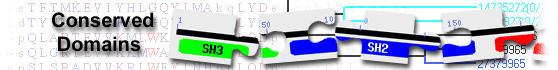|
Name |
Accession |
Description |
Interval |
E-value |
| GBP |
pfam02263 |
Guanylate-binding protein, N-terminal domain; Transcription of the anti-viral ... |
64-319 |
1.99e-65 |
|
Guanylate-binding protein, N-terminal domain; Transcription of the anti-viral guanylate-binding protein (GBP) is induced by interferon-gamma during macrophage induction. This family contains GBP1 and GPB2, both GTPases capable of binding GTP, GDP and GMP.
Pssm-ID: 460516 Cd Length: 260 Bit Score: 221.48 E-value: 1.99e-65
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 64 GRFRMDPEAVAALQLVKGPVGVVSVCGRARQGKSFILNQLLGRSSGFQVASTHRPCTKGLWMWSAPIKRtaldGTEYSLL 143
Cdd:pfam02263 2 HQLELNEEALEILSAITQPVVVVAIAGLYRTGKSFLMNFLAGKLTGFSLGGTVESETKGIWMWCVPHPN----KPKHTLV 77
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 144 LLDTEGI-DAYDQTGTYSIQIFSLAVLLSSMFIYNQMGGIDEAALDRLSLVTEMTKHIRVRaNGGKSTASELGQFSPIFI 222
Cdd:pfam02263 78 LLDTEGLgDVEKSDNKNDAWIFALATLLSSTFVYNSSQTINQQALQQLHLVTELTELSSPR-YGRVADSADFVSFFPDFV 156
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 223 WLLRDFYLDLVENDRKITPRDYLEIALRPLEGRGKDISSKNEIRESIRALFPDRECFTLVRPLNSENELQRLDQIPIEKL 302
Cdd:pfam02263 157 WTVRDFSLPLEADGGPITGDEYLENRLKLSQGQHEELQNFNLPRLCIRSFFPKRKCFLFDRPGLKKALNPQFEGLREDEL 236
|
250
....*....|....*..
gi 1002243137 303 RPEFQAGLDELTRFILE 319
Cdd:pfam02263 237 DPEFQQQLREFCSYILS 253
|
|
| GBP |
cd01851 |
Guanylate-binding protein (GBP) family (N-terminal domain); Guanylate-binding protein (GBP), ... |
77-320 |
9.26e-64 |
|
Guanylate-binding protein (GBP) family (N-terminal domain); Guanylate-binding protein (GBP), N-terminal domain. Guanylate-binding proteins (GBPs) define a group of proteins that are synthesized after activation of the cell by interferons. The biochemical properties of GBPs are clearly different from those of Ras-like and heterotrimeric GTP-binding proteins. They bind guanine nucleotides with low affinity (micromolar range), are stable in their absence and have a high turnover GTPase. In addition to binding GDP/GTP, they have the unique ability to bind GMP with equal affinity and hydrolyze GTP not only to GDP, but also to GMP. Furthermore, two unique regions around the base and the phosphate-binding areas, the guanine and the phosphate caps, respectively, give the nucleotide-binding site a unique appearance not found in the canonical GTP-binding proteins. The phosphate cap, which constitutes the region analogous to switch I, completely shields the phosphate-binding site from solvent such that a potential GTPase-activating protein (GAP) cannot approach.
Pssm-ID: 206650 Cd Length: 224 Bit Score: 215.65 E-value: 9.26e-64
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 77 QLVKGPVGVVSVCGRARQGKSFILNQLLGRSSGFQVASTHRPCTKGLWMWSAPIKRTalDGTEYSLLLLDTEGIDAYDQT 156
Cdd:cd01851 1 LDVGFPVVVVSVFGSQSSGKSFLLNHLFGTSDGFDVMDTSQQTTKGIWMWSDPFKDT--DGKKHAVLLLDTEGTDGRERG 78
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 157 -GTYSIQIFSLAVLLSSMFIYNQMGGIDEAALDRLSLVTEmtkhiRVRANGGKSTASELGQFSPIFIWLLRDFYLDLVEN 235
Cdd:cd01851 79 eFENDARLFALATLLSSVLIYNMWQTILGDDLDKLMGLLK-----TALETLGLAGLHNFSKPKPLLLFVVRDFTGPTPLE 153
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 236 DRKITprdyleialrplEGRGKDISSKNEIRESIRALFPDRECFTLVRPLNSENELQRldQIPIEKLRPEFQAGLDELTR 315
Cdd:cd01851 154 GLDVT------------EKSETLIEELNKIWSSIRKPFTPITCFVLPHPGLLHKLLQN--DGRLKDLPPEFRKALKALRQ 219
|
....*
gi 1002243137 316 FILER 320
Cdd:cd01851 220 RFFSS 224
|
|
| GBP_C |
pfam02841 |
Guanylate-binding protein, C-terminal domain; Transcription of the anti-viral ... |
328-573 |
4.97e-25 |
|
Guanylate-binding protein, C-terminal domain; Transcription of the anti-viral guanylate-binding protein (GBP) is induced by interferon-gamma during macrophage induction. This family contains GBP1 and GPB2, both GTPases capable of binding GTP, GDP and GMP.
Pssm-ID: 460721 [Multi-domain] Cd Length: 297 Bit Score: 106.60 E-value: 4.97e-25
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 328 GTVMTGPVLAGVTQSFLDAINNGAVPTISSSWQSVEEAECRRAYDSAAEVYLSAFDRTKQ-AEE--DALRDAHEAALRKA 404
Cdd:pfam02841 2 GITVTGPRLGSLVQTYVDAINSGAVPCLENAVLALAQIENSAAVQKAIAHYEQQMAQKVKlPTEtlQELLDLHRDCEKEA 81
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 405 LEAYGTVAVGTGTSRmhYEKVLSNFCRKTFQEYKRNAFLEADKQCSNMIQ----IMERKLRAAC-SAPGvKVSNVIQVLE 479
Cdd:pfam02841 82 IAVFMKRSFKDENQE--FQKELVELLEAKKDDFLKQNEEASSKYCSALLQdlsePLEEKISQGTfSKPG-GYKLFLEERD 158
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 480 SLLTEYETScsgPSKWRMLAAFLRQCL------EGPILDLCLKLV-----NEAESERTSFAL------------------ 530
Cdd:pfam02841 159 KLEAKYNQV---PRKGVKAEEVLQEFLqskeavEEAILQTDQALTakekaIEAERAKAEAAEaeqellrekqkeeeqmme 235
|
250 260 270 280
....*....|....*....|....*....|....*....|....
gi 1002243137 531 -KYRSNEDQLELLKRQLEANEAHKseyLKRYEAAISEKQRVSED 573
Cdd:pfam02841 236 aQERSYQEHVKQLIEKMEAEREQL---LAEQERMLEHKLQEQEE 276
|
|
| Smc |
COG1196 |
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; ... |
678-938 |
1.30e-15 |
|
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 440809 [Multi-domain] Cd Length: 983 Bit Score: 81.91 E-value: 1.30e-15
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 678 ERLASVQEQINKIAHEREsgiraEFASHLEEKEEEMKRLVAKIRHAESEESVLAERLQVAESKAQSHNKETAALKDEIRE 757
Cdd:COG1196 239 AELEELEAELEELEAELE-----ELEAELAELEAELEELRLELEELELELEEAQAEEYELLAELARLEQDIARLEERRRE 313
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 758 LTGKLEFLRDRAVSFEKQARMLEQEKNHLQEKFLSECKKYDEAEERYKAAEREAKRATELSDVARTEAVTAQKEKDEAQR 837
Cdd:COG1196 314 LEERLEELEEELAELEEELEELEEELEELEEELEEAEEELEEAEAELAEAEEALLEAEAELAEAEEELEELAEELLEALR 393
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 838 LSMEKLAVIERIQRQVDRLEQEKVNLLDEVQKMHKSETDALSKVALLESRVAEREKEIEELMIQSNEQRSSTVHVLESLL 917
Cdd:COG1196 394 AAAELAAQLEELEEAEEALLERLERLEEELEELEEALAELEEEEEEEEEALEEAAEEEAELEEEEEALLELLAELLEEAA 473
|
250 260
....*....|....*....|.
gi 1002243137 918 STERAARAEANKRAEALSLQL 938
Cdd:COG1196 474 LLEAALAELLEELAEAAARLL 494
|
|
| Smc |
COG1196 |
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; ... |
678-963 |
1.09e-14 |
|
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 440809 [Multi-domain] Cd Length: 983 Bit Score: 79.21 E-value: 1.09e-14
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 678 ERLASVQEQINKIAHERESgIRAEFAS---HLEEKEEEMKRLVAKIRHAESEESVLAERLQVAESKAQSHNKETAALKDE 754
Cdd:COG1196 253 AELEELEAELAELEAELEE-LRLELEElelELEEAQAEEYELLAELARLEQDIARLEERRRELEERLEELEEELAELEEE 331
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 755 IRELTGKLEFLRDRAVSFEKQARMLEQEKNHLQEKFLSECKKYDEAEERYKAAEREAKRATELSDVARTEAVTAQKEKDE 834
Cdd:COG1196 332 LEELEEELEELEEELEEAEEELEEAEAELAEAEEALLEAEAELAEAEEELEELAEELLEALRAAAELAAQLEELEEAEEA 411
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 835 AQRLSMEKLAVIERIQRQVDRLEQEKVNLLDEVQKMHKSETDALSKVALLESRVAEREKEIEELMIQSNEQRSSTVHVLE 914
Cdd:COG1196 412 LLERLERLEEELEELEEALAELEEEEEEEEEALEEAAEEEAELEEEEEALLELLAELLEEAALLEAALAELLEELAEAAA 491
|
250 260 270 280
....*....|....*....|....*....|....*....|....*....
gi 1002243137 915 SLLSTERAARAEANKRAEALSLQLQSTQSKLDVLHQELTSVRLVETALD 963
Cdd:COG1196 492 RLLLLLEAEADYEGFLEGVKAALLLAGLRGLAGAVAVLIGVEAAYEAAL 540
|
|
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
678-948 |
4.07e-14 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 77.40 E-value: 4.07e-14
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 678 ERLASVQEQINKIAHEREsgiraefashleEKEEEMKRLVAKIRHAESEESVLAERLQVAESKAQSHNKETAALKDEIRE 757
Cdd:TIGR02168 239 EELEELQEELKEAEEELE------------ELTAELQELEEKLEELRLEVSELEEEIEELQKELYALANEISRLEQQKQI 306
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 758 LTGKLEFLRDRAVSFEKQARMLEQEKNHLQEKFLSECKKYDEAEERYKAAEREAKRATELSDVARTEAVTAQKEKDEAQR 837
Cdd:TIGR02168 307 LRERLANLERQLEELEAQLEELESKLDELAEELAELEEKLEELKEELESLEAELEELEAELEELESRLEELEEQLETLRS 386
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 838 LSMEKLAVIERIQRQVDRLEQEKVNLLDEVQKMHKSETDALSK-----VALLESRVAEREKEIEELmiqsneqrSSTVHV 912
Cdd:TIGR02168 387 KVAQLELQIASLNNEIERLEARLERLEDRRERLQQEIEELLKKleeaeLKELQAELEELEEELEEL--------QEELER 458
|
250 260 270
....*....|....*....|....*....|....*.
