1); Synaptonemal complex protein 1 (SCP-1) is the major ... |
153-462 |
1.37e-03 |
|
Synaptonemal complex protein 1 (SCP-1); Synaptonemal complex protein 1 (SCP-1) is the major component of the transverse filaments of the synaptonemal complex. Synaptonemal complexes are structures that are formed between homologous chromosomes during meiotic prophase.
Pssm-ID: 114219 [Multi-domain] Cd Length: 787 Bit Score: 42.40 E-value: 1.37e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 153 KIEKTMKEKE-ELLKLIAVLEKETAQLREQVGRMERELNHEKERCDQLQAEQKG-------LTEVTQSLKMENEEFKKRF 224
Cdd:pfam05483 429 KIAEELKGKEqELIFLLQAREKEIHDLEIQLTAIKTSEEHYLKEVEDLKTELEKeklknieLTAHCDKLLLENKELTQEA 508
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 225 SDATSKAHQLEEDIVSVTH------KAI----EKETEL-DSLKDKLKKAQHEREQLECQLKTEKDEKELYKVHLKNTEIE 293
Cdd:pfam05483 509 SDMTLELKKHQEDIINCKKqeermlKQIenleEKEMNLrDELESVREEFIQKGDEVKCKLDKSEENARSIEYEVLKKEKQ 588
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 294 NTKLMSEVQTLKNLDGNKESVITHFKEE---------------------IGRLQLCLAE-KENLQRTFLLTTSSKEDTCF 351
Cdd:pfam05483 589 MKILENKCNNLKKQIENKNKNIEELHQEnkalkkkgsaenkqlnayeikVNKLELELASaKQKFEEIIDNYQKEIEDKKI 668
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 352 LKEQLRKAEEQVQATRQEVVFLAKELSDAVNVRDRTMADLHtarlenEKVKKQLADAVAEL--KLNAMKKDQDKTDTLEH 429
Cdd:pfam05483 669 SEEKLLEEVEKAKAIADEAVKLQKEIDKRCQHKIAEMVALM------EKHKHQYDKIIEERdsELGLYKNKEQEQSSAKA 742
|
330 340 350
....*....|....*....|....*....|...
gi 1384071986 430 ELRREVEDLKLRLQMAADHYKEKFKECQRLQKQ 462
Cdd:pfam05483 743 ALEIELSNIKAELLSLKKQLEIEKEEKEKLKME 775
|
|
| Zn-C2H2_TAX1BP1_rpt2 |
cd21970 |
second C2H2-type zinc binding domain found in tax1-binding protein 1 (TAX1BP1) and similar ... |
718-743 |
1.66e-03 |
|
second C2H2-type zinc binding domain found in tax1-binding protein 1 (TAX1BP1) and similar proteins; TAX1BP1, also called TRAF6-binding protein (T6BP), is a novel ubiquitin-binding adaptor protein involved in the negative regulation of the NF-kappaB transcription factor, a key player in inflammatory responses, immunity and tumorigenesis. It inhibits TNF-induced apoptosis by mediating the TNFAIP3 anti-apoptotic activity. It may also play a role in the pro-inflammatory cytokine IL-1 signaling cascade. TAX1BP1 is degraded by caspase-3-like family proteins upon TNF-induced apoptosis. TAX1BP1 contains two C2H2-type zinc binding domains; this model corresponds to the second one.
Pssm-ID: 412016 Cd Length: 27 Bit Score: 36.38 E-value: 1.66e-03
10 20
....*....|....*....|....*.
gi 1384071986 718 KKCPLCELMFPPNYDQSKFEEHVESH 743
Cdd:cd21970 1 KVCPMCSEQFPPDCDQQVFERHVQTH 26
|
|
| WEMBL |
pfam05701 |
Weak chloroplast movement under blue light; WEMBL consists of several plant proteins required ... |
214-479 |
1.80e-03 |
|
Weak chloroplast movement under blue light; WEMBL consists of several plant proteins required for the chloroplast avoidance response under high intensity blue light. This avoidance response consists in the relocation of chloroplasts on the anticlinal side of exposed cells. Acts in association with PMI2 to maintain the velocity of chloroplast photo-relocation movement via the regulation of cp-actin filaments. Thus several member-sequences are described as "myosin heavy chain-like".
