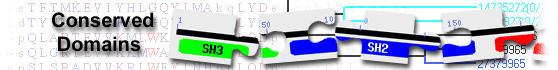uL13 family ribosomal protein similar to human 60S ribosomal protein L13a that is associated with ribosomes but is not required for canonical ribosome function and has extra-ribosomal functions
ribosomal protein uL13, archaeal/eukaryotic form; This model represents ribosomal protein of ...
7-149
1.55e-72
ribosomal protein uL13, archaeal/eukaryotic form; This model represents ribosomal protein of L13 from the Archaea and from the eukaryotic cytosol. Bacterial and organellar forms are represented by model TIGR01066. [Protein synthesis, Ribosomal proteins: synthesis and modification]
Pssm-ID: 162192 Cd Length: 142 Bit Score: 216.14 E-value: 1.55e-72
Ribosomal protein L13. Protein L13, a large ribosomal subunit protein, is one of five ...
8-108
1.44e-38
Ribosomal protein L13. Protein L13, a large ribosomal subunit protein, is one of five proteins required for an early folding intermediate of 23S rRNA in the assembly of the large subunit. L13 is situated on the bottom of the large subunit, near the polypeptide exit site. It interacts with proteins L3 and L6, and forms an extensive network of interactions with 23S rRNA. L13 has been identified as a homolog of the human breast basic conserved protein 1 (BBC1), a protein identified through its increased expression in breast cancer. L13 expression is also upregulated in a variety of human gastrointestinal cancers, suggesting it may play a role in the etiology of a variety of human malignancies.
Pssm-ID: 238230 Cd Length: 114 Bit Score: 128.78 E-value: 1.44e-38
ribosomal protein uL13, archaeal/eukaryotic form; This model represents ribosomal protein of ...
7-149
1.55e-72
ribosomal protein uL13, archaeal/eukaryotic form; This model represents ribosomal protein of L13 from the Archaea and from the eukaryotic cytosol. Bacterial and organellar forms are represented by model TIGR01066. [Protein synthesis, Ribosomal proteins: synthesis and modification]
Pssm-ID: 162192 Cd Length: 142 Bit Score: 216.14 E-value: 1.55e-72
Ribosomal protein L13. Protein L13, a large ribosomal subunit protein, is one of five ...
8-108
1.44e-38
Ribosomal protein L13. Protein L13, a large ribosomal subunit protein, is one of five proteins required for an early folding intermediate of 23S rRNA in the assembly of the large subunit. L13 is situated on the bottom of the large subunit, near the polypeptide exit site. It interacts with proteins L3 and L6, and forms an extensive network of interactions with 23S rRNA. L13 has been identified as a homolog of the human breast basic conserved protein 1 (BBC1), a protein identified through its increased expression in breast cancer. L13 expression is also upregulated in a variety of human gastrointestinal cancers, suggesting it may play a role in the etiology of a variety of human malignancies.
Pssm-ID: 238230 Cd Length: 114 Bit Score: 128.78 E-value: 1.44e-38
Coronavirus (CoV) papain-like protease (PLPro); This model represents the papain-like protease ...
95-149
7.44e-03
Coronavirus (CoV) papain-like protease (PLPro); This model represents the papain-like protease (PLPro) found in non-structural protein 3 (Nsp3) of alpha-, beta-, gamma-, and deltacoronavirus, including highly pathogenic betacoronaviruses such as Severe acute respiratory syndrome-related coronavirus (SARS-CoV), SARS-CoV2 (also called 2019 novel CoV or 2019-nCoV), and Middle East respiratory syndrome-related (MERS) CoV. CoVs utilize a multi-subunit replication/transcription machinery. A set of non-structural proteins (Nsps) generated as cleavage products of the ORF1a and ORF1ab viral polyproteins assemble to facilitate viral replication and transcription. PLPro is a key enzyme in this process, making it a high value target for the development of anti-coronavirus therapeutics. PLPro, which belongs to the MEROPS peptidase C16 family, participates in the proteolytic processing of the N-terminal region of the replicase polyprotein; it can cleave Nsp1|Nsp2, Nsp2|Nsp3, and Nsp3|Nsp4 sites and its activity is dependent on zinc. Besides cleaving the polyproteins, PLPro also possesses a related enzymatic activity to promote virus replication: deubiquitinating (DUB) and de-ISGylating activities. Both, ubiquitin (Ub) and Ub-like interferon-stimulated gene product 15 (ISG15), are involved in preventing viral infection; coronaviruses utilize Ubl-conjugating pathways to counter the pro-inflammatory properties of Ubl-conjugated host proteins via the action of PLPro, which processes both 'Lys-48'- and 'Lys-63'-linked polyubiquitin chains from cellular substrates. The Nsp3 PLPro domain in many of these CoVs has also been shown to antagonize host innate immune induction of type I interferon by interacting with IRF3 and blocking its activation.
