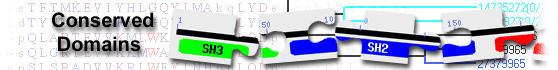


gag-pol fusion protein [Saccharomyces cerevisiae S288C]
Protein Classification

TYA and RNase_HI_RT_Ty1 domain-containing protein( domain architecture ID 10470241)
protein containing domains TYA, rve, RVT_2, and RNase_HI_RT_Ty1
List of domain hits
| Name | Accession | Description | Interval | E-value | ||||||
| TYA | pfam01021 | Ty transposon capsid protein; Ty are yeast transposons. A 5.7kb transcript codes for p3 a ... |
17-400 | 0e+00 | ||||||
Ty transposon capsid protein; Ty are yeast transposons. A 5.7kb transcript codes for p3 a fusion protein of TYA and TYB. The TYA protein is analogous to the gag protein of retroviruses. TYA a is cleaved to form 46kd protein which can form mature virion like particles. This entry corresponds to the capsid protein from Ty1 and Ty2 transposons. : Pssm-ID: 425992 Cd Length: 384 Bit Score: 771.05 E-value: 0e+00
|
||||||||||
| RNase_HI_RT_Ty1 | cd09272 | Ty1/Copia family of RNase HI in long-term repeat retroelements; Ribonuclease H (RNase H) ... |
1606-1742 | 6.12e-28 | ||||||
Ty1/Copia family of RNase HI in long-term repeat retroelements; Ribonuclease H (RNase H) enzymes are divided into two major families, Type 1 and Type 2, based on amino acid sequence similarities and biochemical properties. RNase H is an endonuclease that cleaves the RNA strand of an RNA/DNA hybrid in a sequence non-specific manner in the presence of divalent cations. RNase H is widely present in various organisms including bacteria, archaea, and eukaryotes. RNase HI has also been observed as adjunct domains to the reverse transcriptase gene in retroviruses, in long-term repeat (LTR)-bearing and non-LTR retrotransposons. RNase HI in LTR retrotransposons perform degradation of the original RNA template, generation of a polypurine tract (the primer for plus-strand DNA synthesis), and final removal of RNA primers from newly synthesized minus and plus strands. The catalytic residues for RNase H enzymatic activity, three aspartatic acids and one glutamic acid residue (DEDD) are unvaried across all RNase H domains. Phylogenetic patterns of RNase HI of LTR retroelements is classified into five major families, Ty3/Gypsy, Ty1/Copia, Bel/Pao, DIRS1, and the vertebrate retroviruses. The Ty1/Copia family is widely distributed among the genomes of plants, fungi, and animals. RNase H inhibitors have been explored as an anti-HIV drug target because RNase H inactivation inhibits reverse transcription. : Pssm-ID: 260004 Cd Length: 140 Bit Score: 110.64 E-value: 6.12e-28
|
||||||||||
| RVT_2 super family | cl06662 | Reverse transcriptase (RNA-dependent DNA polymerase); A reverse transcriptase gene is usually ... |
1280-1498 | 3.58e-22 | ||||||
Reverse transcriptase (RNA-dependent DNA polymerase); A reverse transcriptase gene is usually indicative of a mobile element such as a retrotransposon or retrovirus. Reverse transcriptases occur in a variety of mobile elements, including retrotransposons, retroviruses, group II introns, bacterial msDNAs, hepadnaviruses, and caulimoviruses. This Pfam entry includes reverse transcriptases not recognized by the pfam00078 model. The actual alignment was detected with superfamily member pfam07727: Pssm-ID: 400190 Cd Length: 243 Bit Score: 97.66 E-value: 3.58e-22
|
||||||||||
| rve | pfam00665 | Integrase core domain; Integrase mediates integration of a DNA copy of the viral genome into ... |
664-765 | 4.91e-12 | ||||||