Pssm-ID: 461718 [Multi-domain] Cd Length: 562 Bit Score: 41.55 E-value: 1.80e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 214 KMENE--EFKKRFSDATSKAHQLEEDIVSvTHKAIEKeteldsLKDKLKKAQHEREQlecqlktEKDEKELYKVHLKNTE 291
Cdd:pfam05701 46 KVQEEipEYKKQSEAAEAAKAQVLEELES-TKRLIEE------LKLNLERAQTEEAQ-------AKQDSELAKLRVEEME 111
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 292 ientklmsevqtlKNLDgNKESVithfkeeIGRLQLCLAekenlqrtfllttsskedtcflKEQLRKAEEQVQATRQEVV 371
Cdd:pfam05701 112 -------------QGIA-DEASV-------AAKAQLEVA----------------------KARHAAAVAELKSVKEELE 148
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 372 FLAKELSDAVNVRDRTMADLHTARLENEKVKKQLADAVAElkLNAMKKDQDktdtLEHELRREVEDLKLRLQMAADHYKE 451
Cdd:pfam05701 149 SLRKEYASLVSERDIAIKRAEEAVSASKEIEKTVEELTIE--LIATKESLE----SAHAAHLEAEEHRIGAALAREQDKL 222
|
250 260
....*....|....*....|....*....
gi 1384071986 452 KF-KECQRLQKQINKLSDQSANNNNVFTK 479
Cdd:pfam05701 223 NWeKELKQAEEELQRLNQQLLSAKDLKSK 251
|
|
| sbcc |
TIGR00618 |
exonuclease SbcC; All proteins in this family for which functions are known are part of an ... |
127-601 |
2.00e-03 |
|
exonuclease SbcC; All proteins in this family for which functions are known are part of an exonuclease complex with sbcD homologs. This complex is involved in the initiation of recombination to regulate the levels of palindromic sequences in DNA. This family is based on the phylogenomic analysis of JA Eisen (1999, Ph.D. Thesis, Stanford University). [DNA metabolism, DNA replication, recombination, and repair]
Pssm-ID: 129705 [Multi-domain] Cd Length: 1042 Bit Score: 41.88 E-value: 2.00e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 127 EELLTMEDEGNSDMLVVTTKAGLLELKIEKTMKEKEELLKLIAVLEKETAQLREQVGRMERELNHEKERCDQL------- 199
Cdd:TIGR00618 354 EIHIRDAHEVATSIREISCQQHTLTQHIHTLQQQKTTLTQKLQSLCKELDILQREQATIDTRTSAFRDLQGQLahakkqq 433
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 200 QAEQKGL-------TEVTQSLKMENEEFKKRFSdATSKAHQLEEDIVSVTHKAIEKETELDSLKDKLKkaqhereQLECQ 272
Cdd:TIGR00618 434 ELQQRYAelcaaaiTCTAQCEKLEKIHLQESAQ-SLKEREQQLQTKEQIHLQETRKKAVVLARLLELQ-------EEPCP 505
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 273 LKTEKDEKELYKVHLKNTEIENTKLMSEVQTLKNLDGNKESVITHFKEEIGRLQLCLAEKENLQRTFL----LTTSSKED 348
Cdd:TIGR00618 506 LCGSCIHPNPARQDIDNPGPLTRRMQRGEQTYAQLETSEEDVYHQLTSERKQRASLKEQMQEIQQSFSiltqCDNRSKED 585
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 349 -------------------------TCFLKEQLRKAEEQV--QATRQEVVFLAKELSDAVNVRDRTMADLHTARLENE-- 399
Cdd:TIGR00618 586 ipnlqnitvrlqdlteklseaedmlACEQHALLRKLQPEQdlQDVRLHLQQCSQELALKLTALHALQLTLTQERVREHal 665
