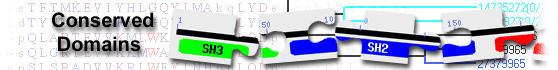S-100: S-100 domain, which represents the largest family within the superfamily of proteins ...
2-89
1.49e-30
S-100: S-100 domain, which represents the largest family within the superfamily of proteins carrying the Ca-binding EF-hand motif. Note that this S-100 hierarchy contains only S-100 EF-hand domains, other EF-hands have been modeled separately. S100 proteins are expressed exclusively in vertebrates, and are implicated in intracellular and extracellular regulatory activities. Intracellularly, S100 proteins act as Ca-signaling or Ca-buffering proteins. The most unusual characteristic of certain S100 proteins is their occurrence in extracellular space, where they act in a cytokine-like manner through RAGE, the receptor for advanced glycation products. Structural data suggest that many S100 members exist within cells as homo- or heterodimers and even oligomers; oligomerization contributes to their functional diversification. Upon binding calcium, most S100 proteins change conformation to a more open structure exposing a hydrophobic cleft. This hydrophobic surface represents the interaction site of S100 proteins with their target proteins. There is experimental evidence showing that many S100 proteins have multiple binding partners with diverse mode of interaction with different targets. In addition to S100 proteins (such as S100A1,-3,-4,-6,-7,-10,-11,and -13), this group includes the ''fused'' gene family, a group of calcium binding S100-related proteins. The ''fused'' gene family includes multifunctional epidermal differentiation proteins - profilaggrin, trichohyalin, repetin, hornerin, and cornulin; functionally these proteins are associated with keratin intermediate filaments and partially crosslinked to the cell envelope. These ''fused'' gene proteins contain N-terminal sequence with two Ca-binding EF-hands motif, which may be associated with calcium signaling in epidermal cells and autoprocessing in a calcium-dependent manner. In contrast to S100 proteins, "fused" gene family proteins contain an extraordinary high number of almost perfect peptide repeats with regular array of polar and charged residues similar to many known cell envelope proteins.
:
Pssm-ID: 238131 [Multi-domain] Cd Length: 88 Bit Score: 115.66 E-value: 1.49e-30
High molecular weight glutenin subunit; Members of this family include high molecular weight ...
189-774
3.07e-28
High molecular weight glutenin subunit; Members of this family include high molecular weight subunits of glutenin. This group of gluten proteins is thought to be largely responsible for the elastic properties of gluten, and hence, doughs. Indeed, glutenin high molecular weight subunits are classified as elastomeric proteins, because the glutenin network can withstand significant deformations without breaking, and return to the original conformation when the stress is removed. Elastomeric proteins differ considerably in amino acid sequence, but they are all polymers whose subunits consist of elastomeric domains, composed of repeated motifs, and non-elastic domains that mediate cross-linking between the subunits. The elastomeric domain motifs are all rich in glycine residues in addition to other hydrophobic residues. High molecular weight glutenin subunits have an extensive central elastomeric domain, flanked by two terminal non-elastic domains that form disulphide cross-links. The central elastomeric domain is characterized by the following three repeated motifs: PGQGQQ, GYYPTS[P/L]QQ, GQQ. It possesses overlapping beta-turns within and between the repeated motifs, and assumes a regular helical secondary structure with a diameter of approx. 1.9 nm and a pitch of approx. 1.5 nm.
The actual alignment was detected with superfamily member pfam03157:
Pssm-ID: 367362 [Multi-domain] Cd Length: 786 Bit Score: 122.75 E-value: 3.07e-28
S-100: S-100 domain, which represents the largest family within the superfamily of proteins ...
2-89
1.49e-30
S-100: S-100 domain, which represents the largest family within the superfamily of proteins carrying the Ca-binding EF-hand motif. Note that this S-100 hierarchy contains only S-100 EF-hand domains, other EF-hands have been modeled separately. S100 proteins are expressed exclusively in vertebrates, and are implicated in intracellular and extracellular regulatory activities. Intracellularly, S100 proteins act as Ca-signaling or Ca-buffering proteins. The most unusual characteristic of certain S100 proteins is their occurrence in extracellular space, where they act in a cytokine-like manner through RAGE, the receptor for advanced glycation products. Structural data suggest that many S100 members exist within cells as homo- or heterodimers and even oligomers; oligomerization contributes to their functional diversification. Upon binding calcium, most S100 proteins change conformation to a more open structure exposing a hydrophobic cleft. This hydrophobic surface represents the interaction site of S100 proteins with their target proteins. There is experimental evidence showing that many S100 proteins have multiple binding partners with diverse mode of interaction with different targets. In addition to S100 proteins (such as S100A1,-3,-4,-6,-7,-10,-11,and -13), this group includes the ''fused'' gene family, a group of calcium binding S100-related proteins. The ''fused'' gene family includes multifunctional epidermal differentiation proteins - profilaggrin, trichohyalin, repetin, hornerin, and cornulin; functionally these proteins are associated with keratin intermediate filaments and partially crosslinked to the cell envelope. These ''fused'' gene proteins contain N-terminal sequence with two Ca-binding EF-hands motif, which may be associated with calcium signaling in epidermal cells and autoprocessing in a calcium-dependent manner. In contrast to S100 proteins, "fused" gene family proteins contain an extraordinary high number of almost perfect peptide repeats with regular array of polar and charged residues similar to many known cell envelope proteins.