Integrase core domain; Integrase mediates integration of a DNA copy of the viral genome into the host chromosome. Integrase is composed of three domains. The amino-terminal domain is a zinc binding domain pfam02022. This domain is the central catalytic domain. The carboxyl terminal domain that is a non-specific DNA binding domain pfam00552. The catalytic domain acts as an endonuclease when two nucleotides are removed from the 3' ends of the blunt-ended viral DNA made by reverse transcription. This domain also catalyzes the DNA strand transfer reaction of the 3' ends of the viral DNA to the 5' ends of the integration site. : Pssm-ID: 459897 [Multi-domain] Cd Length: 98 Bit Score: 63.87 E-value: 4.91e-12
|
||||||||||
| Name | Accession | Description | Interval | E-value | ||||||
| TYA | pfam01021 | Ty transposon capsid protein; Ty are yeast transposons. A 5.7kb transcript codes for p3 a ... |
17-400 | 0e+00 | ||||||
Ty transposon capsid protein; Ty are yeast transposons. A 5.7kb transcript codes for p3 a fusion protein of TYA and TYB. The TYA protein is analogous to the gag protein of retroviruses. TYA a is cleaved to form 46kd protein which can form mature virion like particles. This entry corresponds to the capsid protein from Ty1 and Ty2 transposons. Pssm-ID: 425992 Cd Length: 384 Bit Score: 771.05 E-value: 0e+00
|
||||||||||
| RNase_HI_RT_Ty1 | cd09272 | Ty1/Copia family of RNase HI in long-term repeat retroelements; Ribonuclease H (RNase H) ... |
1606-1742 | 6.12e-28 | ||||||
Ty1/Copia family of RNase HI in long-term repeat retroelements; Ribonuclease H (RNase H) enzymes are divided into two major families, Type 1 and Type 2, based on amino acid sequence similarities and biochemical properties. RNase H is an endonuclease that cleaves the RNA strand of an RNA/DNA hybrid in a sequence non-specific manner in the presence of divalent cations. RNase H is widely present in various organisms including bacteria, archaea, and eukaryotes. RNase HI has also been observed as adjunct domains to the reverse transcriptase gene in retroviruses, in long-term repeat (LTR)-bearing and non-LTR retrotransposons. RNase HI in LTR retrotransposons perform degradation of the original RNA template, generation of a polypurine tract (the primer for plus-strand DNA synthesis), and final removal of RNA primers from newly synthesized minus and plus strands. The catalytic residues for RNase H enzymatic activity, three aspartatic acids and one glutamic acid residue (DEDD) are unvaried across all RNase H domains. Phylogenetic patterns of RNase HI of LTR retroelements is classified into five major families, Ty3/Gypsy, Ty1/Copia, Bel/Pao, DIRS1, and the vertebrate retroviruses. The Ty1/Copia family is widely distributed among the genomes of plants, fungi, and animals. RNase H inhibitors have been explored as an anti-HIV drug target because RNase H inactivation inhibits reverse transcription. Pssm-ID: 260004 Cd Length: 140 Bit Score: 110.64 E-value: 6.12e-28
|
||||||||||
| RVT_2 | pfam07727 | Reverse transcriptase (RNA-dependent DNA polymerase); A reverse transcriptase gene is usually ... |
1280-1498 | 3.58e-22 | ||||||
Reverse transcriptase (RNA-dependent DNA polymerase); A reverse transcriptase gene is usually indicative of a mobile element such as a retrotransposon or retrovirus. Reverse transcriptases occur in a variety of mobile elements, including retrotransposons, retroviruses, group II introns, bacterial msDNAs, hepadnaviruses, and caulimoviruses. This Pfam entry includes reverse transcriptases not recognized by the pfam00078 model. Pssm-ID: 400190 Cd Length: 243 Bit Score: 97.66 E-value: 3.58e-22
|
||||||||||
| rve | pfam00665 | Integrase core domain; Integrase mediates integration of a DNA copy of the viral genome into ... |
664-765 | 4.91e-12 | ||||||