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 400 --KVKKQLADAVAELKLNAMKKDQDKTDTLEHELRREVEDLKLRLQMAADHYKEKFKECQRLQKQINKLSDQSANNNNVF 477
Cdd:TIGR00618 666 siRVLPKELLASRQLALQKMQSEKEQLTYWKEMLAQCQTLLRELETHIEEYDREFNEIENASSSLGSDLAAREDALNQSL 745
|
410 420 430 440 450 460 470 480
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 478 TKKTGNQQKVNDASVNTDPATSastvdvkpspsaAEADFDIVTKGQVCEMTKEIADKTEKYNKCKQLLQDEKAKCNKYAD 557
Cdd:TIGR00618 746 KELMHQARTVLKARTEAHFNNN------------EEVTAALQTGAELSHLAAEIQFFNRLREEDTHLLKTLEAEIGQEIP 813
|
490 500 510 520
....*....|....*....|....*....|....*....|....*
gi 1384071986 558 E-LAKMELKWKEQVKIAENVKLELAEVQDNYKELKRSLENPAERK 601
Cdd:TIGR00618 814 SdEDILNLQCETLVQEEEQFLSRLEEKSATLGEITHQLLKYEECS 858
|
|
| Cast |
pfam10174 |
RIM-binding protein of the cytomatrix active zone; This is a family of proteins that form part ... |
158-603 |
2.06e-03 |
|
RIM-binding protein of the cytomatrix active zone; This is a family of proteins that form part of the CAZ (cytomatrix at the active zone) complex which is involved in determining the site of synaptic vesicle fusion. The C-terminus is a PDZ-binding motif that binds directly to RIM (a small G protein Rab-3A effector). The family also contains four coiled-coil domains.
Pssm-ID: 431111 [Multi-domain] Cd Length: 766 Bit Score: 41.73 E-value: 2.06e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 158 MKEKEELLKLIAVLEKETAQLREQVGRMERELNHEKERCDQLQAEQKGLTEVTQSLKMENEEFKKRFSDATSKAHQLEED 237
Cdd:pfam10174 267 TEDREEEIKQMEVYKSHSKFMKNKIDQLKQELSKKESELLALQTKLETLTNQNSDCKQHIEVLKESLTAKEQRAAILQTE 346
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 238 IVSVTHKAIEKETELDSLKDKLKKAQHEREQLecqlktekdekelykvhlkNTEIENTKLMSEVqtlknldgnKESVITH 317
Cdd:pfam10174 347 VDALRLRLEEKESFLNKKTKQLQDLTEEKSTL-------------------AGEIRDLKDMLDV---------KERKINV 398
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 318 FKEEIgrlqlclaekENLQrtfllttsskedtcflkEQLRKAEEQVQATRQEVvflaKELSDAVNVRDRTMADLHTARLE 397
Cdd:pfam10174 399 LQKKI----------ENLQ-----------------EQLRDKDKQLAGLKERV----KSLQTDSSNTDTALTTLEEALSE 447
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 398 NEKVkkqladaVAELKLNAMKKDQDKTDTLEhELRREVEDLKLRLQMAADHYKEKFKECQRLQKQINKLSDQSANNNNVF 477
Cdd:pfam10174 448 KERI-------IERLKEQREREDRERLEELE-SLKKENKDLKEKVSALQPELTEKESSLIDLKEHASSLASSGLKKDSKL 519
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 478 TKKTGN-QQKVNDAS--VNTDPATSASTVDVKPSPsaaeadfDIVTKGQVCEmtKEIADKTEKYNKCK----QLL----- 545
Cdd:pfam10174 520 KSLEIAvEQKKEECSklENQLKKAHNAEEAVRTNP-------EINDRIRLLE--QEVARYKEESGKAQaeveRLLgilre 590
|
410 420 430 440 450 460
....*....|....*....|....*....|....*....|....*....|....*....|....*...