Pssm-ID: 238131 [Multi-domain] Cd Length: 88 Bit Score: 115.66 E-value: 1.49e-30
High molecular weight glutenin subunit; Members of this family include high molecular weight ...
189-774
3.07e-28
High molecular weight glutenin subunit; Members of this family include high molecular weight subunits of glutenin. This group of gluten proteins is thought to be largely responsible for the elastic properties of gluten, and hence, doughs. Indeed, glutenin high molecular weight subunits are classified as elastomeric proteins, because the glutenin network can withstand significant deformations without breaking, and return to the original conformation when the stress is removed. Elastomeric proteins differ considerably in amino acid sequence, but they are all polymers whose subunits consist of elastomeric domains, composed of repeated motifs, and non-elastic domains that mediate cross-linking between the subunits. The elastomeric domain motifs are all rich in glycine residues in addition to other hydrophobic residues. High molecular weight glutenin subunits have an extensive central elastomeric domain, flanked by two terminal non-elastic domains that form disulphide cross-links. The central elastomeric domain is characterized by the following three repeated motifs: PGQGQQ, GYYPTS[P/L]QQ, GQQ. It possesses overlapping beta-turns within and between the repeated motifs, and assumes a regular helical secondary structure with a diameter of approx. 1.9 nm and a pitch of approx. 1.5 nm.
Pssm-ID: 367362 [Multi-domain] Cd Length: 786 Bit Score: 122.75 E-value: 3.07e-28
serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 ...
472-806
2.24e-11
serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 amino acids), which a highly serine-rich central region that averages over 300 aa in length. Species encoding members of this family of proteins tend to be anaerobic bacteria, including Gram-positive bacteria of the human gut microbiome and Chloroflexi from marine sediments.
Pssm-ID: 468206 [Multi-domain] Cd Length: 1122 Bit Score: 68.49 E-value: 2.24e-11
serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 ...
491-845
7.15e-11
serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 amino acids), which a highly serine-rich central region that averages over 300 aa in length. Species encoding members of this family of proteins tend to be anaerobic bacteria, including Gram-positive bacteria of the human gut microbiome and Chloroflexi from marine sediments.
Pssm-ID: 468206 [Multi-domain] Cd Length: 1122 Bit Score: 66.57 E-value: 7.15e-11
serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 ...
500-862
8.84e-11
serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 amino acids), which a highly serine-rich central region that averages over 300 aa in length. Species encoding members of this family of proteins tend to be anaerobic bacteria, including Gram-positive bacteria of the human gut microbiome and Chloroflexi from marine sediments.
Pssm-ID: 468206 [Multi-domain] Cd Length: 1122 Bit Score: 66.57 E-value: 8.84e-11
serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 ...
223-545
5.56e-08
serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 amino acids), which a highly serine-rich central region that averages over 300 aa in length. Species encoding members of this family of proteins tend to be anaerobic bacteria, including Gram-positive bacteria of the human gut microbiome and Chloroflexi from marine sediments.
Pssm-ID: 468206 [Multi-domain] Cd Length: 1122 Bit Score: 57.32 E-value: 5.56e-08
serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 ...
208-554
1.16e-07
serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 amino acids), which a highly serine-rich central region that averages over 300 aa in length. Species encoding members of this family of proteins tend to be anaerobic bacteria, including Gram-positive bacteria of the human gut microbiome and Chloroflexi from marine sediments.
Pssm-ID: 468206 [Multi-domain] Cd Length: 1122 Bit Score: 56.17 E-value: 1.16e-07
serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 ...
423-657
4.63e-07
serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 amino acids), which a highly serine-rich central region that averages over 300 aa in length. Species encoding members of this family of proteins tend to be anaerobic bacteria, including Gram-positive bacteria of the human gut microbiome and Chloroflexi from marine sediments.