Integrase core domain; Integrase mediates integration of a DNA copy of the viral genome into the host chromosome. Integrase is composed of three domains. The amino-terminal domain is a zinc binding domain pfam02022. This domain is the central catalytic domain. The carboxyl terminal domain that is a non-specific DNA binding domain pfam00552. The catalytic domain acts as an endonuclease when two nucleotides are removed from the 3' ends of the blunt-ended viral DNA made by reverse transcription. This domain also catalyzes the DNA strand transfer reaction of the 3' ends of the viral DNA to the 5' ends of the integration site. Pssm-ID: 459897 [Multi-domain] Cd Length: 98 Bit Score: 63.87 E-value: 4.91e-12
|
||||||||||
| Tra5 | COG2801 | Transposase InsO and inactivated derivatives [Mobilome: prophages, transposons]; |
663-782 | 4.72e-08 | ||||||
Transposase InsO and inactivated derivatives [Mobilome: prophages, transposons]; Pssm-ID: 442053 [Multi-domain] Cd Length: 309 Bit Score: 56.70 E-value: 4.72e-08
|
||||||||||
| transpos_IS481 | NF033577 | IS481 family transposase; null |
652-780 | 6.44e-08 | ||||||
IS481 family transposase; null Pssm-ID: 468094 [Multi-domain] Cd Length: 283 Bit Score: 56.06 E-value: 6.44e-08
|
||||||||||
| transpos_IS3 | NF033516 | IS3 family transposase; |
722-782 | 1.64e-06 | ||||||
IS3 family transposase; Pssm-ID: 468052 [Multi-domain] Cd Length: 369 Bit Score: 52.18 E-value: 1.64e-06
|
||||||||||
| Amelogenin | smart00818 | Amelogenins, cell adhesion proteins, play a role in the biomineralisation of teeth; They seem ... |
53-146 | 2.33e-04 | ||||||
Amelogenins, cell adhesion proteins, play a role in the biomineralisation of teeth; They seem to regulate formation of crystallites during the secretory stage of tooth enamel development and are thought to play a major role in the structural organisation and mineralisation of developing enamel. The extracellular matrix of the developing enamel comprises two major classes of protein: the hydrophobic amelogenins and the acidic enamelins. Circular dichroism studies of porcine amelogenin have shown that the protein consists of 3 discrete folding units: the N-terminal region appears to contain beta-strand structures, while the C-terminal region displays characteristics of a random coil conformation. Subsequent studies on the bovine protein have indicated the amelogenin structure to contain a repetitive beta-turn segment and a "beta-spiral" between Gln112 and Leu138, which sequester a (Pro, Leu, Gln) rich region. The beta-spiral offers a probable site for interactions with Ca2+ ions. Muatations in the human amelogenin gene (AMGX) cause X-linked hypoplastic amelogenesis imperfecta, a disease characterised by defective enamel. A 9bp deletion in exon 2 of AMGX results in the loss of codons for Ile5, Leu6, Phe7 and Ala8, and replacement by a new threonine codon, disrupting the 16-residue (Met1-Ala16) amelogenin signal peptide. Pssm-ID: 197891 [Multi-domain] Cd Length: 165 Bit Score: 43.62 E-value: 2.33e-04
|
||||||||||
| PHA02517 | PHA02517 | putative transposase OrfB; Reviewed |
690-782 | 1.69e-03 | ||||||
putative transposase OrfB; Reviewed Pssm-ID: 222853 [Multi-domain] Cd Length: 277 Bit Score: 42.54 E-value: 1.69e-03
|
||||||||||
| Name | Accession | Description | Interval | E-value | ||||||
| TYA | pfam01021 | Ty transposon capsid protein; Ty are yeast transposons. A 5.7kb transcript codes for p3 a ... |
17-400 | 0e+00 | ||||||
Ty transposon capsid protein; Ty are yeast transposons. A 5.7kb transcript codes for p3 a fusion protein of TYA and TYB. The TYA protein is analogous to the gag protein of retroviruses. TYA a is cleaved to form 46kd protein which can form mature virion like particles. This entry corresponds to the capsid protein from Ty1 and Ty2 transposons. Pssm-ID: 425992 Cd Length: 384 Bit Score: 771.05 E-value: 0e+00