gi 1384071986 546 -QDEKAKCNKYADELAKMEL-KWKEQVKIAENVKL--------ELAEVQDNYKELKRSLENPAERKME 603
Cdd:pfam10174 591 vENEKNDKDKKIAELESLTLrQMKEQNKKVANIKHgqqemkkkGAQLLEEARRREDNLADNSQQLQLE 658
|
|
| PRK04778 |
PRK04778 |
septation ring formation regulator EzrA; Provisional |
126-469 |
2.14e-03 |
|
septation ring formation regulator EzrA; Provisional
Pssm-ID: 179877 [Multi-domain] Cd Length: 569 Bit Score: 41.36 E-value: 2.14e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 126 VEELLTMEDEGNSDMLvvttkAGLLELKI--EKTMKEKEELLKLIAVLEKE-----------TAQLREQVGRMERELNH- 191
Cdd:PRK04778 110 IESLLDLIEEDIEQIL-----EELQELLEseEKNREEVEQLKDLYRELRKSllanrfsfgpaLDELEKQLENLEEEFSQf 184
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 192 --EKERCDQLQAEqkgltEVTQSLKMENEEFKK------------------RFSDATSKAHQLEEDIVSVTHKAIEKEte 251
Cdd:PRK04778 185 veLTESGDYVEAR-----EILDQLEEELAALEQimeeipellkelqtelpdQLQELKAGYRELVEEGYHLDHLDIEKE-- 257
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 252 LDSLKDKLKKAQHEREQLEC--------QLKTEKDEkeLYKVhlknteIENtklmsEVQTLKNLDGNKESVITHFKEEIG 323
Cdd:PRK04778 258 IQDLKEQIDENLALLEELDLdeaeekneEIQERIDQ--LYDI------LER-----EVKARKYVEKNSDTLPDFLEHAKE 324
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 324 RLQLCLAEKENLQRTFLLTTSSKEDTCFLKEQLRKAEEQVQATRQEVVFLAKELSDAVNVRDRTMADLHTARLENEKVKK 403
Cdd:PRK04778 325 QNKELKEEIDRVKQSYTLNESELESVRQLEKQLESLEKQYDEITERIAEQEIAYSELQEELEEILKQLEEIEKEQEKLSE 404
|
330 340 350 360 370 380 390
....*....|....*....|....*....|....*....|....*....|....*....|....*....|.
gi 1384071986 404 QLA-----DAVAELKLNAMKKDQdktdtleHELRREVEdlKLRLQMAADHYKEKFKEcqrLQKQINKLSDQ 469
Cdd:PRK04778 405 MLQglrkdELEAREKLERYRNKL-------HEIKRYLE--KSNLPGLPEDYLEMFFE---VSDEIEALAEE 463
|
|
| Tropomyosin_1 |
pfam12718 |
Tropomyosin like; This family is a set of eukaryotic tropomyosins. Within the yeast Tpm1 and ... |
211-297 |
2.23e-03 |
|
Tropomyosin like; This family is a set of eukaryotic tropomyosins. Within the yeast Tpm1 and Tpm2, biochemical and sequence analyses indicate that Tpm2p spans four actin monomers along a filament, whereas Tpm1p spans five. Despite its shorter length, Tpm2p can compete with Tpm1p for binding to F-actin. Over-expression of Tpm2p in vivo alters the axial budding of haploids to a bipolar pattern, and this can be partially suppressed by co-over-expression of Tpm1p. This suggests distinct functions for the two tropomyosins, and indicates that the ratio between them is important for correct morphogenesis. The family also contains higher eukaryote Tpm3 members.