Pssm-ID: 468206 [Multi-domain] Cd Length: 1122 Bit Score: 54.24 E-value: 4.63e-07
serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 ...
448-657
6.45e-06
serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 amino acids), which a highly serine-rich central region that averages over 300 aa in length. Species encoding members of this family of proteins tend to be anaerobic bacteria, including Gram-positive bacteria of the human gut microbiome and Chloroflexi from marine sediments.
Pssm-ID: 468206 [Multi-domain] Cd Length: 1122 Bit Score: 50.39 E-value: 6.45e-06
serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 ...
788-887
4.97e-04
serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 amino acids), which a highly serine-rich central region that averages over 300 aa in length. Species encoding members of this family of proteins tend to be anaerobic bacteria, including Gram-positive bacteria of the human gut microbiome and Chloroflexi from marine sediments.
Pssm-ID: 468206 [Multi-domain] Cd Length: 1122 Bit Score: 44.23 E-value: 4.97e-04
High molecular weight glutenin subunit; Members of this family include high molecular weight ...
649-997
1.51e-03
High molecular weight glutenin subunit; Members of this family include high molecular weight subunits of glutenin. This group of gluten proteins is thought to be largely responsible for the elastic properties of gluten, and hence, doughs. Indeed, glutenin high molecular weight subunits are classified as elastomeric proteins, because the glutenin network can withstand significant deformations without breaking, and return to the original conformation when the stress is removed. Elastomeric proteins differ considerably in amino acid sequence, but they are all polymers whose subunits consist of elastomeric domains, composed of repeated motifs, and non-elastic domains that mediate cross-linking between the subunits. The elastomeric domain motifs are all rich in glycine residues in addition to other hydrophobic residues. High molecular weight glutenin subunits have an extensive central elastomeric domain, flanked by two terminal non-elastic domains that form disulphide cross-links. The central elastomeric domain is characterized by the following three repeated motifs: PGQGQQ, GYYPTS[P/L]QQ, GQQ. It possesses overlapping beta-turns within and between the repeated motifs, and assumes a regular helical secondary structure with a diameter of approx. 1.9 nm and a pitch of approx. 1.5 nm.
Pssm-ID: 367362 [Multi-domain] Cd Length: 786 Bit Score: 42.63 E-value: 1.51e-03
S-100: S-100 domain, which represents the largest family within the superfamily of proteins ...
2-89
1.49e-30
S-100: S-100 domain, which represents the largest family within the superfamily of proteins carrying the Ca-binding EF-hand motif. Note that this S-100 hierarchy contains only S-100 EF-hand domains, other EF-hands have been modeled separately. S100 proteins are expressed exclusively in vertebrates, and are implicated in intracellular and extracellular regulatory activities. Intracellularly, S100 proteins act as Ca-signaling or Ca-buffering proteins. The most unusual characteristic of certain S100 proteins is their occurrence in extracellular space, where they act in a cytokine-like manner through RAGE, the receptor for advanced glycation products. Structural data suggest that many S100 members exist within cells as homo- or heterodimers and even oligomers; oligomerization contributes to their functional diversification. Upon binding calcium, most S100 proteins change conformation to a more open structure exposing a hydrophobic cleft. This hydrophobic surface represents the interaction site of S100 proteins with their target proteins. There is experimental evidence showing that many S100 proteins have multiple binding partners with diverse mode of interaction with different targets. In addition to S100 proteins (such as S100A1,-3,-4,-6,-7,-10,-11,and -13), this group includes the ''fused'' gene family, a group of calcium binding S100-related proteins. The ''fused'' gene family includes multifunctional epidermal differentiation proteins - profilaggrin, trichohyalin, repetin, hornerin, and cornulin; functionally these proteins are associated with keratin intermediate filaments and partially crosslinked to the cell envelope. These ''fused'' gene proteins contain N-terminal sequence with two Ca-binding EF-hands motif, which may be associated with calcium signaling in epidermal cells and autoprocessing in a calcium-dependent manner. In contrast to S100 proteins, "fused" gene family proteins contain an extraordinary high number of almost perfect peptide repeats with regular array of polar and charged residues similar to many known cell envelope proteins.
Pssm-ID: 238131 [Multi-domain] Cd Length: 88 Bit Score: 115.66 E-value: 1.49e-30
High molecular weight glutenin subunit; Members of this family include high molecular weight ...