gi 1002243137 913 LESLLSTERAARAEANKRAEALSLQLQSTQSKLDVL 948
Cdd:TIGR02168 459 LEEALEELREELEEAEQALDAAERELAQLQARLDSL 494
|
|
| Smc |
COG1196 |
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; ... |
677-991 |
3.04e-13 |
|
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 440809 [Multi-domain] Cd Length: 983 Bit Score: 74.20 E-value: 3.04e-13
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 677 LERLASVQEQInkiahERESGIRAEFASHLE------EKEEEMKRLVAKIRHAESEESVLA-----ERLQVAESKAQSHN 745
Cdd:COG1196 178 ERKLEATEENL-----ERLEDILGELERQLEplerqaEKAERYRELKEELKELEAELLLLKlreleAELEELEAELEELE 252
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 746 KETAALKDEIRELTGKLEFLRDRAVSFEKQARMLEQEKNHLQEKFLSECKKYDEAEERYKAAEREAKRATELSDVARTEA 825
Cdd:COG1196 253 AELEELEAELAELEAELEELRLELEELELELEEAQAEEYELLAELARLEQDIARLEERRRELEERLEELEEELAELEEEL 332
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 826 VTAQKEKDEAQRLSMEKLAVIERIQRQVDRLEQEKVNLLDEVQKMHKSETDALSKVALLESRVAEREKEIEELMIQSNEQ 905
Cdd:COG1196 333 EELEEELEELEEELEEAEEELEEAEAELAEAEEALLEAEAELAEAEEELEELAEELLEALRAAAELAAQLEELEEAEEAL 412
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 906 RSSTVHVLESLLSTERAARAEANKRAEALSLQLQSTQSKLDVLHQELTSVRLVETALDSKLRTTTHGKRLRENEVGMESV 985
Cdd:COG1196 413 LERLERLEEELEELEEALAELEEEEEEEEEALEEAAEEEAELEEEEEALLELLAELLEEAALLEAALAELLEELAEAAAR 492
|
....*.
gi 1002243137 986 QDMDID 991
Cdd:COG1196 493 LLLLLE 498
|
|
| Smc |
COG1196 |
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; ... |
529-959 |
1.67e-11 |
|
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 440809 [Multi-domain] Cd Length: 983 Bit Score: 68.81 E-value: 1.67e-11
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 529 ALKYRSNEDQLELLKRQLEANE-AHKSEYLKRYEAAISEKQRVSEDHSAHLANLRTKCSTLDERCLSLSKELDlvrhect 607
Cdd:COG1196 212 AERYRELKEELKELEAELLLLKlRELEAELEELEAELEELEAELEELEAELAELEAELEELRLELEELELELE------- 284
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 608 dwrvkyeqyvtQQKAEQDGFISQLATLESRYSSAEGKLGAAREQAAAAQDEATEWRDKYETAAaqakaalERLASVQEQI 687
Cdd:COG1196 285 -----------EAQAEEYELLAELARLEQDIARLEERRRELEERLEELEEELAELEEELEELE-------EELEELEEEL 346
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 688 NKIAHEREsgiraEFASHLEEKEEEMKRLVAKIRHAESEESVLAERLQVAESKAQSHNKETAALKDEIRELTGKLEFLRD 767
Cdd:COG1196 347 EEAEEELE-----EAEAELAEAEEALLEAEAELAEAEEELEELAEELLEALRAAAELAAQLEELEEAEEALLERLERLEE 421
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 768 RAVSFEKQARMLEQEKNHLQEKFLseckkydEAEERYKAAEREAKRATELSDVARTEAVTAQKEKDEAQRLSMEKLAVIE 847
Cdd:COG1196 422 ELEELEEALAELEEEEEEEEEALE-------EAAEEEAELEEEEEALLELLAELLEEAALLEAALAELLEELAEAAARLL 494
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 848 RIQRQVDRLEQEkvnlLDEVQKMHKSetDALSKVALLESRVAEREKEIEELMIQSNEQRSSTVHVLESLLSTERAARAEA 927
Cdd:COG1196 495 LLLEAEADYEGF----LEGVKAALLL--AGLRGLAGAVAVLIGVEAAYEAALEAALAAALQNIVVEDDEVAAAAIEYLKA 568
|
410 420 430
....*....|....*....|....*....|....
gi 1002243137 928 NK--RAEALSLQLQSTQSKLDVLHQELTSVRLVE 959
Cdd:COG1196 569 AKagRATFLPLDKIRARAALAAALARGAIGAAVD 602
|
|
| Smc |
COG1196 |
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; ... |
518-999 |
2.10e-11 |
|
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 440809 [Multi-domain] Cd Length: 983 Bit Score: 68.42 E-value: 2.10e-11
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 518 VNEAESERTSFALKYRSNEDQLELLKRQLEANEAHKSEYLKRYEAAISEKQRVSEDHSAHLANLRTKCSTLDErclsLSK 597
Cdd:COG1196 248 LEELEAELEELEAELAELEAELEELRLELEELELELEEAQAEEYELLAELARLEQDIARLEERRRELEERLEE----LEE 323
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 598 ELDLVRHECTDWRVKYEQYVTQQKAEQdgfiSQLATLESRYSSAEGKLGAAREQAAAAQDEATEWRDKYETAAAQAKAAL 677
Cdd:COG1196 324 ELAELEEELEELEEELEELEEELEEAE----EELEEAEAELAEAEEALLEAEAELAEAEEELEELAEELLEALRAAAELA 399
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 678 ERLASVQEQINKIAHERES--GIRAEFASHLEEKEEEMKRLVAKIRHAESEESVLAERLQVAESKAQSHNKETAALKDEI 755
Cdd:COG1196 400 AQLEELEEAEEALLERLERleEELEELEEALAELEEEEEEEEEALEEAAEEEAELEEEEEALLELLAELLEEAALLEAAL 479
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 756 RELTGKLEFLRDRAVSFEKQARMLEQEKNHLQEKFLSEC---------------KKYDEAEERYKAAEREAKRATELSDV 820
Cdd:COG1196 480 AELLEELAEAAARLLLLLEAEADYEGFLEGVKAALLLAGlrglagavavligveAAYEAALEAALAAALQNIVVEDDEVA 559
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 821 ARTEAVTAQKEKDEAQRLSMEKLAVIERIQRQVDRLEQEK-VNLLDEVQKMHKSETDALSKVALLESRVAEREKEIEELM 899
Cdd:COG1196 560 AAAIEYLKAAKAGRATFLPLDKIRARAALAAALARGAIGAaVDLVASDLREADARYYVLGDTLLGRTLVAARLEAALRRA 639
|
410 420 430 440 450 460 470 480
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 900 IQSNEQRSSTVHVLESLLSTERAARAEANKRAEALSLQLQSTQSKLDVLHQELTSVRLVETALDSKLRTTTHGKRLRENE 979
Cdd:COG1196 640 VTLAGRLREVTLEGEGGSAGGSLTGGSRRELLAALLEAEAELEELAERLAEEELELEEALLAEEEEERELAEAEEERLEE 719
|
490 500
....*....|....*....|
gi 1002243137 980 VGMESVQDMDIDRPERSRKR 999
Cdd:COG1196 720 ELEEEALEEQLEAEREELLE 739
|
|
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
696-954 |
2.51e-11 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 68.16 E-value: 2.51e-11
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 696 SGIRAEFASHLEEKEEEMKRLVAKIRHAESEESVLAERLQVAESKAQSHNKETAALKDEIRELTGKLEFLRDRAVSFEKQ 775
Cdd:TIGR02168 662 TGGSAKTNSSILERRREIEELEEKIEELEEKIAELEKALAELRKELEELEEELEQLRKELEELSRQISALRKDLARLEAE 741
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 776 ARMLEQEKNHLQ---EKFLSECKKYDE--AEERYKAAEREAKRATELSDVA---------RTEAVTAQKEKDEAQRLSME 841
Cdd:TIGR02168 742 VEQLEERIAQLSkelTELEAEIEELEErlEEAEEELAEAEAEIEELEAQIEqlkeelkalREALDELRAELTLLNEEAAN 821
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 842 KLAVIERIQRQVDRLEQEKVNLLDEVQKMHKSETDALSKVALLESRVAEREKEIEELMIQSN-------------EQRSS 908
Cdd:TIGR02168 822 LRERLESLERRIAATERRLEDLEEQIEELSEDIESLAAEIEELEELIEELESELEALLNERAsleealallrselEELSE 901
|
250 260 270 280
....*....|....*....|....*....|....*....|....*.
gi 1002243137 909 TVHVLESLLSTERAARAEANKRAEALSLQLQSTQSKLDVLHQELTS 954
Cdd:TIGR02168 902 ELRELESKRSELRRELEELREKLAQLELRLEGLEVRIDNLQERLSE 947
|
|
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
517-814 |
4.37e-10 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 64.31 E-value: 4.37e-10
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 517 LVNEAESERTSFALKYRSNEDQLELLKRQLEANEAHKSEYLKRYEAAISE-------KQRVSEDHSAHLANLRTKCSTLD 589
Cdd:TIGR02168 660 VITGGSAKTNSSILERRREIEELEEKIEELEEKIAELEKALAELRKELEEleeeleqLRKELEELSRQISALRKDLARLE 739
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 590 ERCLSLSKELDLVRHECTDWRVKYEQY-----------------VTQQKAEQDGFISQLATLESRYSSAEGKLGAAREQA 652
Cdd:TIGR02168 740 AEVEQLEERIAQLSKELTELEAEIEELeerleeaeeelaeaeaeIEELEAQIEQLKEELKALREALDELRAELTLLNEEA 819
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 653 AAAQDEATEWRDKYETAAAQAKAALERLASVQEQINKIAHERESgiraefashLEEKEEEMKRlvaKIRHAESEESVLAE 732
Cdd:TIGR02168 820 ANLRERLESLERRIAATERRLEDLEEQIEELSEDIESLAAEIEE---------LEELIEELES---ELEALLNERASLEE 887
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 733 RLQVAESKAQSHNKETAALKDEIRELTGKLEFLRDRAVSFEKQARMLEQEKNHLQEKFLSECK-KYDEAEERYKAAEREA 811
Cdd:TIGR02168 888 ALALLRSELEELSEELRELESKRSELRRELEELREKLAQLELRLEGLEVRIDNLQERLSEEYSlTLEEAEALENKIEDDE 967
|
...
gi 1002243137 812 KRA 814
Cdd:TIGR02168 968 EEA 970
|
|
| SMC_prok_A |
TIGR02169 |
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ... |
611-957 |
6.69e-09 |
|
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 60.08 E-value: 6.69e-09
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 611 VKYEQYVTQQKAEQDGFISQLATLESRYSSAEGKLGAAREQAAAAQDEATEWRDKYETAAAQAKAALERLASVQEQINKI 690
Cdd:TIGR02169 670 RSEPAELQRLRERLEGLKRELSSLQSELRRIENRLDELSQELSDASRKIGEIEKEIEQLEQEEEKLKERLEELEEDLSSL 749
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 691 AHEResgiraefashlEEKEEEMKRLVAKIrhAESEESVLAERLQVAESKAQshnketaALKDEIRELTGKLEFLRDRAV 770
Cdd:TIGR02169 750 EQEI------------ENVKSELKELEARI--EELEEDLHKLEEALNDLEAR-------LSHSRIPEIQAELSKLEEEVS 808
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 771 SFEKQARMLEQEKN--HLQEKFLSECKKYDEAEERYKAAEREAKRATELSDVARTEAVTAQKEKDEAQRLSMEKlaVIER 848
Cdd:TIGR02169 809 RIEARLREIEQKLNrlTLEKEYLEKEIQELQEQRIDLKEQIKSIEKEIENLNGKKEELEEELEELEAALRDLES--RLGD 886
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 849 IQRQVDRLEQEKVNLLDEVQKMHKSETDALSKVALLESR---VAEREKEIEEL---MIQSNEQRSSTVHVLESLLSTERA 922
Cdd:TIGR02169 887 LKKERDELEAQLRELERKIEELEAQIEKKRKRLSELKAKleaLEEELSEIEDPkgeDEEIPEEELSLEDVQAELQRVEEE 966
|
330 340 350 360
....*....|....*....|....*....|....*....|.