Pssm-ID: 403808 [Multi-domain] Cd Length: 142 Bit Score: 39.21 E-value: 2.23e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 211 QSLKMENEEfkkrfsdATSKAHQLEEDIVSVTHKAIEKETELDSLKDKLKKAQHEREQLECQLKTEKDEKELYKVHLKNT 290
Cdd:pfam12718 3 NSLKLEAEN-------AQERAEELEEKVKELEQENLEKEQEIKSLTHKNQQLEEEVEKLEEQLKEAKEKAEESEKLKTNN 75
|
....*..
gi 1384071986 291 EIENTKL 297
Cdd:pfam12718 76 ENLTRKI 82
|
|
| PRK12704 |
PRK12704 |
phosphodiesterase; Provisional |
151-260 |
2.56e-03 |
|
phosphodiesterase; Provisional
Pssm-ID: 237177 [Multi-domain] Cd Length: 520 Bit Score: 41.30 E-value: 2.56e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 151 ELKIEKTMKEKEELLKLIAVLEKETAQLREQVGRMERELNHEKERCDQ----LQAEQKGLTEVTQSLKMENEEFKKRFSD 226
Cdd:PRK12704 53 AIKKEALLEAKEEIHKLRNEFEKELRERRNELQKLEKRLLQKEENLDRklelLEKREEELEKKEKELEQKQQELEKKEEE 132
|
90 100 110
....*....|....*....|....*....|....*..
gi 1384071986 227 ATSKAHQLE---EDIVSVTHKAIeKETELDSLKDKLK 260
Cdd:PRK12704 133 LEELIEEQLqelERISGLTAEEA-KEILLEKVEEEAR 168
|
|
| Zn-C2H2_CALCOCO1 |
cd21967 |
C2H2-type zinc binding domain found in calcium-binding and coiled-coil domain-containing ... |
718-744 |
2.99e-03 |
|
C2H2-type zinc binding domain found in calcium-binding and coiled-coil domain-containing protein 1 (CALCOCO1) and similar proteins; CALCOCO1, also called calphoglin, or coiled-coil coactivator protein, or Sarcoma antigen NY-SAR-3, functions as a coactivator for aryl hydrocarbon and nuclear receptors (NR). It is recruited to promoters through its contact with the N-terminal basic helix-loop-helix-Per-Arnt-Sim (PAS) domain of transcription factors or coactivators, such as NCOA2. During ER-activation CALCOCO1 acts synergistically in combination with other NCOA2-binding proteins, such as EP300, CREBBP and CARM1. It is involved in the transcriptional activation of target genes in the Wnt/CTNNB1 pathway. It functions as a secondary coactivator in LEF1-mediated transcriptional activation via its interaction with CTNNB1. In association with CCAR1, CALCOCO1 enhances GATA1- and MED1-mediated transcriptional activation from the gamma-globin promoter during erythroid differentiation of K562 erythroleukemia cells. CALCOCO1 contains a C2H2-type zinc binding domain.
Pssm-ID: 412013 Cd Length: 29 Bit Score: 35.94 E-value: 2.99e-03
10 20
....*....|....*....|....*..
gi 1384071986 718 KKCPLCELMFPPNYDQSKFEEHVESHW 744
Cdd:cd21967 1 KECPICKERFPLECDKDALEDHIDSHF 27
|
|
| Smc |
COG1196 |
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; ... |
352-608 |
3.19e-03 |
|
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 440809 [Multi-domain] Cd Length: 983 Bit Score: 41.08 E-value: 3.19e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 352 LKEQLRKAEEQVQATRQevvflAKELSDAVNVRDRTMADLHTARLENEKVKKQLADAVAELKLNAMKKDQDKTDTLEHEL 431
Cdd:COG1196 198 LERQLEPLERQAEKAER-----YRELKEELKELEAELLLLKLRELEAELEELEAELEELEAELEELEAELAELEAELEEL 272
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 432 RREVEDLKLRLQMAADHYKEKFKECQRLQKQINKLSDQSANNnnvftkktgnqqkvndasvntdpatsastvdvkpspsA 511
Cdd:COG1196 273 RLELEELELELEEAQAEEYELLAELARLEQDIARLEERRREL-------------------------------------E 315
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 512 AEADfdivtkgqvcEMTKEIADKTEKYNKCKQLLQDEKAKCNKYADELAKMELKWKEQVKIAENVKLELAEVQDNYKELK 591
Cdd:COG1196 316 ERLE----------ELEEELAELEEELEELEEELEELEEELEEAEEELEEAEAELAEAEEALLEAEAELAEAEEELEELA 385
|
250
....*....|....*..