189-774
3.07e-28
High molecular weight glutenin subunit; Members of this family include high molecular weight subunits of glutenin. This group of gluten proteins is thought to be largely responsible for the elastic properties of gluten, and hence, doughs. Indeed, glutenin high molecular weight subunits are classified as elastomeric proteins, because the glutenin network can withstand significant deformations without breaking, and return to the original conformation when the stress is removed. Elastomeric proteins differ considerably in amino acid sequence, but they are all polymers whose subunits consist of elastomeric domains, composed of repeated motifs, and non-elastic domains that mediate cross-linking between the subunits. The elastomeric domain motifs are all rich in glycine residues in addition to other hydrophobic residues. High molecular weight glutenin subunits have an extensive central elastomeric domain, flanked by two terminal non-elastic domains that form disulphide cross-links. The central elastomeric domain is characterized by the following three repeated motifs: PGQGQQ, GYYPTS[P/L]QQ, GQQ. It possesses overlapping beta-turns within and between the repeated motifs, and assumes a regular helical secondary structure with a diameter of approx. 1.9 nm and a pitch of approx. 1.5 nm.
Pssm-ID: 367362 [Multi-domain] Cd Length: 786 Bit Score: 122.75 E-value: 3.07e-28
High molecular weight glutenin subunit; Members of this family include high molecular weight ...
207-827
9.45e-27
High molecular weight glutenin subunit; Members of this family include high molecular weight subunits of glutenin. This group of gluten proteins is thought to be largely responsible for the elastic properties of gluten, and hence, doughs. Indeed, glutenin high molecular weight subunits are classified as elastomeric proteins, because the glutenin network can withstand significant deformations without breaking, and return to the original conformation when the stress is removed. Elastomeric proteins differ considerably in amino acid sequence, but they are all polymers whose subunits consist of elastomeric domains, composed of repeated motifs, and non-elastic domains that mediate cross-linking between the subunits. The elastomeric domain motifs are all rich in glycine residues in addition to other hydrophobic residues. High molecular weight glutenin subunits have an extensive central elastomeric domain, flanked by two terminal non-elastic domains that form disulphide cross-links. The central elastomeric domain is characterized by the following three repeated motifs: PGQGQQ, GYYPTS[P/L]QQ, GQQ. It possesses overlapping beta-turns within and between the repeated motifs, and assumes a regular helical secondary structure with a diameter of approx. 1.9 nm and a pitch of approx. 1.5 nm.
Pssm-ID: 367362 [Multi-domain] Cd Length: 786 Bit Score: 117.74 E-value: 9.45e-27
High molecular weight glutenin subunit; Members of this family include high molecular weight ...
345-853
1.69e-24
High molecular weight glutenin subunit; Members of this family include high molecular weight subunits of glutenin. This group of gluten proteins is thought to be largely responsible for the elastic properties of gluten, and hence, doughs. Indeed, glutenin high molecular weight subunits are classified as elastomeric proteins, because the glutenin network can withstand significant deformations without breaking, and return to the original conformation when the stress is removed. Elastomeric proteins differ considerably in amino acid sequence, but they are all polymers whose subunits consist of elastomeric domains, composed of repeated motifs, and non-elastic domains that mediate cross-linking between the subunits. The elastomeric domain motifs are all rich in glycine residues in addition to other hydrophobic residues. High molecular weight glutenin subunits have an extensive central elastomeric domain, flanked by two terminal non-elastic domains that form disulphide cross-links. The central elastomeric domain is characterized by the following three repeated motifs: PGQGQQ, GYYPTS[P/L]QQ, GQQ. It possesses overlapping beta-turns within and between the repeated motifs, and assumes a regular helical secondary structure with a diameter of approx. 1.9 nm and a pitch of approx. 1.5 nm.
Pssm-ID: 367362 [Multi-domain] Cd Length: 786 Bit Score: 110.81 E-value: 1.69e-24
S-100A1: S-100A1 domain found in proteins similar to S100A1. S100A1 is a calcium-binding ...
3-86
7.71e-15
S-100A1: S-100A1 domain found in proteins similar to S100A1. S100A1 is a calcium-binding protein belonging to a large S100 vertebrate-specific protein family within the EF-hand superfamily of calcium-binding proteins. Note that the S-100 hierarchy, to which this S-100A1 group belongs, contains only S-100 EF-hand domains, other EF-hands have been modeled separately. As is the case with many other members of S100 protein family, S100A1 is implicated in intracellular and extracellular regulatory activities, including interaction with myosin-associated twitchin kinase, actin-capping protein CapZ, sinapsin I, and tubulin. Structural data suggests that S100A1 proteins exist within cells as antiparallel homodimers, while heterodimers with S100A4 and S100B also has been reported. Upon binding calcium S100A1 changes conformation to expose a hydrophobic cleft which is the interaction site of S100A1 with its more that 20 known target proteins.