|
||||||||||
| RNase_HI_RT_Ty1 | cd09272 | Ty1/Copia family of RNase HI in long-term repeat retroelements; Ribonuclease H (RNase H) ... |
1606-1742 | 6.12e-28 | ||||||
Ty1/Copia family of RNase HI in long-term repeat retroelements; Ribonuclease H (RNase H) enzymes are divided into two major families, Type 1 and Type 2, based on amino acid sequence similarities and biochemical properties. RNase H is an endonuclease that cleaves the RNA strand of an RNA/DNA hybrid in a sequence non-specific manner in the presence of divalent cations. RNase H is widely present in various organisms including bacteria, archaea, and eukaryotes. RNase HI has also been observed as adjunct domains to the reverse transcriptase gene in retroviruses, in long-term repeat (LTR)-bearing and non-LTR retrotransposons. RNase HI in LTR retrotransposons perform degradation of the original RNA template, generation of a polypurine tract (the primer for plus-strand DNA synthesis), and final removal of RNA primers from newly synthesized minus and plus strands. The catalytic residues for RNase H enzymatic activity, three aspartatic acids and one glutamic acid residue (DEDD) are unvaried across all RNase H domains. Phylogenetic patterns of RNase HI of LTR retroelements is classified into five major families, Ty3/Gypsy, Ty1/Copia, Bel/Pao, DIRS1, and the vertebrate retroviruses. The Ty1/Copia family is widely distributed among the genomes of plants, fungi, and animals. RNase H inhibitors have been explored as an anti-HIV drug target because RNase H inactivation inhibits reverse transcription. Pssm-ID: 260004 Cd Length: 140 Bit Score: 110.64 E-value: 6.12e-28
|
||||||||||
| RVT_2 | pfam07727 | Reverse transcriptase (RNA-dependent DNA polymerase); A reverse transcriptase gene is usually ... |
1280-1498 | 3.58e-22 | ||||||
Reverse transcriptase (RNA-dependent DNA polymerase); A reverse transcriptase gene is usually indicative of a mobile element such as a retrotransposon or retrovirus. Reverse transcriptases occur in a variety of mobile elements, including retrotransposons, retroviruses, group II introns, bacterial msDNAs, hepadnaviruses, and caulimoviruses. This Pfam entry includes reverse transcriptases not recognized by the pfam00078 model. Pssm-ID: 400190 Cd Length: 243 Bit Score: 97.66 E-value: 3.58e-22
|
||||||||||
| rve | pfam00665 | Integrase core domain; Integrase mediates integration of a DNA copy of the viral genome into ... |
664-765 | 4.91e-12 | ||||||
Integrase core domain; Integrase mediates integration of a DNA copy of the viral genome into the host chromosome. Integrase is composed of three domains. The amino-terminal domain is a zinc binding domain pfam02022. This domain is the central catalytic domain. The carboxyl terminal domain that is a non-specific DNA binding domain pfam00552. The catalytic domain acts as an endonuclease when two nucleotides are removed from the 3' ends of the blunt-ended viral DNA made by reverse transcription. This domain also catalyzes the DNA strand transfer reaction of the 3' ends of the viral DNA to the 5' ends of the integration site. Pssm-ID: 459897 [Multi-domain] Cd Length: 98 Bit Score: 63.87 E-value: 4.91e-12
|
||||||||||
| Tra5 | COG2801 | Transposase InsO and inactivated derivatives [Mobilome: prophages, transposons]; |
663-782 | 4.72e-08 | ||||||
Transposase InsO and inactivated derivatives [Mobilome: prophages, transposons]; Pssm-ID: 442053 [Multi-domain] Cd Length: 309 Bit Score: 56.70 E-value: 4.72e-08
|
||||||||||
| transpos_IS481 | NF033577 | IS481 family transposase; null |
652-780 | 6.44e-08 | ||||||
IS481 family transposase; null Pssm-ID: 468094 [Multi-domain] Cd Length: 283 Bit Score: 56.06 E-value: 6.44e-08