gi 1002243137 923 ARA--EANKRA----EALSLQLQSTQSKLDVLHQELTSVRL 957
Cdd:TIGR02169 967 IRAlePVNMLAiqeyEEVLKRLDELKEKRAKLEEERKAILE 1007
|
|
| SMC_prok_A |
TIGR02169 |
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ... |
678-898 |
8.62e-09 |
|
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 60.08 E-value: 8.62e-09
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 678 ERLASVQEQINKIAHERESGIRAefashLEEKEEEMKRLVAKIRHAESEESVLAERLQVAESKAQSHNKETAALKDEIRE 757
Cdd:TIGR02169 287 EEQLRVKEKIGELEAEIASLERS-----IAEKERELEDAEERLAKLEAEIDKLLAEIEELEREIEEERKRRDKLTEEYAE 361
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 758 LTGKLEFLRDRAVSFEKQARMLEQEKNHLQEKFLSECKKYDEAEERYKAAEREAKRATElsDVARTEAVTAQKEKDEAQr 837
Cdd:TIGR02169 362 LKEELEDLRAELEEVDKEFAETRDELKDYREKLEKLKREINELKRELDRLQEELQRLSE--ELADLNAAIAGIEAKINE- 438
|
170 180 190 200 210 220
....*....|....*....|....*....|....*....|....*....|....*....|.
gi 1002243137 838 LSMEKLAVIERIQRQVDRLEQEKVNLLDEVQKMHKSETDalskVALLESRVAEREKEIEEL 898
Cdd:TIGR02169 439 LEEEKEDKALEIKKQEWKLEQLAADLSKYEQELYDLKEE----YDRVEKELSKLQRELAEA 495
|
|
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
679-956 |
1.15e-08 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 59.69 E-value: 1.15e-08
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 679 RLASVQE---QINKIAHERESGIRaefasHLE---EKEEEMKRLVAKIRHAESeeSVLAERLQVAESKAQSHNKETAALK 752
Cdd:TIGR02168 180 KLERTREnldRLEDILNELERQLK-----SLErqaEKAERYKELKAELRELEL--ALLVLRLEELREELEELQEELKEAE 252
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 753 DEIRELTGKLEFLRDRAVSFEKQARMLEQEKNHLQEKFLSECKKYDEAEERYKAAEREAKRATELSDVARTEAVTAQKEK 832
Cdd:TIGR02168 253 EELEELTAELQELEEKLEELRLEVSELEEEIEELQKELYALANEISRLEQQKQILRERLANLERQLEELEAQLEELESKL 332
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 833 DEAQrlsmEKLAvieRIQRQVDRLEQEKVNLLDEVQKMHKsetdalsKVALLESRVAEREKEIEELmiqsneqrsstvhv 912
Cdd:TIGR02168 333 DELA----EELA---ELEEKLEELKEELESLEAELEELEA-------ELEELESRLEELEEQLETL-------------- 384
|
250 260 270 280
....*....|....*....|....*....|....*....|....
gi 1002243137 913 lESLLSTERAARAEANKRAEALSLQLQSTQSKLDVLHQELTSVR 956
Cdd:TIGR02168 385 -RSKVAQLELQIASLNNEIERLEARLERLEDRRERLQQEIEELL 427
|
|
| CCDC158 |
pfam15921 |
Coiled-coil domain-containing protein 158; CCDC158 is a family of proteins found in eukaryotes. ... |
516-955 |
1.51e-08 |
|
Coiled-coil domain-containing protein 158; CCDC158 is a family of proteins found in eukaryotes. The function is not known.
Pssm-ID: 464943 [Multi-domain] Cd Length: 1112 Bit Score: 58.98 E-value: 1.51e-08
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 516 KLVNEAESERTSFALKYRSNEDQLELLKRQLEAN-EAHKSEYLKRYEAAISEkqrvsedHSAHLANLRTKCSTLDERCLS 594
Cdd:pfam15921 224 KILRELDTEISYLKGRIFPVEDQLEALKSESQNKiELLLQQHQDRIEQLISE-------HEVEITGLTEKASSARSQANS 296
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 595 LSKELDLVRHECTDWRVKYEQYVTQQKAEQDGFISQLATLESRYSSAEGKLGAAREQAAAAQDEATEWRDKYETAAAQAK 674
Cdd:pfam15921 297 IQSQLEIIQEQARNQNSMYMRQLSDLESTVSQLRSELREAKRMYEDKIEELEKQLVLANSELTEARTERDQFSQESGNLD 376
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 675 AALERL----------ASVQEQINKIAHERESG-------IRAEfashLEEKEEEMKRLVAKIRHAESEESVLAERlQVA 737
Cdd:pfam15921 377 DQLQKLladlhkrekeLSLEKEQNKRLWDRDTGnsitidhLRRE----LDDRNMEVQRLEALLKAMKSECQGQMER-QMA 451
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 738 ESKAQSHNKE-----TAALKDEIRELTGKLEFLRDRAVSFEKQARMLEQEKNHLQEKflseckkydeaEERYKAAEREAK 812
Cdd:pfam15921 452 AIQGKNESLEkvsslTAQLESTKEMLRKVVEELTAKKMTLESSERTVSDLTASLQEK-----------ERAIEATNAEIT 520
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 813 RATELSDVARTEAVTAQKEKD---------EAQRLSM-EKLAVIERIQRQVDRLEQ--------------EKVNLLDEVQ 868
Cdd:pfam15921 521 KLRSRVDLKLQELQHLKNEGDhlrnvqtecEALKLQMaEKDKVIEILRQQIENMTQlvgqhgrtagamqvEKAQLEKEIN 600
|
410 420 430 440 450 460 470 480
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 869 ---------KMHKSETDAlsKVALLESRVAEREKEIEELMIQSNEQRSSTVHVLE---SLLSTERAARAEANKRAE---- 932
Cdd:pfam15921 601 drrlelqefKILKDKKDA--KIRELEARVSDLELEKVKLVNAGSERLRAVKDIKQerdQLLNEVKTSRNELNSLSEdyev 678
|
490 500 510 520
....*....|....*....|....*....|....*....|
gi 1002243137 933 -----------------ALSLQLQSTQSKLDVLHQELTSV 955
Cdd:pfam15921 679 lkrnfrnkseemetttnKLKMQLKSAQSELEQTRNTLKSM 718
|
|
| SMC_N |
pfam02463 |
RecF/RecN/SMC N terminal domain; This domain is found at the N terminus of SMC proteins. The ... |
677-1019 |
6.50e-08 |
|
RecF/RecN/SMC N terminal domain; This domain is found at the N terminus of SMC proteins. The SMC (structural maintenance of chromosomes) superfamily proteins have ATP-binding domains at the N- and C-termini, and two extended coiled-coil domains separated by a hinge in the middle. The eukaryotic SMC proteins form two kind of heterodimers: the SMC1/SMC3 and the SMC2/SMC4 types. These heterodimers constitute an essential part of higher order complexes, which are involved in chromatin and DNA dynamics. This family also includes the RecF and RecN proteins that are involved in DNA metabolism and recombination.
Pssm-ID: 426784 [Multi-domain] Cd Length: 1161 Bit Score: 56.90 E-value: 6.50e-08
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 677 LERLASVQEQINKIAHERESGIRAEFASHLEEKEE-------EMKRLVAKIRHAESEESVLAERLQVAESKAQSHNKETA 749
Cdd:pfam02463 175 LKKLIEETENLAELIIDLEELKLQELKLKEQAKKAleyyqlkEKLELEEEYLLYLDYLKLNEERIDLLQELLRDEQEEIE 254
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 750 ALKDEIRELTGKLEFLRDRAVSFEKQARMLEQEKNHLQEKFLSECKKYDEAEERYKAAEREAKRatELSDVARTEAVTAQ 829
Cdd:pfam02463 255 SSKQEIEKEEEKLAQVLKENKEEEKEKKLQEEELKLLAKEEEELKSELLKLERRKVDDEEKLKE--SEKEKKKAEKELKK 332
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 830 KEKDEAQRLSMEKLAVIERIQRQVDRLEQEKVNLLDEVQKmHKSETDALSKVALLESRVAEREKEIEELMIQSNEQRSST 909
Cdd:pfam02463 333 EKEEIEELEKELKELEIKREAEEEEEEELEKLQEKLEQLE-EELLAKKKLESERLSSAAKLKEEELELKSEEEKEAQLLL 411
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 910 V------HVLESLLSTERAARAEANKRAEALSLQLQSTQSKLDVLHQELTSVRLVETaLDSKLRTTTHGKRLRENEVGME 983
Cdd:pfam02463 412 ElarqleDLLKEEKKEELEILEEEEESIELKQGKLTEEKEELEKQELKLLKDELELK-KSEDLLKETQLVKLQEQLELLL 490
|
330 340 350
....*....|....*....|....*....|....*...
gi 1002243137 984 SVQDMDIDRPERSRKRS--KSNTSPLKHFQSEDGGSVH 1019
Cdd:pfam02463 491 SRQKLEERSQKESKARSglKVLLALIKDGVGGRIISAH 528
|
|
| CCDC158 |
pfam15921 |
Coiled-coil domain-containing protein 158; CCDC158 is a family of proteins found in eukaryotes. ... |
475-850 |
1.12e-07 |
|
Coiled-coil domain-containing protein 158; CCDC158 is a family of proteins found in eukaryotes. The function is not known.