Pssm-ID: 240152 [Multi-domain] Cd Length: 92 Bit Score: 71.07 E-value: 7.71e-15
S-100A10_like: S-100A10 domain found in proteins similar to S100A10. S100A10 is a member of ...
3-85
2.16e-14
S-100A10_like: S-100A10 domain found in proteins similar to S100A10. S100A10 is a member of the S100 family of EF-hand superfamily of calcium-binding proteins. Note that the S-100 hierarchy, to which this S-100A1_like group belongs, contains only S-100 EF-hand domains, other EF-hands have been modeled separately. S100 proteins are expressed exclusively in vertebrates, and are implicated in intracellular and extracellular regulatory activities. A unique feature of S100A10 is that it contains mutation in both of the calcium binding sites, making it calcium insensitive. S100A10 has been detected in brain, heart, gastrointestinal tract, kidney, liver, lung, spleen, testes, epidermis, aorta, and thymus. Structural data supports the homo- and hetero-dimeric as well as hetero-tetrameric nature of the protein. S100A10 has multiple binding partners in its calcium free state and is therefore involved in many diverse biological functions.
Pssm-ID: 240157 [Multi-domain] Cd Length: 94 Bit Score: 69.76 E-value: 2.16e-14
serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 ...
472-806
2.24e-11
serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 amino acids), which a highly serine-rich central region that averages over 300 aa in length. Species encoding members of this family of proteins tend to be anaerobic bacteria, including Gram-positive bacteria of the human gut microbiome and Chloroflexi from marine sediments.
Pssm-ID: 468206 [Multi-domain] Cd Length: 1122 Bit Score: 68.49 E-value: 2.24e-11
S-100Z: S-100Z domain found in proteins similar to S100Z. S100Z is a member of the S100 domain ...
1-86
5.68e-11
S-100Z: S-100Z domain found in proteins similar to S100Z. S100Z is a member of the S100 domain family within the EF-hand Ca2+-binding proteins superfamily. Note that the S-100 hierarchy, to which this S-100Z group belongs, contains only S-100 EF-hand domains, other EF-hands have been modeled separately.S100 proteins exhibit unique patterns of tissue- and cell type-specific expression and have been implicated in the Ca2+-dependent regulation of diverse physiological processes, including cell cycle regulation, differentiation, growth, and metabolic control. S100Z is normally expressed in various tissues, with its highest level of expression being in spleen and leukocytes. The function of S100Z remains unclear. Preliminary structural data suggests that S100Z is homodimer, however a heterodimer with S100P has been reported. S100Z is capable of binding calcium ions. When calcium binds to S110Z, the protein experiences a conformational change, which exposes hydrophobic surfaces on the protein. In comparison with their normal tissue counterparts, S100Z gene expression appears to be deregulated in some tumor tissues.
Pssm-ID: 240153 [Multi-domain] Cd Length: 93 Bit Score: 59.89 E-value: 5.68e-11
serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 ...
491-845
7.15e-11
serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 amino acids), which a highly serine-rich central region that averages over 300 aa in length. Species encoding members of this family of proteins tend to be anaerobic bacteria, including Gram-positive bacteria of the human gut microbiome and Chloroflexi from marine sediments.
Pssm-ID: 468206 [Multi-domain] Cd Length: 1122 Bit Score: 66.57 E-value: 7.15e-11
serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 ...
500-862
8.84e-11
serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 amino acids), which a highly serine-rich central region that averages over 300 aa in length. Species encoding members of this family of proteins tend to be anaerobic bacteria, including Gram-positive bacteria of the human gut microbiome and Chloroflexi from marine sediments.
Pssm-ID: 468206 [Multi-domain] Cd Length: 1122 Bit Score: 66.57 E-value: 8.84e-11
S-100B: S-100B domain found in proteins similar to S100B. S100B is a calcium-binding protein ...
3-86
4.01e-10
S-100B: S-100B domain found in proteins similar to S100B. S100B is a calcium-binding protein belonging to a large S100 vertebrate-specific protein family within the EF-hand superfamily of calcium-binding proteins. Note that the S-100 hierarchy, to which this S-100B group belongs, contains only S-100 EF-hand domains, other EF-hands have been modeled separately. S100B is most abundant in glial cells of the central nervous system, predominately in astrocytes. S100B is involved in signal transduction via the inhibition of protein phoshorylation, regulation of enzyme activity and by affecting the calcium homeostasis. Upon calcium binding the S100B homodimer changes conformation to expose a hydrophobic cleft, which represents the interaction site of S100B with its more than 20 known target proteins. These target proteins include several cellular architecture proteins such as tubulin and GFAP; S100B can inhibit polymerization of these oligomeric molecules. Furthermore, S100B inhibits the phosphorylation of multiple kinase substrates including the Alzheimer protein tau and neuromodulin (GAP-43) through a calcium-sensitive interaction with the protein substrates.