gi 1384071986 592 RSLENPAERKMEGQNSQ 608
Cdd:COG1196 386 EELLEALRAAAELAAQL 402
|
|
| DR0291 |
COG1579 |
Predicted nucleic acid-binding protein DR0291, contains C4-type Zn-ribbon domain [General ... |
150-270 |
3.56e-03 |
|
Predicted nucleic acid-binding protein DR0291, contains C4-type Zn-ribbon domain [General function prediction only];
Pssm-ID: 441187 [Multi-domain] Cd Length: 236 Bit Score: 39.91 E-value: 3.56e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 150 LELKIEKTMKEKEELLKLIAVLEKETAQLREQVGRMERELNH----------EKErCDQLQAEQKGLTEVTQSLKMENEE 219
Cdd:COG1579 43 LEARLEAAKTELEDLEKEIKRLELEIEEVEARIKKYEEQLGNvrnnkeyealQKE-IESLKRRISDLEDEILELMERIEE 121
|
90 100 110 120 130
....*....|....*....|....*....|....*....|....*....|.
gi 1384071986 220 FKKRFSDATSKAHQLEEDIvsvTHKAIEKETELDSLKDKLKKAQHEREQLE 270
Cdd:COG1579 122 LEEELAELEAELAELEAEL---EEKKAELDEELAELEAELEELEAEREELA 169
|
|
| COG4026 |
COG4026 |
Uncharacterized conserved protein, contains TOPRIM domain, potential nuclease [General ... |
149-217 |
4.79e-03 |
|
Uncharacterized conserved protein, contains TOPRIM domain, potential nuclease [General function prediction only];
Pssm-ID: 443204 [Multi-domain] Cd Length: 287 Bit Score: 39.71 E-value: 4.79e-03
10 20 30 40 50 60 70
....*....|....*....|....*....|....*....|....*....|....*....|....*....|.
gi 1384071986 149 LLELK--IEKTMKEKEELLKLIAVLEKETAQLREQVGRMERELNHEKERCDQLQAEQKGLTEVTQSLKMEN 217
Cdd:COG4026 137 LLELKekIDEIAKEKEKLTKENEELESELEELREEYKKLREENSILEEEFDNIKSEYSDLKSRFEELLKKR 207
|
|
| S6OS1 |
pfam15676 |
Six6 opposite strand transcript 1 family; This family of proteins is found in eukaryotes. ... |
162-237 |
5.41e-03 |
|
Six6 opposite strand transcript 1 family; This family of proteins is found in eukaryotes. Proteins in this family are typically between 114 and 587 amino acids in length. The function is not known.
Pssm-ID: 464795 Cd Length: 557 Bit Score: 40.21 E-value: 5.41e-03
10 20 30 40 50 60 70
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....