Pssm-ID: 464943 [Multi-domain] Cd Length: 1112 Bit Score: 56.28 E-value: 1.12e-07
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 475 IQVLESLLTEYETSCSGPSKWRMLA-----------AFLRQCLEGpILDLCLKLVNEAESERTSFALKYRSNED---QLE 540
Cdd:pfam15921 428 VQRLEALLKAMKSECQGQMERQMAAiqgkneslekvSSLTAQLES-TKEMLRKVVEELTAKKMTLESSERTVSDltaSLQ 506
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 541 LLKRQLEANEAHKSEYLKRYEAAISEKQRVsEDHSAHLANLRTKCSTLDERCLSLSKELDLVRHECTDW----------- 609
Cdd:pfam15921 507 EKERAIEATNAEITKLRSRVDLKLQELQHL-KNEGDHLRNVQTECEALKLQMAEKDKVIEILRQQIENMtqlvgqhgrta 585
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 610 ------RVKYEQYVTQQKAEQDGFISQLATLESRYSSAEGKLGAAREQAAAAQDEATEWRDKYETAAAQAKAALERLASV 683
Cdd:pfam15921 586 gamqveKAQLEKEINDRRLELQEFKILKDKKDAKIRELEARVSDLELEKVKLVNAGSERLRAVKDIKQERDQLLNEVKTS 665
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 684 QEQINKIAHERESgIRAEFASHLEEKEEEMKRLVAKIRHAESEESVLAERLQVAESK-------AQSHNKETAALKDEIR 756
Cdd:pfam15921 666 RNELNSLSEDYEV-LKRNFRNKSEEMETTTNKLKMQLKSAQSELEQTRNTLKSMEGSdghamkvAMGMQKQITAKRGQID 744
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 757 ELTGKLEFLRDRAVSFEKQARMLEQEKNHLQEKF---LSECKKYDEAEERYKAAEREAKRATELSDVARTEAVTA----- 828
Cdd:pfam15921 745 ALQSKIQFLEEAMTNANKEKHFLKEEKNKLSQELstvATEKNKMAGELEVLRSQERRLKEKVANMEVALDKASLQfaecq 824
|
410 420
....*....|....*....|....*
gi 1002243137 829 ---QKEKDEAQRLSMEKLAVIERIQ 850
Cdd:pfam15921 825 diiQRQEQESVRLKLQHTLDVKELQ 849
|
|
| PRK02224 |
PRK02224 |
DNA double-strand break repair Rad50 ATPase; |
532-907 |
1.22e-07 |
|
DNA double-strand break repair Rad50 ATPase;
Pssm-ID: 179385 [Multi-domain] Cd Length: 880 Bit Score: 56.20 E-value: 1.22e-07
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 532 YRSNEDQLELLKRQLEANEAHKSEYLKRYEA---AISEKQRVSEDHSAHLANLRTKC-------STLDERCLSLSKELDL 601
Cdd:PRK02224 246 HEERREELETLEAEIEDLRETIAETEREREElaeEVRDLRERLEELEEERDDLLAEAglddadaEAVEARREELEDRDEE 325
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 602 VRHECTDWRVKyeqyVTQQKAEQDGFISQLATLESRYSSAEGKLGaareqaaAAQDEATEWRDKYETAAAQAKAALERLA 681
Cdd:PRK02224 326 LRDRLEECRVA----AQAHNEEAESLREDADDLEERAEELREEAA-------ELESELEEAREAVEDRREEIEELEEEIE 394
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 682 SVQEQINKIAHERE--SGIRAEFASHLEEKEEEMKRLVAKIRHAES---------------------EESVLAERLQVAE 738
Cdd:PRK02224 395 ELRERFGDAPVDLGnaEDFLEELREERDELREREAELEATLRTARErveeaealleagkcpecgqpvEGSPHVETIEEDR 474
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 739 SKAQSHNKETAALKDEIRELTGKLEFLRDrAVSFEKQARMLEQEKNHLQEKfLSEckKYDEAEERYKAAEREAKRATELS 818
Cdd:PRK02224 475 ERVEELEAELEDLEEEVEEVEERLERAED-LVEAEDRIERLEERREDLEEL-IAE--RRETIEEKRERAEELRERAAELE 550
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 819 DVARTEAVTAQKEKDEAqrlsmeklaviERIQRQVDRLEQEKVNLldevqkmhKSETDALSKVALLESRVAEREKEIEEL 898
Cdd:PRK02224 551 AEAEEKREAAAEAEEEA-----------EEAREEVAELNSKLAEL--------KERIESLERIRTLLAAIADAEDEIERL 611
|
....*....
gi 1002243137 899 miqsNEQRS 907
Cdd:PRK02224 612 ----REKRE 616
|
|
| COG4913 |
COG4913 |
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown]; |
678-870 |
1.70e-07 |
|
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown];
Pssm-ID: 443941 [Multi-domain] Cd Length: 1089 Bit Score: 55.69 E-value: 1.70e-07
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 678 ERLASVQEQINKIAHERESGIRAEFASHLEEKEEEMKRLVAKIRHAESEESVLAERLQVAESKAQSH-NKETAALKDEIR 756
Cdd:COG4913 269 ERLAELEYLRAALRLWFAQRRLELLEAELEELRAELARLEAELERLEARLDALREELDELEAQIRGNgGDRLEQLEREIE 348
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 757 ELTGKLEFLRDRAVSFEKQARMLEQEKNHLQEKFLSECKKYDEAEERYKAAEREAkratelsDVARTEAVTAQKEKDEAQ 836
Cdd:COG4913 349 RLERELEERERRRARLEALLAALGLPLPASAEEFAALRAEAAALLEALEEELEAL-------EEALAEAEAALRDLRREL 421
|
170 180 190
....*....|....*....|....*....|....
gi 1002243137 837 RlsmeklavieRIQRQVDRLEQEKVNLLDEVQKM 870
Cdd:COG4913 422 R----------ELEAEIASLERRKSNIPARLLAL 445
|
|
| CwlO1 |
COG3883 |
Uncharacterized N-terminal coiled-coil domain of peptidoglycan hydrolase CwlO [Function ... |
722-933 |
2.18e-07 |
|
Uncharacterized N-terminal coiled-coil domain of peptidoglycan hydrolase CwlO [Function unknown];
Pssm-ID: 443091 [Multi-domain] Cd Length: 379 Bit Score: 54.45 E-value: 2.18e-07
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 722 HAESEESVLAERLQVAESKAQSHNKETAALKDEIRELTGKLEFLRDRAVSFEKQARMLEQEKNHLQEKflseckkYDEAE 801
Cdd:COG3883 13 FADPQIQAKQKELSELQAELEAAQAELDALQAELEELNEEYNELQAELEALQAEIDKLQAEIAEAEAE-------IEERR 85
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 802 ERYKAAEREAKR-------------ATELSD-VARTEAVTAQKEKDeaqrlsmekLAVIERIQRQVDRLEQEKVNLLDEV 867
Cdd:COG3883 86 EELGERARALYRsggsvsyldvllgSESFSDfLDRLSALSKIADAD---------ADLLEELKADKAELEAKKAELEAKL 156
|
170 180 190 200 210 220
....*....|....*....|....*....|....*....|....*....|....*....|....*.
gi 1002243137 868 QKMHKSETDALSKVALLESRVAEREKEIEELmiqsNEQRSSTVHVLESLLSTERAARAEANKRAEA 933
Cdd:COG3883 157 AELEALKAELEAAKAELEAQQAEQEALLAQL----SAEEAAAEAQLAELEAELAAAEAAAAAAAAA 218
|
|
| EnvC |
COG4942 |
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, ... |
703-936 |
3.95e-07 |
|
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 443969 [Multi-domain] Cd Length: 377 Bit Score: 53.61 E-value: 3.95e-07
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 703 ASHLEEKEEEMKRLVAKIRHAESEESVLAERLQVAESKAQSHNKETAALKDEIRELTGKLEFLRDRAVSFEKQARMLEQE 782
Cdd:COG4942 19 ADAAAEAEAELEQLQQEIAELEKELAALKKEEKALLKQLAALERRIAALARRIRALEQELAALEAELAELEKEIAELRAE 98
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 783 KNHLQEKFlseckkydeaEERYKAAEREAKR--------ATELSDVART-----EAVTAQKEKDEAQRLSMEKL-AVIER 848
Cdd:COG4942 99 LEAQKEEL----------AELLRALYRLGRQpplalllsPEDFLDAVRRlqylkYLAPARREQAEELRADLAELaALRAE 168
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 849 IQRQVDRLEQEKVNLLDEVQKMHKSETDALSKVALLESRVAEREKEIEELmiQSNEQRsstvhvLESLLSTERAARAEAN 928
Cdd:COG4942 169 LEAERAELEALLAELEEERAALEALKAERQKLLARLEKELAELAAELAEL--QQEAEE------LEALIARLEAEAAAAA 240
|
....*...
gi 1002243137 929 KRAEALSL 936
Cdd:COG4942 241 ERTPAAGF 248
|
|
| CCDC158 |
pfam15921 |
Coiled-coil domain-containing protein 158; CCDC158 is a family of proteins found in eukaryotes. ... |
680-1013 |
4.15e-07 |
|
Coiled-coil domain-containing protein 158; CCDC158 is a family of proteins found in eukaryotes. The function is not known.
Pssm-ID: 464943 [Multi-domain] Cd Length: 1112 Bit Score: 54.35 E-value: 4.15e-07
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 680 LASVQEQINKIAHERESGIRAEFASH-------LEEKEEEMKRLVAKIRHAESE-ESVLAERLQVAESKAQSHNKETAAL 751
Cdd:pfam15921 193 LVDFEEASGKKIYEHDSMSTMHFRSLgsaiskiLRELDTEISYLKGRIFPVEDQlEALKSESQNKIELLLQQHQDRIEQL 272
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 752 ----KDEIRELTGKLEFLRDRAVSFEKQARMLEQEKNHLQEKFLSECKKYDEAEERYKAAEREAKRATELS-DVARTEAV 826
Cdd:pfam15921 273 isehEVEITGLTEKASSARSQANSIQSQLEIIQEQARNQNSMYMRQLSDLESTVSQLRSELREAKRMYEDKiEELEKQLV 352
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 827 TAQKEKDEAqrlsmeklavieRIQRqvDRLEQEKVNLLDEVQK----MHKSETDaLSKVALLESRVAEREK----EIEEL 898
Cdd:pfam15921 353 LANSELTEA------------RTER--DQFSQESGNLDDQLQKlladLHKREKE-LSLEKEQNKRLWDRDTgnsiTIDHL 417
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 899 MIQSNEqRSSTVHVLESLLSTERA--------------ARAEANKRAEALSLQLQSTQSKLDVLHQELTSVRLvetALDS 964
Cdd:pfam15921 418 RRELDD-RNMEVQRLEALLKAMKSecqgqmerqmaaiqGKNESLEKVSSLTAQLESTKEMLRKVVEELTAKKM---TLES 493
|
330 340 350 360 370
....*....|....*....|....*....|....*....|....*....|
gi 1002243137 965 KLRTTTH-GKRLRENEVGMESVQdmdiDRPERSRKRSKSNTSPLKHFQSE 1013
Cdd:pfam15921 494 SERTVSDlTASLQEKERAIEATN----AEITKLRSRVDLKLQELQHLKNE 539
|
|
| Cast |
pfam10174 |
RIM-binding protein of the cytomatrix active zone; This is a family of proteins that form part ... |
716-939 |
4.66e-07 |
|
RIM-binding protein of the cytomatrix active zone; This is a family of proteins that form part of the CAZ (cytomatrix at the active zone) complex which is involved in determining the site of synaptic vesicle fusion. The C-terminus is a PDZ-binding motif that binds directly to RIM (a small G protein Rab-3A effector). The family also contains four coiled-coil domains.