Pssm-ID: 240154 [Multi-domain] Cd Length: 88 Bit Score: 57.56 E-value: 4.01e-10
Calgranulins: S-100 domain found in proteins belonging to the Calgranulin subgroup of the S100 ...
3-89
5.88e-10
Calgranulins: S-100 domain found in proteins belonging to the Calgranulin subgroup of the S100 family of EF-hand calcium-modulated proteins, including S100A8, S100A9, and S100A12 . Note that the S-100 hierarchy, to which this Calgranulin group belongs, contains only S-100 EF-hand domains, other EF-hands have been modeled separately. These proteins are expressed mainly in granulocytes, and are involved in inflammation, allergy, and neuritogenesis, as well as in host-parasite response. Calgranulins are modulated not only by calcium, but also by other metals such as zinc and copper. Structural data suggested that calgranulins may exist in multiple structural forms, homodimers, as well as hetero-oligomers. For example, the S100A8/S100A9 complex called calprotectin plays important roles in the regulation of inflammatory processes, wound repair, and regulating zinc-dependent enzymes as well as microbial growth.
Pssm-ID: 240156 [Multi-domain] Cd Length: 88 Bit Score: 56.97 E-value: 5.88e-10
S-100A11: S-100A11 domain found in proteins similar to S100A11. S100A11 is a member of the ...
7-89
3.17e-09
S-100A11: S-100A11 domain found in proteins similar to S100A11. S100A11 is a member of the S-100 domain family within EF-hand Ca2+-binding proteins superfamily. Note that the S-100 hierarchy, to which this S-100A11 group belongs, contains only S-100 EF-hand domains, other EF-hands have been modeled separately. S100 proteins exhibit unique patterns of tissue- and cell type-specific expression and have been implicated in the Ca2+-dependent regulation of diverse physiological processes, including cell cycle regulation, differentiation, growth, and metabolic control . S100 proteins have also been associated with a variety of pathological events, including neoplastic transformation and neurodegenerative diseases such as Alzheimer's, usually via over expression of the protein. S100A11 is expressed in smooth muscle and other tissues and involves in calcium-dependent membrane aggregation, which is important for cell vesiculation . As is the case for many other S100 proteins, S100A11 is homodimer, which is able to form a heterodimer with S100B through subunit exchange. Ca2+ binding to S100A11 results in a conformational change in the protein, exposing a hydrophobic surface that interacts with target proteins. In addition to binding to annexin A1 and A6 S100A11 also interacts with actin and transglutaminase.
Pssm-ID: 240150 [Multi-domain] Cd Length: 89 Bit Score: 54.77 E-value: 3.17e-09
serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 ...
223-545
5.56e-08
serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 amino acids), which a highly serine-rich central region that averages over 300 aa in length. Species encoding members of this family of proteins tend to be anaerobic bacteria, including Gram-positive bacteria of the human gut microbiome and Chloroflexi from marine sediments.
Pssm-ID: 468206 [Multi-domain] Cd Length: 1122 Bit Score: 57.32 E-value: 5.56e-08
serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 ...
208-554
1.16e-07
serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 amino acids), which a highly serine-rich central region that averages over 300 aa in length. Species encoding members of this family of proteins tend to be anaerobic bacteria, including Gram-positive bacteria of the human gut microbiome and Chloroflexi from marine sediments.
Pssm-ID: 468206 [Multi-domain] Cd Length: 1122 Bit Score: 56.17 E-value: 1.16e-07
serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 ...
423-657
4.63e-07
serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 amino acids), which a highly serine-rich central region that averages over 300 aa in length. Species encoding members of this family of proteins tend to be anaerobic bacteria, including Gram-positive bacteria of the human gut microbiome and Chloroflexi from marine sediments.
Pssm-ID: 468206 [Multi-domain] Cd Length: 1122 Bit Score: 54.24 E-value: 4.63e-07
S-100A10: A subgroup of the S-100A10 domain found in proteins similar to S100A10. S100A10 is a ...