|
||||||||||
| Atrophin-1 | pfam03154 | Atrophin-1 family; Atrophin-1 is the protein product of the dentatorubral-pallidoluysian ... |
53-197 | 5.02e-07 | ||||||
Atrophin-1 family; Atrophin-1 is the protein product of the dentatorubral-pallidoluysian atrophy (DRPLA) gene. DRPLA OMIM:125370 is a progressive neurodegenerative disorder. It is caused by the expansion of a CAG repeat in the DRPLA gene on chromosome 12p. This results in an extended polyglutamine region in atrophin-1, that is thought to confer toxicity to the protein, possibly through altering its interactions with other proteins. The expansion of a CAG repeat is also the underlying defect in six other neurodegenerative disorders, including Huntington's disease. One interaction of expanded polyglutamine repeats that is thought to be pathogenic is that with the short glutamine repeat in the transcriptional coactivator CREB binding protein, CBP. This interaction draws CBP away from its usual nuclear location to the expanded polyglutamine repeat protein aggregates that are characteriztic of the polyglutamine neurodegenerative disorders. This interferes with CBP-mediated transcription and causes cytotoxicity. Pssm-ID: 460830 [Multi-domain] Cd Length: 991 Bit Score: 54.77 E-value: 5.02e-07
|
||||||||||
| transpos_IS3 | NF033516 | IS3 family transposase; |
722-782 | 1.64e-06 | ||||||
IS3 family transposase; Pssm-ID: 468052 [Multi-domain] Cd Length: 369 Bit Score: 52.18 E-value: 1.64e-06
|
||||||||||
| Amelogenin | smart00818 | Amelogenins, cell adhesion proteins, play a role in the biomineralisation of teeth; They seem ... |
53-146 | 2.33e-04 | ||||||
Amelogenins, cell adhesion proteins, play a role in the biomineralisation of teeth; They seem to regulate formation of crystallites during the secretory stage of tooth enamel development and are thought to play a major role in the structural organisation and mineralisation of developing enamel. The extracellular matrix of the developing enamel comprises two major classes of protein: the hydrophobic amelogenins and the acidic enamelins. Circular dichroism studies of porcine amelogenin have shown that the protein consists of 3 discrete folding units: the N-terminal region appears to contain beta-strand structures, while the C-terminal region displays characteristics of a random coil conformation. Subsequent studies on the bovine protein have indicated the amelogenin structure to contain a repetitive beta-turn segment and a "beta-spiral" between Gln112 and Leu138, which sequester a (Pro, Leu, Gln) rich region. The beta-spiral offers a probable site for interactions with Ca2+ ions. Muatations in the human amelogenin gene (AMGX) cause X-linked hypoplastic amelogenesis imperfecta, a disease characterised by defective enamel. A 9bp deletion in exon 2 of AMGX results in the loss of codons for Ile5, Leu6, Phe7 and Ala8, and replacement by a new threonine codon, disrupting the 16-residue (Met1-Ala16) amelogenin signal peptide. Pssm-ID: 197891 [Multi-domain] Cd Length: 165 Bit Score: 43.62 E-value: 2.33e-04
|
||||||||||
| PAT1 | pfam09770 | Topoisomerase II-associated protein PAT1; Members of this family are necessary for accurate ... |
41-141 | 1.57e-03 | ||||||
Topoisomerase II-associated protein PAT1; Members of this family are necessary for accurate chromosome transmission during cell division. Pssm-ID: 401645 [Multi-domain] Cd Length: 846 Bit Score: 43.49 E-value: 1.57e-03
|
||||||||||
| PHA02517 | PHA02517 | putative transposase OrfB; Reviewed |
690-782 | 1.69e-03 | ||||||
putative transposase OrfB; Reviewed Pssm-ID: 222853 [Multi-domain] Cd Length: 277 Bit Score: 42.54 E-value: 1.69e-03
|
||||||||||
| Blast search parameters | ||||
|