gi 1384071986 162 EELLKLIAVLEKETAQLREQVGRMERELNHEKERCDQLqAEQKGLTEVTQSLKMENE---EFKKRFSDATSKAHQLEED 237
Cdd:pfam15676 163 EDILKLANTFTQKSSELKKEADEMEMKINYLNKQFERL-SEDKNLSEMLEEKNKSLEkrkEFKERIFEEDEHPLVLEEY 240
|
|
| mukB |
PRK04863 |
chromosome partition protein MukB; |
162-371 |
6.94e-03 |
|
chromosome partition protein MukB;
Pssm-ID: 235316 [Multi-domain] Cd Length: 1486 Bit Score: 39.94 E-value: 6.94e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 162 EELLKLIAVLEKET-----AQLREQVGRME---RELNHEKERCDQLQAEQKGLTEVTQ---SLKMENEEFKKRFSDATSK 230
Cdd:PRK04863 878 NRLLPRLNLLADETladrvEEIREQLDEAEeakRFVQQHGNALAQLEPIVSVLQSDPEqfeQLKQDYQQAQQTQRDAKQQ 957
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 231 AHQLEEDIVSVTH-------KAIEKETEL-DSLKDKLKKAQHEREQLECQLKTEKDEKELY-KVHLK-----NTEIENTK 296
Cdd:PRK04863 958 AFALTEVVQRRAHfsyedaaEMLAKNSDLnEKLRQRLEQAEQERTRAREQLRQAQAQLAQYnQVLASlkssyDAKRQMLQ 1037
|
170 180 190 200 210 220 230
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*...
gi 1384071986 297 -LMSEVQTLK-NLDGNKESVITHFKEEI-GRLQLCLAEKENLQRTFLLTTSSKEDtcfLKEQLRKAEEQVQATRQEVV 371
Cdd:PRK04863 1038 eLKQELQDLGvPADSGAEERARARRDELhARLSANRSRRNQLEKQLTFCEAEMDN---LTKKLRKLERDYHEMREQVV 1112
|
|
| COG4913 |
COG4913 |
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown]; |
352-469 |
6.97e-03 |
|
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown];
Pssm-ID: 443941 [Multi-domain] Cd Length: 1089 Bit Score: 39.90 E-value: 6.97e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 352 LKEQLRKAEEQVQATRQEVVFLAKELSDAVNVRD--RTMADLHTARLENEKVKKQLADAVAELKlnAMKKDQDKtdtLEh 429
Cdd:COG4913 615 LEAELAELEEELAEAEERLEALEAELDALQERREalQRLAEYSWDEIDVASAEREIAELEAELE--RLDASSDD---LA- 688
|
90 100 110 120
....*....|....*....|....*....|....*....|
gi 1384071986 430 ELRREVEDLKLRLQMAADHYKEKFKECQRLQKQINKLSDQ 469
Cdd:COG4913 689 ALEEQLEELEAELEELEEELDELKGEIGRLEKELEQAEEE 728
|
|
| PTZ00121 |
PTZ00121 |
MAEBL; Provisional |
127-337 |
9.03e-03 |
|
MAEBL; Provisional
Pssm-ID: 173412 [Multi-domain] Cd Length: 2084 Bit Score: 39.74 E-value: 9.03e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 127 EELLTMEDEGNSDMLVVTTKAGLLELKIEKTMKEKEELLKLIAVLEKETAQLR--EQVGRMERElnhEKERCDQLQAEQK 204
Cdd:PTZ00121 1650 EELKKAEEENKIKAAEEAKKAEEDKKKAEEAKKAEEDEKKAAEALKKEAEEAKkaEELKKKEAE---EKKKAEELKKAEE 1726
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1384071986 205 GLTEVTQSLKMENEEFKKRFSDATSKahqlEEDIVSVTHKAIEKEteldslkdklKKAQHEREQLECQLKTEKDEKELYK 284
Cdd:PTZ00121 1727 ENKIKAEEAKKEAEEDKKKAEEAKKD----EEEKKKIAHLKKEEE----------KKAEEIRKEKEAVIEEELDEEDEKR 1792
|
170 180 190 200 210
....*....|....*....|....*....|....*....|....*....|....*....
gi 1384071986 285 VHLKNTEIENTKLMSEVQTLKNLDGN------KESVITHFKEEIGRLQLCLAEKENLQR 337
Cdd:PTZ00121 1793 RMEVDKKIKDIFDNFANIIEGGKEGNlvindsKEMEDSAIKEVADSKNMQLEEADAFEK 1851
|
|
| |