18-85
1.36e-06
S-100A10: A subgroup of the S-100A10 domain found in proteins similar to S100A10. S100A10 is a member of the S100 family of EF-hand superfamily of calcium-binding proteins. Note that the S-100 hierarchy, to which this S-100A10 group belongs, contains only S-100 EF-hand domains, other EF-hands have been modeled separately. S100 proteins are expressed exclusively in vertebrates, and are implicated in intracellular and extracellular regulatory activities. A unique feature of S100A10 is that it contains mutation in both of the calcium binding sites, making it calcium insensitive. S100A10 has been detected in brain, heart, gastrointestinal tract, kidney, liver, lung, spleen, testes, epidermis, aorta, and thymus. Structural data supports the homo- and hetero-dimeric as well as hetero-tetrameric nature of the protein. S100A10 has multiple binding partners in its calcium free state and is therefore involved in many diverse biological functions.
Pssm-ID: 240151 [Multi-domain] Cd Length: 91 Bit Score: 47.53 E-value: 1.36e-06
serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 ...
448-657
6.45e-06
serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 amino acids), which a highly serine-rich central region that averages over 300 aa in length. Species encoding members of this family of proteins tend to be anaerobic bacteria, including Gram-positive bacteria of the human gut microbiome and Chloroflexi from marine sediments.
Pssm-ID: 468206 [Multi-domain] Cd Length: 1122 Bit Score: 50.39 E-value: 6.45e-06
S-100A6: S-100A6 domain found in proteins similar to S100A6. S100A6 is a member of the S100 ...
14-89
3.10e-04
S-100A6: S-100A6 domain found in proteins similar to S100A6. S100A6 is a member of the S100 domain family within EF-hand Ca2+-binding proteins superfamily. Note that the S-100 hierarchy, to which this S-100A6 group belongs, contains only S-100 EF-hand domains, other EF-hands have been modeled separately. S100 proteins exhibit unique patterns of tissue- and cell type-specific expression and have been implicated in the Ca2+-dependent regulation of diverse physiological processes, including cell cycle regulation, differentiation, growth, and metabolic control . S100A6 is normally expressed in the G1 phase of the cell cycle in neuronal cells. The function of S100A6 remains unclear, but evidence suggests that it is involved in cell cycle regulation and exocytosis. S100A6 may also be involved in tumorigenesis; the protein is overexpressed in several tumors. Ca2+ binding to S100A6 leads to a conformational change in the protein, which exposes a hydrophobic surface for interaction with target proteins. Several such proteins have been identified: glyceraldehyde-3-phosphate dehydrogenase , annexins 2, 6 and 11 and Calcyclin-Binding Protein (CacyBP).
Pssm-ID: 240155 [Multi-domain] Cd Length: 88 Bit Score: 40.59 E-value: 3.10e-04
TIGR02302 family protein; Members of this family are long (~850 residue) bacterial proteins ...
330-580
3.75e-04
TIGR02302 family protein; Members of this family are long (~850 residue) bacterial proteins from the alpha Proteobacteria. Each has 2-3 predicted transmembrane helices near the N-terminus and a long C-terminal region that includes stretches of Gln/Gly-rich low complexity sequence, predicted by TMHMM to be outside the membrane. In Bradyrhizobium japonicum, two tandem reading frames are together homologous the single members found in other species; the cutoffs scores are set low enough that the longer scores above the trusted cutoff and the shorter above the noise cutoff for this model.
Pssm-ID: 274073 Cd Length: 851 Bit Score: 44.59 E-value: 3.75e-04
serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 ...
788-887
4.97e-04
serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 amino acids), which a highly serine-rich central region that averages over 300 aa in length. Species encoding members of this family of proteins tend to be anaerobic bacteria, including Gram-positive bacteria of the human gut microbiome and Chloroflexi from marine sediments.
Pssm-ID: 468206 [Multi-domain] Cd Length: 1122 Bit Score: 44.23 E-value: 4.97e-04
EF-hand, calcium binding motif; A diverse superfamily of calcium sensors and calcium signal ...
27-75
1.02e-03
EF-hand, calcium binding motif; A diverse superfamily of calcium sensors and calcium signal modulators; most examples in this alignment model have 2 active canonical EF hands. Ca2+ binding induces a conformational change in the EF-hand motif, leading to the activation or inactivation of target proteins. EF-hands tend to occur in pairs or higher copy numbers.
Pssm-ID: 238008 [Multi-domain] Cd Length: 63 Bit Score: 38.30 E-value: 1.02e-03
High molecular weight glutenin subunit; Members of this family include high molecular weight ...