Pssm-ID: 409647 Cd Length: 299 Bit Score: 36.31 E-value: 7.44e-03
Database: CDSEARCH/cdd Low complexity filter: no Composition Based Adjustment: yes E-value threshold: 0.01
References:
Wang J et al. (2023), "The conserved domain database in 2023", Nucleic Acids Res.51(D)384-8.
Lu S et al. (2020), "The conserved domain database in 2020", Nucleic Acids Res.48(D)265-8.
Marchler-Bauer A et al. (2017), "CDD/SPARCLE: functional classification of proteins via subfamily domain architectures.", Nucleic Acids Res.45(D)200-3.
of the residues that compose this conserved feature have been mapped to the query sequence.
Click on the triangle to view details about the feature, including a multiple sequence alignment
of your query sequence and the protein sequences used to curate the domain model,
where hash marks (#) above the aligned sequences show the location of the conserved feature residues.
The thumbnail image, if present, provides an approximate view of the feature's location in 3 dimensions.
Click on the triangle for interactive 3D structure viewing options.
Functional characterization of the conserved domain architecture found on the query.
Click here to see more details.
This image shows a graphical summary of conserved domains identified on the query sequence.
The Show Concise/Full Display button at the top of the page can be used to select the desired level of detail: only top scoring hits
(labeled illustration) or all hits
(labeled illustration).
Domains are color coded according to superfamilies
to which they have been assigned. Hits with scores that pass a domain-specific threshold
(specific hits) are drawn in bright colors.
Others (non-specific hits) and
superfamily placeholders are drawn in pastel colors.
if a domain or superfamily has been annotated with functional sites (conserved features),
they are mapped to the query sequence and indicated through sets of triangles
with the same color and shade of the domain or superfamily that provides the annotation. Mouse over the colored bars or triangles to see descriptions of the domains and features.
click on the bars or triangles to view your query sequence embedded in a multiple sequence alignment of the proteins used to develop the corresponding domain model.
The table lists conserved domains identified on the query sequence. Click on the plus sign (+) on the left to display full descriptions, alignments, and scores.
Click on the domain model's accession number to view the multiple sequence alignment of the proteins used to develop the corresponding domain model.
To view your query sequence embedded in that multiple sequence alignment, click on the colored bars in the Graphical Summary portion of the search results page,
or click on the triangles, if present, that represent functional sites (conserved features)
mapped to the query sequence.
Concise Display shows only the best scoring domain model, in each hit category listed below except non-specific hits, for each region on the query sequence.
(labeled illustration) Standard Display shows only the best scoring domain model from each source, in each hit category listed below for each region on the query sequence.
(labeled illustration) Full Display shows all domain models, in each hit category below, that meet or exceed the RPS-BLAST threshold for statistical significance.
(labeled illustration) Four types of hits can be shown, as available,
for each region on the query sequence:
specific hits meet or exceed a domain-specific e-value threshold
(illustrated example)
and represent a very high confidence that the query sequence belongs to the same protein family as the sequences use to create the domain model
non-specific hits
meet or exceed the RPS-BLAST threshold for statistical significance (default E-value cutoff of 0.01, or an E-value selected by user via the
advanced search options)
the domain superfamily to which the specific and non-specific hits belong
multi-domain models that were computationally detected and are likely to contain multiple single domains
Retrieve proteins that contain one or more of the domains present in the query sequence, using the Conserved Domain Architecture Retrieval Tool
(CDART).
Modify your query to search against a different database and/or use advanced search options