Pssm-ID: 431111 [Multi-domain] Cd Length: 766 Bit Score: 54.06 E-value: 4.66e-07
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 716 LVAKIRHA---ESEESVLAERLQVAESKAQSHNKETAALKDEIRELTGKLEFLRDRAVSFEKQARMLEQEKNHLQEKFLS 792
Cdd:pfam10174 333 LTAKEQRAailQTEVDALRLRLEEKESFLNKKTKQLQDLTEEKSTLAGEIRDLKDMLDVKERKINVLQKKIENLQEQLRD 412
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 793 ECKKYDEAEERYKAAEREakraTELSDVARTEAVTAQKEKDEaqrlsmeklaVIERIQRQVDRLEQEKvnlLDEVQKMHK 872
Cdd:pfam10174 413 KDKQLAGLKERVKSLQTD----SSNTDTALTTLEEALSEKER----------IIERLKEQREREDRER---LEELESLKK 475
|
170 180 190 200 210 220
....*....|....*....|....*....|....*....|....*....|....*....|....*..
gi 1002243137 873 SETDALSKVALLESRVAEREKEIEELMIQSNEQRSSTVHVLESLLSTERAARaeaNKRAEALSLQLQ 939
Cdd:pfam10174 476 ENKDLKEKVSALQPELTEKESSLIDLKEHASSLASSGLKKDSKLKSLEIAVE---QKKEECSKLENQ 539
|
|
| PRK02224 |
PRK02224 |
DNA double-strand break repair Rad50 ATPase; |
678-999 |
6.35e-07 |
|
DNA double-strand break repair Rad50 ATPase;
Pssm-ID: 179385 [Multi-domain] Cd Length: 880 Bit Score: 53.51 E-value: 6.35e-07
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 678 ERLASVQEQINKIAHEREsGIRAEfaSHLEEKEEEmkRLVAKIRHAESEESVLAERLQVAESKAQSHNKETAALKDEIRE 757
Cdd:PRK02224 279 EEVRDLRERLEELEEERD-DLLAE--AGLDDADAE--AVEARREELEDRDEELRDRLEECRVAAQAHNEEAESLREDADD 353
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 758 LTGKLEFLRDRAVSFEKQAR--------------MLEQEKNHLQEKFLSECKKYDEAEERYKAAEREAKRATELSDVART 823
Cdd:PRK02224 354 LEERAEELREEAAELESELEeareavedrreeieELEEEIEELRERFGDAPVDLGNAEDFLEELREERDELREREAELEA 433
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 824 EAVTAQKEKDEAQRL---------------------------SMEKL-AVIERIQRQVDRLEqEKVNLLDEVQKMHKSET 875
Cdd:PRK02224 434 TLRTARERVEEAEALleagkcpecgqpvegsphvetieedreRVEELeAELEDLEEEVEEVE-ERLERAEDLVEAEDRIE 512
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 876 DALSKVALLESRVAEREKEIEELMIQSNEQRSStVHVLESLLSTERAARAEANKRAEALSLQLQSTQSKLDVLHQELTSV 955
Cdd:PRK02224 513 RLEERREDLEELIAERRETIEEKRERAEELRER-AAELEAEAEEKREAAAEAEEEAEEAREEVAELNSKLAELKERIESL 591
|
330 340 350 360
....*....|....*....|....*....|....*....|....
gi 1002243137 956 RLVETALDSKLRTTTHGKRLRENEVGMESVQDMDIDRPERSRKR 999
Cdd:PRK02224 592 ERIRTLLAAIADAEDEIERLREKREALAELNDERRERLAEKRER 635
|
|
| SMC_prok_A |
TIGR02169 |
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ... |
522-810 |
1.03e-06 |
|
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 53.15 E-value: 1.03e-06
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 522 ESERTSFALKYRSNEDQLELLKRQLEANEAHkseyLKRYEAAISEKQRVSEDHSAHLANLRTKCSTL-DERCLSLSKELD 600
Cdd:TIGR02169 222 EYEGYELLKEKEALERQKEAIERQLASLEEE----LEKLTEEISELEKRLEEIEQLLEELNKKIKDLgEEEQLRVKEKIG 297
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 601 LVRHE---CTDWRVKYEQYVTQQKAEQDGFISQLATLESRYSSAEGKLGAAREQAAAAQDEATEWRDKYETAA------- 670
Cdd:TIGR02169 298 ELEAEiasLERSIAEKERELEDAEERLAKLEAEIDKLLAEIEELEREIEEERKRRDKLTEEYAELKEELEDLRaeleevd 377
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 671 AQAKAALERLASVQEQINKIAHERESGIRaefashleekeeEMKRLVAKIRHAESEESVLAERLQVAESKAQSHNKETAA 750
Cdd:TIGR02169 378 KEFAETRDELKDYREKLEKLKREINELKR------------ELDRLQEELQRLSEELADLNAAIAGIEAKINELEEEKED 445
|
250 260 270 280 290 300
....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 751 LKDEIRELTGKLEFLRDRAVSFEKQARMLEQEKNHLQEKFLSECKKYDEAEERYKAAERE 810
Cdd:TIGR02169 446 KALEIKKQEWKLEQLAADLSKYEQELYDLKEEYDRVEKELSKLQRELAEAEAQARASEER 505
|
|
| PTZ00121 |
PTZ00121 |
MAEBL; Provisional |
516-932 |
1.31e-06 |
|
MAEBL; Provisional
Pssm-ID: 173412 [Multi-domain] Cd Length: 2084 Bit Score: 52.84 E-value: 1.31e-06
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 516 KLVNEAESERTSFALKYRSNEDQLELLKRQLEANEAHKSEYLKRYEaaisEKQRVSEDHSAHLANLRTKCSTLDERclsl 595
Cdd:PTZ00121 1474 EAKKKAEEAKKADEAKKKAEEAKKKADEAKKAAEAKKKADEAKKAE----EAKKADEAKKAEEAKKADEAKKAEEK---- 1545
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 596 sKELDLVRhectdwrvKYEQYvtqQKAEQDGFISQLATLESRYSSAEGKLGAAREQAAAAQDEATEWRDKYETAAAQAKA 675
Cdd:PTZ00121 1546 -KKADELK--------KAEEL---KKAEEKKKAEEAKKAEEDKNMALRKAEEAKKAEEARIEEVMKLYEEEKKMKAEEAK 1613
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 676 ALERLASVQEQINKIAHERESgiraefASHLEEKEEEMKRLVAKIRHAESEESVLAERLQVAESKAQSHNKETAALKDEI 755
Cdd:PTZ00121 1614 KAEEAKIKAEELKKAEEEKKK------VEQLKKKEAEEKKKAEELKKAEEENKIKAAEEAKKAEEDKKKAEEAKKAEEDE 1687
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 756 RELTGKLEFLRDRAVSFEKQARMLEQEKNHLQEKFLSECKKYDEAEERYKAAEREAKRATElsdvARTEavtaQKEKDEA 835
Cdd:PTZ00121 1688 KKAAEALKKEAEEAKKAEELKKKEAEEKKKAEELKKAEEENKIKAEEAKKEAEEDKKKAEE----AKKD----EEEKKKI 1759
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 836 QRLSMEKLAVIERIQRQVDRLEQEKVNLLDEVQKMHKSET--DALSKVALLE------SRVAEREKE-----IEELMIQS 902
Cdd:PTZ00121 1760 AHLKKEEEKKAEEIRKEKEAVIEEELDEEDEKRRMEVDKKikDIFDNFANIIeggkegNLVINDSKEmedsaIKEVADSK 1839
|
410 420 430
....*....|....*....|....*....|
gi 1002243137 903 NEQRSSTVHVLESLLSTERAARAEANKRAE 932
Cdd:PTZ00121 1840 NMQLEEADAFEKHKFNKNNENGEDGNKEAD 1869
|
|
| PTZ00121 |
PTZ00121 |
MAEBL; Provisional |
516-951 |
1.52e-06 |
|
MAEBL; Provisional
Pssm-ID: 173412 [Multi-domain] Cd Length: 2084 Bit Score: 52.84 E-value: 1.52e-06
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 516 KLVNEAESERTSFALKYRSNEDQLELLKRQLEANEAHKSEYLKRYEAAISEKQRVSEDHSAHLANLRTkcSTLDERCLSL 595
Cdd:PTZ00121 1306 EAKKKAEEAKKADEAKKKAEEAKKKADAAKKKAEEAKKAAEAAKAEAEAAADEAEAAEEKAEAAEKKK--EEAKKKADAA 1383
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 596 SKELDLVRhectdwrvKYEQyvTQQKAEQDgfisQLATLESRYSSAEGKLGAAREQAAAAQDEATEWRDKYETAAAQaka 675
Cdd:PTZ00121 1384 KKKAEEKK--------KADE--AKKKAEED----KKKADELKKAAAAKKKADEAKKKAEEKKKADEAKKKAEEAKKA--- 1446
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 676 alERLASVQEQINKIAHERESGIRAEFASHLEEKEEEMKRLVAKIRHAESEESVLAERLQVAESKAQSHNKETAALKDEI 755
Cdd:PTZ00121 1447 --DEAKKKAEEAKKAEEAKKKAEEAKKADEAKKKAEEAKKADEAKKKAEEAKKKADEAKKAAEAKKKADEAKKAEEAKKA 1524
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 756 RELTGKLEFLRDRAVSFEKQARMLEQEKNHLQEKFLSECKKYDE---AEERYKAAEREAKRATELSDvARTEAVTA---- 828
Cdd:PTZ00121 1525 DEAKKAEEAKKADEAKKAEEKKKADELKKAEELKKAEEKKKAEEakkAEEDKNMALRKAEEAKKAEE-ARIEEVMKlyee 1603
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 829 -------QKEKDEAQRLSMEKLAVIERIQRQVDRLEQEKVNLLDEVQKMHKSETDALSKVALLESRVAEREKEIEELMIQ 901
Cdd:PTZ00121 1604 ekkmkaeEAKKAEEAKIKAEELKKAEEEKKKVEQLKKKEAEEKKKAEELKKAEEENKIKAAEEAKKAEEDKKKAEEAKKA 1683
|
410 420 430 440 450
....*....|....*....|....*....|....*....|....*....|....*....
gi 1002243137 902 SNEQRSSTvhvlESLLSTERAAR---------AEANKRAEALSLQLQSTQSKLDVLHQE 951
Cdd:PTZ00121 1684 EEDEKKAA----EALKKEAEEAKkaeelkkkeAEEKKKAEELKKAEEENKIKAEEAKKE 1738
|
|
| SMC_N |
pfam02463 |
RecF/RecN/SMC N terminal domain; This domain is found at the N terminus of SMC proteins. The ... |
701-1005 |
1.83e-06 |
|
RecF/RecN/SMC N terminal domain; This domain is found at the N terminus of SMC proteins. The SMC (structural maintenance of chromosomes) superfamily proteins have ATP-binding domains at the N- and C-termini, and two extended coiled-coil domains separated by a hinge in the middle. The eukaryotic SMC proteins form two kind of heterodimers: the SMC1/SMC3 and the SMC2/SMC4 types. These heterodimers constitute an essential part of higher order complexes, which are involved in chromatin and DNA dynamics. This family also includes the RecF and RecN proteins that are involved in DNA metabolism and recombination.