649-997
1.51e-03
High molecular weight glutenin subunit; Members of this family include high molecular weight subunits of glutenin. This group of gluten proteins is thought to be largely responsible for the elastic properties of gluten, and hence, doughs. Indeed, glutenin high molecular weight subunits are classified as elastomeric proteins, because the glutenin network can withstand significant deformations without breaking, and return to the original conformation when the stress is removed. Elastomeric proteins differ considerably in amino acid sequence, but they are all polymers whose subunits consist of elastomeric domains, composed of repeated motifs, and non-elastic domains that mediate cross-linking between the subunits. The elastomeric domain motifs are all rich in glycine residues in addition to other hydrophobic residues. High molecular weight glutenin subunits have an extensive central elastomeric domain, flanked by two terminal non-elastic domains that form disulphide cross-links. The central elastomeric domain is characterized by the following three repeated motifs: PGQGQQ, GYYPTS[P/L]QQ, GQQ. It possesses overlapping beta-turns within and between the repeated motifs, and assumes a regular helical secondary structure with a diameter of approx. 1.9 nm and a pitch of approx. 1.5 nm.
Pssm-ID: 367362 [Multi-domain] Cd Length: 786 Bit Score: 42.63 E-value: 1.51e-03
Database: CDSEARCH/cdd Low complexity filter: no Composition Based Adjustment: yes E-value threshold: 0.01
References:
Wang J et al. (2023), "The conserved domain database in 2023", Nucleic Acids Res.51(D)384-8.
Lu S et al. (2020), "The conserved domain database in 2020", Nucleic Acids Res.48(D)265-8.
Marchler-Bauer A et al. (2017), "CDD/SPARCLE: functional classification of proteins via subfamily domain architectures.", Nucleic Acids Res.45(D)200-3.
of the residues that compose this conserved feature have been mapped to the query sequence.
Click on the triangle to view details about the feature, including a multiple sequence alignment
of your query sequence and the protein sequences used to curate the domain model,
where hash marks (#) above the aligned sequences show the location of the conserved feature residues.
The thumbnail image, if present, provides an approximate view of the feature's location in 3 dimensions.
Click on the triangle for interactive 3D structure viewing options.
Functional characterization of the conserved domain architecture found on the query.
Click here to see more details.
This image shows a graphical summary of conserved domains identified on the query sequence.
The Show Concise/Full Display button at the top of the page can be used to select the desired level of detail: only top scoring hits
(labeled illustration) or all hits
(labeled illustration).
Domains are color coded according to superfamilies
to which they have been assigned. Hits with scores that pass a domain-specific threshold
(specific hits) are drawn in bright colors.
Others (non-specific hits) and
superfamily placeholders are drawn in pastel colors.
if a domain or superfamily has been annotated with functional sites (conserved features),
they are mapped to the query sequence and indicated through sets of triangles
with the same color and shade of the domain or superfamily that provides the annotation. Mouse over the colored bars or triangles to see descriptions of the domains and features.
click on the bars or triangles to view your query sequence embedded in a multiple sequence alignment of the proteins used to develop the corresponding domain model.
The table lists conserved domains identified on the query sequence. Click on the plus sign (+) on the left to display full descriptions, alignments, and scores.
Click on the domain model's accession number to view the multiple sequence alignment of the proteins used to develop the corresponding domain model.
To view your query sequence embedded in that multiple sequence alignment, click on the colored bars in the Graphical Summary portion of the search results page,
or click on the triangles, if present, that represent functional sites (conserved features)
mapped to the query sequence.
Concise Display shows only the best scoring domain model, in each hit category listed below except non-specific hits, for each region on the query sequence.
(labeled illustration) Standard Display shows only the best scoring domain model from each source, in each hit category listed below for each region on the query sequence.
(labeled illustration) Full Display shows all domain models, in each hit category below, that meet or exceed the RPS-BLAST threshold for statistical significance.
(labeled illustration) Four types of hits can be shown, as available,
for each region on the query sequence:
specific hits meet or exceed a domain-specific e-value threshold
(illustrated example)
and represent a very high confidence that the query sequence belongs to the same protein family as the sequences use to create the domain model
non-specific hits
meet or exceed the RPS-BLAST threshold for statistical significance (default E-value cutoff of 0.01, or an E-value selected by user via the
advanced search options)
the domain superfamily to which the specific and non-specific hits belong
multi-domain models that were computationally detected and are likely to contain multiple single domains
Retrieve proteins that contain one or more of the domains present in the query sequence, using the Conserved Domain Architecture Retrieval Tool
(CDART).
Modify your query to search against a different database and/or use advanced search options