Pssm-ID: 426784 [Multi-domain] Cd Length: 1161 Bit Score: 52.28 E-value: 1.83e-06
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 701 EFASHLEEKEEEMKRLVAKIRHAESEESVLAERLQVAESKAQSHNKETAALK-----------DEIRELTGKLEFLRDRA 769
Cdd:pfam02463 160 EEAAGSRLKRKKKEALKKLIEETENLAELIIDLEELKLQELKLKEQAKKALEyyqlkekleleEEYLLYLDYLKLNEERI 239
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 770 VSFEKQARMLEQEKNHLQEKFLSECKKYDEAEERYKAAEREAKRATELSDVARTEAVTAQKEKDEAQRLSMEKLAVIERI 849
Cdd:pfam02463 240 DLLQELLRDEQEEIESSKQEIEKEEEKLAQVLKENKEEEKEKKLQEEELKLLAKEEEELKSELLKLERRKVDDEEKLKES 319
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 850 QRQVDRLEQEKVNLLDEVQKMHKSETDALSKVALLESRVAEREKEIEELmiQSNEQRSSTVHVLESLLSTERAARAEANK 929
Cdd:pfam02463 320 EKEKKKAEKELKKEKEEIEELEKELKELEIKREAEEEEEEELEKLQEKL--EQLEEELLAKKKLESERLSSAAKLKEEEL 397
|
250 260 270 280 290 300 310
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*.
gi 1002243137 930 raEALSLQLQSTQSKLDVLHQELTSVRLVETALDSKLRTTTHGKRLRENEVGMESVQDMDIDRPERSRKRSKSNTS 1005
Cdd:pfam02463 398 --ELKSEEEKEAQLLLELARQLEDLLKEEKKEELEILEEEEESIELKQGKLTEEKEELEKQELKLLKDELELKKSE 471
|
|
| YhaN |
COG4717 |
Uncharacterized conserved protein YhaN, contains AAA domain [Function unknown]; |
498-979 |
4.06e-06 |
|
Uncharacterized conserved protein YhaN, contains AAA domain [Function unknown];
Pssm-ID: 443752 [Multi-domain] Cd Length: 641 Bit Score: 50.92 E-value: 4.06e-06
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 498 LAAFLRQCLEGpildlclKLVNEAESERTSFALKYRSNEDQLELLKRQLEANEAHKseylKRYEAAISEKQRVSEDhsah 577
Cdd:COG4717 39 LLAFIRAMLLE-------RLEKEADELFKPQGRKPELNLKELKELEEELKEAEEKE----EEYAELQEELEELEEE---- 103
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 578 LANLRTKCSTLDERCLSLSKELDLvrhectdwrvkYEQYVTQQKAEQdgfisQLATLESRYSSAEGKLgaareqaaaaqd 657
Cdd:COG4717 104 LEELEAELEELREELEKLEKLLQL-----------LPLYQELEALEA-----ELAELPERLEELEERL------------ 155
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 658 eaTEWRDKyetaaaqakaaLERLASVQEQINKIAHEresgIRAEFASHLEEKEEEMKRLVAKIRHAESEESVLAERLQVA 737
Cdd:COG4717 156 --EELREL-----------EEELEELEAELAELQEE----LEELLEQLSLATEEELQDLAEELEELQQRLAELEEELEEA 218
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 738 ESKAQSHNKETAALKDEI------RELTGKLEFLRDRAVSFEKQARMLEQEKNHLQEK---FLSECKKYDEAEERYKAAE 808
Cdd:COG4717 219 QEELEELEEELEQLENELeaaaleERLKEARLLLLIAAALLALLGLGGSLLSLILTIAgvlFLVLGLLALLFLLLAREKA 298
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 809 REAKRATELSDVARTEAVTAQKEKDEAQRLSMEKLAVIERIQRQVDRLEQEKVNLLDEVQKMHKSETDAL--SKVALLES 886
Cdd:COG4717 299 SLGKEAEELQALPALEELEEEELEELLAALGLPPDLSPEELLELLDRIEELQELLREAEELEEELQLEELeqEIAALLAE 378
|
410 420 430 440 450 460 470 480
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 887 RVAEREKEIEELMIQSNEQRS--STVHVLESLLSTERAARAEANKRA--EALSLQLQSTQSKLDVLHQELTSVRLVETAL 962
Cdd:COG4717 379 AGVEDEEELRAALEQAEEYQElkEELEELEEQLEELLGELEELLEALdeEELEEELEELEEELEELEEELEELREELAEL 458
|
490
....*....|....*..
gi 1002243137 963 DSKLRTTTHGKRLRENE 979
Cdd:COG4717 459 EAELEQLEEDGELAELL 475
|
|
| Myosin_tail_1 |
pfam01576 |
Myosin tail; The myosin molecule is a multi-subunit complex made up of two heavy chains and ... |
660-969 |
8.49e-06 |
|
Myosin tail; The myosin molecule is a multi-subunit complex made up of two heavy chains and four light chains it is a fundamental contractile protein found in all eukaryote cell types. This family consists of the coiled-coil myosin heavy chain tail region. The coiled-coil is composed of the tail from two molecules of myosin. These can then assemble into the macromolecular thick filament. The coiled-coil region provides the structural backbone the thick filament.
Pssm-ID: 460256 [Multi-domain] Cd Length: 1081 Bit Score: 50.17 E-value: 8.49e-06
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 660 TEWRDKYETAAAQAKAALERLASVQEQINKIAHERESGIRA------EFASHLEEKEEEMKRLV-AKIRHAESEESVLA- 731
Cdd:pfam01576 649 LEAKEELERTNKQLRAEMEDLVSSKDDVGKNVHELERSKRAleqqveEMKTQLEELEDELQATEdAKLRLEVNMQALKAq 728
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 732 -ER-LQVAESKAQSHNKetaALKDEIRELTGKLEFLRDR---AVSFEKQarmLEQEKNHLQEKFLSECKKYDEAEERYKA 806
Cdd:pfam01576 729 fERdLQARDEQGEEKRR---QLVKQVRELEAELEDERKQraqAVAAKKK---LELDLKELEAQIDAANKGREEAVKQLKK 802
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 807 AEREAK---RATELSDVARTEAVTAQKEKD------EAQRLSM-EKLAVIERIQRQVdrlEQEKVNLLDEVQKMHKSETD 876
Cdd:pfam01576 803 LQAQMKdlqRELEEARASRDEILAQSKESEkklknlEAELLQLqEDLAASERARRQA---QQERDELADEIASGASGKSA 879
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 877 ALSKVALLESRVAEREKEIEELmiQSN------EQRSSTVHV--LESLLSTERAARAEANKRAEALSLQLQSTQSKLDVL 948
Cdd:pfam01576 880 LQDEKRRLEARIAQLEEELEEE--QSNtellndRLRKSTLQVeqLTTELAAERSTSQKSESARQQLERQNKELKAKLQEM 957
|
330 340
....*....|....*....|..
gi 1002243137 949 HQELTS-VRLVETALDSKLRTT 969
Cdd:pfam01576 958 EGTVKSkFKSSIAALEAKIAQL 979
|
|
| SMC_prok_A |
TIGR02169 |
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ... |
536-824 |
8.68e-06 |
|
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 50.07 E-value: 8.68e-06
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 536 EDQLELLKRQLEANEAHKSEYLKRYEAAISEKQRVSEDHSA---HLANLRTKCSTLDERCLSLSKELDLVRHECTDWRVK 612
Cdd:TIGR02169 208 EKAERYQALLKEKREYEGYELLKEKEALERQKEAIERQLASleeELEKLTEEISELEKRLEEIEQLLEELNKKIKDLGEE 287
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 613 YEQYVTQQKAEQDGFISQL----ATLESRYSSAEGKLGAAREQAAAAQDEATEWRDKYETAAAQAKAALERLASVQEQIN 688
Cdd:TIGR02169 288 EQLRVKEKIGELEAEIASLersiAEKERELEDAEERLAKLEAEIDKLLAEIEELEREIEEERKRRDKLTEEYAELKEELE 367
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 689 KIAHERESgIRAEFASHLEEKEEEMKRLVAKIRHAES---EESVLAERLQVAESKAQSHNKETAALKDEIRELTGKLEFL 765
Cdd:TIGR02169 368 DLRAELEE-VDKEFAETRDELKDYREKLEKLKREINElkrELDRLQEELQRLSEELADLNAAIAGIEAKINELEEEKEDK 446
|
250 260 270 280 290
....*....|....*....|....*....|....*....|....*....|....*....
gi 1002243137 766 RDRAVSFEKQARMLEQEKNHLQEKFLSECKKYDEAEERYKAAEREAKRATELSDVARTE 824
Cdd:TIGR02169 447 ALEIKKQEWKLEQLAADLSKYEQELYDLKEEYDRVEKELSKLQRELAEAEAQARASEER 505
|
|
| Mplasa_alph_rch |
TIGR04523 |
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of ... |
677-956 |
9.26e-06 |
|
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of Mycoplasma species. Members average 750 amino acids in length, including signal peptide. Sequences are predicted (Jpred 3) to be almost entirely alpha-helical. These sequences show strong periodicity (consistent with long alpha helical structures) and low complexity rich in D,E,N,Q, and K. Genes encoding these proteins are often found in tandem. The function is unknown.
Pssm-ID: 275316 [Multi-domain] Cd Length: 745 Bit Score: 49.63 E-value: 9.26e-06
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 677 LERLASVQEQINKiahERESGIRaEFASHLEEKEEEMKRLVAKIRHAESEESVLAERLQVAESKAQSHNKETAALKDEIR 756
Cdd:TIGR04523 396 LESKIQNQEKLNQ---QKDEQIK-KLQQEKELLEKEIERLKETIIKNNSEIKDLTNQDSVKELIIKNLDNTRESLETQLK 471
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 757 ELTG-------KLEFLRDRAVSFEKQARMLEQEKNHLQEKFLSECKKYDEAEERYKAAERE-AKRATELSDVARTeavtA 828
Cdd:TIGR04523 472 VLSRsinkikqNLEQKQKELKSKEKELKKLNEEKKELEEKVKDLTKKISSLKEKIEKLESEkKEKESKISDLEDE----L 547
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 829 QKEKDEAQRLSMEKlaVIERIQRQVDRLEQEKVNLLDEVQKmhksetdalskvalLESRVAEREKEIEELmIQSNEQRSS 908
Cdd:TIGR04523 548 NKDDFELKKENLEK--EIDEKNKEIEELKQTQKSLKKKQEE--------------KQELIDQKEKEKKDL-IKEIEEKEK 610
|
250 260 270 280
....*....|....*....|....*....|....*....|....*...
gi 1002243137 909 TVHVLESLLSTeraaraeANKRAEALSLQLQSTQSKLDVLHQELTSVR 956
Cdd:TIGR04523 611 KISSLEKELEK-------AKKENEKLSSIIKNIKSKKNKLKQEVKQIK 651
|
|
| sbcc |
TIGR00618 |
exonuclease SbcC; All proteins in this family for which functions are known are part of an ... |
678-956 |
1.54e-05 |
|
exonuclease SbcC; All proteins in this family for which functions are known are part of an exonuclease complex with sbcD homologs. This complex is involved in the initiation of recombination to regulate the levels of palindromic sequences in DNA. This family is based on the phylogenomic analysis of JA Eisen (1999, Ph.D. Thesis, Stanford University). [DNA metabolism, DNA replication, recombination, and repair]
Pssm-ID: 129705 [Multi-domain] Cd Length: 1042 Bit Score: 49.20 E-value: 1.54e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 678 ERLASVQEQINKIAHEREsgiraEFASHLEEKEEEMKRLVAKIRHAESEESVLAERLQVAESKAQSHNKetaaLKDEIRE 757
Cdd:TIGR00618 293 APLAAHIKAVTQIEQQAQ-----RIHTELQSKMRSRAKLLMKRAAHVKQQSSIEEQRRLLQTLHSQEIH----IRDAHEV 363
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 758 LTGKLEFLrDRAVSFEKQARMLEQEKNHLQEKFLSECKKYD-EAEERYKAAEREAKRATELSDVARTEA-VTAQKEKDEA 835
Cdd:TIGR00618 364 ATSIREIS-CQQHTLTQHIHTLQQQKTTLTQKLQSLCKELDiLQREQATIDTRTSAFRDLQGQLAHAKKqQELQQRYAEL 442
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 836 QRLSMEKLAVIE----RIQRQVDRLEQEKVNLLDEVQKMHKSETDALSKVALLESRVAEREKEIEELMIQSNEQRSS--- 908
Cdd:TIGR00618 443 CAAAITCTAQCEklekIHLQESAQSLKEREQQLQTKEQIHLQETRKKAVVLARLLELQEEPCPLCGSCIHPNPARQDidn 522
|
250 260 270 280 290 300
....*....|....*....|....*....|....*....|....*....|....*....|.
gi 1002243137 909 -------------TVHVLESLLSTERAARAEANKRAEALSLQLQSTQSKLDVLHQELTSVR 956
Cdd:TIGR00618 523 pgpltrrmqrgeqTYAQLETSEEDVYHQLTSERKQRASLKEQMQEIQQSFSILTQCDNRSK 583
|
|
| Mplasa_alph_rch |
TIGR04523 |
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of ... |
678-954 |
1.74e-05 |
|
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of Mycoplasma species. Members average 750 amino acids in length, including signal peptide. Sequences are predicted (Jpred 3) to be almost entirely alpha-helical. These sequences show strong periodicity (consistent with long alpha helical structures) and low complexity rich in D,E,N,Q, and K. Genes encoding these proteins are often found in tandem. The function is unknown.
Pssm-ID: 275316 [Multi-domain] Cd Length: 745 Bit Score: 48.86 E-value: 1.74e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 678 ERLASVQEQINKIAHERESGIRAEFASHLEEKEEEMKRLVAKIRHAESEESVLAERLQVAESKAQSHNKETAALKDEIRE 757
Cdd:TIGR04523 288 KQLNQLKSEISDLNNQKEQDWNKELKSELKNQEKKLEEIQNQISQNNKIISQLNEQISQLKKELTNSESENSEKQRELEE 367
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 758 LTGKLEFLRDRAVSFEKQARMLEQEKNHLQEKFLSECKKYDEAEERYKAAERE----AKRATELSD--VARTEAVTAQKE 831
Cdd:TIGR04523 368 KQNEIEKLKKENQSYKQEIKNLESQINDLESKIQNQEKLNQQKDEQIKKLQQEkellEKEIERLKEtiIKNNSEIKDLTN 447
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 832 KDEAQRLSMEKL-AVIERIQRQVDRLEQEKVNL---LDEVQKMHKSETDALSK----VALLESRVAEREKEIEELmIQSN 903
Cdd:TIGR04523 448 QDSVKELIIKNLdNTRESLETQLKVLSRSINKIkqnLEQKQKELKSKEKELKKlneeKKELEEKVKDLTKKISSL-KEKI 526
|
250 260 270 280 290
....*....|....*....|....*....|....*....|....*....|...
gi 1002243137 904 EQRSSTVHVLESLLST--ERAARAEANKRAEALSLQLQSTQSKLDVLHQELTS 954
Cdd:TIGR04523 527 EKLESEKKEKESKISDleDELNKDDFELKKENLEKEIDEKNKEIEELKQTQKS 579
|
|
| PTZ00121 |
PTZ00121 |
MAEBL; Provisional |
684-950 |
2.66e-05 |
|
MAEBL; Provisional
Pssm-ID: 173412 [Multi-domain] Cd Length: 2084 Bit Score: 48.60 E-value: 2.66e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 684 QEQINKIAHERESGIRAEFASHLEEKEEEMKRLVAKIRHAEseESVLAERLQVAESKAQSHN-KETAALKDEIRELTGKL 762
Cdd:PTZ00121 1247 EERNNEEIRKFEEARMAHFARRQAAIKAEEARKADELKKAE--EKKKADEAKKAEEKKKADEaKKKAEEAKKADEAKKKA 1324
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 763 EFLRDRAVSFEKQArmlEQEKNHLQEKFLSECKKYDEAEerykAAEREAKRATELSDVARTEAVTAQKEKDEAQRLSMEK 842
Cdd:PTZ00121 1325 EEAKKKADAAKKKA---EEAKKAAEAAKAEAEAAADEAE----AAEEKAEAAEKKKEEAKKKADAAKKKAEEKKKADEAK 1397
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 843 LAVIERIQR--QVDRLEQEKVNlLDEVQKM--HKSETDALSKVALLESRVAEREKEIEELMIQSNEQRSSTvhvlESLLS 918
Cdd:PTZ00121 1398 KKAEEDKKKadELKKAAAAKKK-ADEAKKKaeEKKKADEAKKKAEEAKKADEAKKKAEEAKKAEEAKKKAE----EAKKA 1472
|
250 260 270
....*....|....*....|....*....|..
gi 1002243137 919 TERAARAEANKRAEALSLQLQSTQSKLDVLHQ 950
Cdd:PTZ00121 1473 DEAKKKAEEAKKADEAKKKAEEAKKKADEAKK 1504
|
|
| SCP-1 |
pfam05483 |
Synaptonemal complex protein 1 (SCP-1); Synaptonemal complex protein 1 (SCP-1) is the major ... |
677-906 |
3.07e-05 |
|
Synaptonemal complex protein 1 (SCP-1); Synaptonemal complex protein 1 (SCP-1) is the major component of the transverse filaments of the synaptonemal complex. Synaptonemal complexes are structures that are formed between homologous chromosomes during meiotic prophase.
Pssm-ID: 114219 [Multi-domain] Cd Length: 787 Bit Score: 48.18 E-value: 3.07e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 677 LERLASVQEQINKIAHERESgIRAEFASHLEEKEEEMKRLVAKIRHAESEESVLAERLQVAESKAQSHNKETAALKDEIR 756
Cdd:pfam05483 533 LKQIENLEEKEMNLRDELES-VREEFIQKGDEVKCKLDKSEENARSIEYEVLKKEKQMKILENKCNNLKKQIENKNKNIE 611
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 757 ELTGKLEFLRDRAVSFEKQARMLEQEKNHLQEKFLSECKKYDEAEERY-------KAAEREAKRATELSDVARTEAVTAQ 829
Cdd:pfam05483 612 ELHQENKALKKKGSAENKQLNAYEIKVNKLELELASAKQKFEEIIDNYqkeiedkKISEEKLLEEVEKAKAIADEAVKLQ 691
|
170 180 190 200 210 220 230
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....
gi 1002243137 830 KEKD-EAQRLSMEKLAVIERIQRQVDRLEQEKvnllDEVQKMHKS-ETDALSKVALLESRVAEREKEIEELMIQSNEQR 906
Cdd:pfam05483 692 KEIDkRCQHKIAEMVALMEKHKHQYDKIIEER----DSELGLYKNkEQEQSSAKAALEIELSNIKAELLSLKKQLEIEK 766
|
|
| SCP-1 |
pfam05483 |
Synaptonemal complex protein 1 (SCP-1); Synaptonemal complex protein 1 (SCP-1) is the major ... |
678-937 |
7.06e-05 |
|
Synaptonemal complex protein 1 (SCP-1); Synaptonemal complex protein 1 (SCP-1) is the major component of the transverse filaments of the synaptonemal complex. Synaptonemal complexes are structures that are formed between homologous chromosomes during meiotic prophase.
Pssm-ID: 114219 [Multi-domain] Cd Length: 787 Bit Score: 47.02 E-value: 7.06e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 678 ERLASVQEQINKIAHERESGIrAEFASHLEEKEEEMKRLVAKIRHAESEESVLAERLQVAESKAQSHNKETAALKDEIRE 757
Cdd:pfam05483 222 EKIQHLEEEYKKEINDKEKQV-SLLLIQITEKENKMKDLTFLLEESRDKANQLEEKTKLQDENLKELIEKKDHLTKELED 300
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 758 LTGKLEFLRDRAVSFEKQARMLEQEKNHLQEKFLSECKKYDEAEERYKAAEREAKRAT-ELSDVARTEAVTAQKEKDEAQ 836
Cdd:pfam05483 301 IKMSLQRSMSTQKALEEDLQIATKTICQLTEEKEAQMEELNKAKAAHSFVVTEFEATTcSLEELLRTEQQRLEKNEDQLK 380
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 837 RLSME---KLAVIERIQR----------QVDRLEQEKVNLLDEVQKMHKSETDALSKVALLESRVAEREKEIEELMIQ-- 901
Cdd:pfam05483 381 IITMElqkKSSELEEMTKfknnkeveleELKKILAEDEKLLDEKKQFEKIAEELKGKEQELIFLLQAREKEIHDLEIQlt 460
|
250 260 270 280
....*....|....*....|....*....|....*....|
gi 1002243137 902 ----SNEQRSSTVHVLESLLSTERAARAEANKRAEALSLQ 937
Cdd:pfam05483 461 aiktSEEHYLKEVEDLKTELEKEKLKNIELTAHCDKLLLE 500
|
|
| EnvC |
COG4942 |
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, ... |
729-954 |
8.68e-05 |
|
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 443969 [Multi-domain] Cd Length: 377 Bit Score: 46.30 E-value: 8.68e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 729 VLAERLQVAESKAQSHNKETAALKDEIRELTGKLEFLRDRAVSFEKQARMLEQEKNHLQekflsecKKYDEAEERYKAAE 808
Cdd:COG4942 10 LLALAAAAQADAAAEAEAELEQLQQEIAELEKELAALKKEEKALLKQLAALERRIAALA-------RRIRALEQELAALE 82
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 809 REAKRatelsdvARTEAVTAQKEKDEAQRLSMEKLAVIERIQRqvdrleQEKVNLLDEVQkmhkSETDALSKVALLESRV 888
Cdd:COG4942 83 AELAE-------LEKEIAELRAELEAQKEELAELLRALYRLGR------QPPLALLLSPE----DFLDAVRRLQYLKYLA 145
|
170 180 190 200 210 220
....*....|....*....|....*....|....*....|....*....|....*....|....*.
gi 1002243137 889 AEREKEIEELMIQSNEQRSSTVHvLESLLSTERAARAEANKRAEALSLQLQSTQSKLDVLHQELTS 954
Cdd:COG4942 146 PARREQAEELRADLAELAALRAE-LEAERAELEALLAELEEERAALEALKAERQKLLARLEKELAE 210
|
|
| PRK03918 |
PRK03918 |
DNA double-strand break repair ATPase Rad50; |
706-899 |
9.80e-05 |
|
DNA double-strand break repair ATPase Rad50;
Pssm-ID: 235175 [Multi-domain] Cd Length: 880 Bit Score: 46.60 E-value: 9.80e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 706 LEEKEEEMKRLVAKIRHAESEESVL------AERLQVAESKAQSHNKETAA--------LKDEIRELTGKLEFLRD---R 768
Cdd:PRK03918 471 IEEKERKLRKELRELEKVLKKESELiklkelAEQLKELEEKLKKYNLEELEkkaeeyekLKEKLIKLKGEIKSLKKeleK 550
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 769 AVSFEKQARMLEQEKNHLQEKfLSECKK---------YDEAEERYKAAEREAKRATELSDVARTEAVTAQKEKDEAQRLS 839
Cdd:PRK03918 551 LEELKKKLAELEKKLDELEEE-LAELLKeleelgfesVEELEERLKELEPFYNEYLELKDAEKELEREEKELKKLEEELD 629
|
170 180 190 200 210 220
....*....|....*....|....*....|....*....|....*....|....*....|....
gi 1002243137 840 M--EKLAVIE-RIQRQVDRLEQEKVNLLDEVQKMHKSETDALSK-VALLESRVAEREKEIEELM 899
Cdd:PRK03918 630 KafEELAETEkRLEELRKELEELEKKYSEEEYEELREEYLELSReLAGLRAELEELEKRREEIK 693
|
|
| COG4913 |
COG4913 |
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown]; |
749-956 |
1.11e-04 |
|
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown];
Pssm-ID: 443941 [Multi-domain] Cd Length: 1089 Bit Score: 46.45 E-value: 1.11e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 749 AALKDEIRELTGKLEFLRDRAVSFEKQARMLEQEKNHLQEkflseCKKYDEAEERYKAAEREakratelsdVARTEAvta 828
Cdd:COG4913 613 AALEAELAELEEELAEAEERLEALEAELDALQERREALQR-----LAEYSWDEIDVASAERE---------IAELEA--- 675
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 829 qkEKDEAQRLSMEklavIERIQRQVDRLEQEKVNLLDEVQkmhksetDALSKVALLESRVAEREKEIEELMIQSNEQRSS 908
Cdd:COG4913 676 --ELERLDASSDD----LAALEEQLEELEAELEELEEELD-------ELKGEIGRLEKELEQAEEELDELQDRLEAAEDL 742
|
170 180 190 200 210
....*....|....*....|....*....|....*....|....*....|.
gi 1002243137 909 TVHVLESLLSTERAARAEANKRA---EALSLQLQSTQSKLDVLHQELTSVR 956
Cdd:COG4913 743 ARLELRALLEERFAAALGDAVERelrENLEERIDALRARLNRAEEELERAM 793
|
|
| PRK02224 |
PRK02224 |
DNA double-strand break repair Rad50 ATPase; |
520-941 |
1.33e-04 |
|
DNA double-strand break repair Rad50 ATPase;
Pssm-ID: 179385 [Multi-domain] Cd Length: 880 Bit Score: 46.19 E-value: 1.33e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 520 EAESERTSFALKYRSNEDQLELLKRQLEANEAHKSEYLKRYEAAISEKQRVSEDHSA---HLANLRTKCSTLDER----- 591
Cdd:PRK02224 367 ELESELEEAREAVEDRREEIEELEEEIEELRERFGDAPVDLGNAEDFLEELREERDElreREAELEATLRTARERveeae 446
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 592 -------CLSLSKELDLVRHECTdwRVKYEQYVTQQKAEQDGFISQLATLESRYSSAEgklgaareqaaaaQDEATEWRd 664
Cdd:PRK02224 447 alleagkCPECGQPVEGSPHVET--IEEDRERVEELEAELEDLEEEVEEVEERLERAE-------------DLVEAEDR- 510
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 665 kyetaaaqakaaLERLASVQEQINKIAHERESGIraefashlEEKEEEMKRLVAKIRHAESEESVLAERLQVAESKAQSH 744
Cdd:PRK02224 511 ------------IERLEERREDLEELIAERRETI--------EEKRERAEELRERAAELEAEAEEKREAAAEAEEEAEEA 570
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 745 NKETAALKDEIRELTGKLEFLRDRAVSFEKQARmLEQEKNHLQEKFLSECKKYDEAEERYkAAEREAKRATELS-DVART 823
Cdd:PRK02224 571 REEVAELNSKLAELKERIESLERIRTLLAAIAD-AEDEIERLREKREALAELNDERRERL-AEKRERKRELEAEfDEARI 648
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 824 EavTAQKEKDEAQrlsmeklAVIERIQRQVDRLEQEKVNLLDEVqKMHKSETDALskvalleSRVAEREKEIEElmiqsN 903
Cdd:PRK02224 649 E--EAREDKERAE-------EYLEQVEEKLDELREERDDLQAEI-GAVENELEEL-------EELRERREALEN-----R 706
|
410 420 430 440
....*....|....*....|....*....|....*....|
gi 1002243137 904 EQRSSTVH-VLESLLSTERAARAEANKR-AEALSLQLQST 941
Cdd:PRK02224 707 VEALEALYdEAEELESMYGDLRAELRQRnVETLERMLNET 746
|
|
| DUF5401 |
pfam17380 |
Family of unknown function (DUF5401); This is a family of unknown function found in ... |
663-860 |
1.46e-04 |
|
Family of unknown function (DUF5401); This is a family of unknown function found in Chromadorea.
Pssm-ID: 375164 [Multi-domain] Cd Length: 722 Bit Score: 45.88 E-value: 1.46e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 663 RDKYETAAAQAKAALERLASVQEQ---INKIAHERESGIRAEFASHLEEKEEEMKRlvakIRHAESEESVLAERLQVAES 739
Cdd:pfam17380 395 RQELEAARKVKILEEERQRKIQQQkveMEQIRAEQEEARQREVRRLEEERAREMER----VRLEEQERQQQVERLRQQEE 470
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 740 KAQSHNKETAALKDEIRELTGKLEFLRDRAVSFEKQARMLEQEKNHLQEKFLSECKKYDEAEERYKAAEREAKRATELSD 819
Cdd:pfam17380 471 ERKRKKLELEKEKRDRKRAEEQRRKILEKELEERKQAMIEEERKRKLLEKEMEERQKAIYEEERRREAEEERRKQQEMEE 550
|
170 180 190 200
....*....|....*....|....*....|....*....|.
gi 1002243137 820 VARteaVTAQKEKDEAQRLSMEKLAVIERIQRQVDRLEQEK 860
Cdd:pfam17380 551 RRR---IQEQMRKATEERSRLEAMEREREMMRQIVESEKAR 588
|
|
| PRK03918 |
PRK03918 |
DNA double-strand break repair ATPase Rad50; |
678-898 |
1.62e-04 |
|
DNA double-strand break repair ATPase Rad50;
Pssm-ID: 235175 [Multi-domain] Cd Length: 880 Bit Score: 45.83 E-value: 1.62e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 678 ERLASVQEQINKIAHEREsgiraEFASHLEEKEEEMKRLVAkirhaeseesvLAERLQVAESKAQSHNKETAALKDEIRE 757
Cdd:PRK03918 200 KELEEVLREINEISSELP-----ELREELEKLEKEVKELEE-----------LKEEIEELEKELESLEGSKRKLEEKIRE 263
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 758 LTGKLEFLRDRAVSFEKQARMLEQEK---------NHLQEKFLSECKKYDEAEERY--KAAEREAKRATELSDVARTEAV 826
Cdd:PRK03918 264 LEERIEELKKEIEELEEKVKELKELKekaeeyiklSEFYEEYLDELREIEKRLSRLeeEINGIEERIKELEEKEERLEEL 343
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 827 TAQKE--KDEAQRLS---------MEKLAVIERIQRQVDRLEQEKV-NLLDEVQKMHKSETDALSKV----ALLESRVAE 890
Cdd:PRK03918 344 KKKLKelEKRLEELEerhelyeeaKAKKEELERLKKRLTGLTPEKLeKELEELEKAKEEIEEEISKItariGELKKEIKE 423
|
....*...
gi 1002243137 891 REKEIEEL 898
Cdd:PRK03918 424 LKKAIEEL 431
|
|
| DUF5401 |
pfam17380 |
Family of unknown function (DUF5401); This is a family of unknown function found in ... |
707-945 |
1.78e-04 |
|
Family of unknown function (DUF5401); This is a family of unknown function found in Chromadorea.
Pssm-ID: 375164 [Multi-domain] Cd Length: 722 Bit Score: 45.50 E-value: 1.78e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 707 EEKEEEMKRlvAKIRHAESEESVLAER---LQVAESKAQSHNKETAALKDEIRELTGKLEFLRDRaVSFEKQARMLEQEK 783
Cdd:pfam17380 290 QEKFEKMEQ--ERLRQEKEEKAREVERrrkLEEAEKARQAEMDRQAAIYAEQERMAMERERELER-IRQEERKRELERIR 366
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 784 nhlQEKFLSECKKYDEAE----ERYKAAER-----EAKRATELSDVARTEAVTAQKEKDEAQRLSMEklaviERIQRQVD 854
Cdd:pfam17380 367 ---QEEIAMEISRMRELErlqmERQQKNERvrqelEAARKVKILEEERQRKIQQQKVEMEQIRAEQE-----EARQREVR 438
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 855 RLEQEKVNlldEVQKMHKSETDALSKVALLESRVAEREKEIEELMIQSNEQRSSTVH---VLESLLSTERAARAEANKRA 931
Cdd:pfam17380 439 RLEEERAR---EMERVRLEEQERQQQVERLRQQEEERKRKKLELEKEKRDRKRAEEQrrkILEKELEERKQAMIEEERKR 515
|
250
....*....|....
gi 1002243137 932 EALSLQLQSTQSKL 945
Cdd:pfam17380 516 KLLEKEMEERQKAI 529
|
|
| COG4372 |
COG4372 |
Uncharacterized protein, contains DUF3084 domain [Function unknown]; |
678-945 |
3.18e-04 |
|
Uncharacterized protein, contains DUF3084 domain [Function unknown];
Pssm-ID: 443500 [Multi-domain] Cd Length: 370 Bit Score: 44.51 E-value: 3.18e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 678 ERLASVQEQINKIAHEREsgiraEFASHLEEKEEEMKRLVAKIRHAESEESVLAERLQVAESKAQSHNKETAALKDEIRE 757
Cdd:COG4372 59 EELEQLEEELEQARSELE-----QLEEELEELNEQLQAAQAELAQAQEELESLQEEAEELQEELEELQKERQDLEQQRKQ 133
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 758 LTGKLEFLRDRAVSFEKQARMLEQEKNHLQEKFlsecKKYDEAEERYKAAEREAKRATELSDVARTEAVTAQKEKDEAQR 837
Cdd:COG4372 134 LEAQIAELQSEIAEREEELKELEEQLESLQEEL----AALEQELQALSEAEAEQALDELLKEANRNAEKEEELAEAEKLI 209
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 838 LSMEKLAVIERIQRQVDRLEQEKVNLLdevqKMHKSETDALSKVALLESRVAEREKEIEELMIQSNEQRSSTVHVLESLL 917
Cdd:COG4372 210 ESLPRELAEELLEAKDSLEAKLGLALS----ALLDALELEEDKEELLEEVILKEIEELELAILVEKDTEEEELEIAALEL 285
|
250 260
....*....|....*....|....*...
gi 1002243137 918 STERAARAEANKRAEALSLQLQSTQSKL 945
Cdd:COG4372 286 EALEEAALELKLLALLLNLAALSLIGAL 313
|
|
| Myosin_tail_1 |
pfam01576 |
Myosin tail; The myosin molecule is a multi-subunit complex made up of two heavy chains and ... |
679-961 |
3.27e-04 |
|
Myosin tail; The myosin molecule is a multi-subunit complex made up of two heavy chains and four light chains it is a fundamental contractile protein found in all eukaryote cell types. This family consists of the coiled-coil myosin heavy chain tail region. The coiled-coil is composed of the tail from two molecules of myosin. These can then assemble into the macromolecular thick filament. The coiled-coil region provides the structural backbone the thick filament.
Pssm-ID: 460256 [Multi-domain] Cd Length: 1081 Bit Score: 44.78 E-value: 3.27e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 679 RLASVQEQINKIAHERESgiraefasHLEEKEEEMKRLVAKIRHAESEESVLAERLQVAESKAQSHNKETAALKDEIREL 758
Cdd:pfam01576 65 RLAARKQELEEILHELES--------RLEEEEERSQQLQNEKKKMQQHIQDLEEQLDEEEAARQKLQLEKVTTEAKIKKL 136
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 759 TGKLEFLRDRAVSFEKQARMLEQEKNHLQEKFlseckkydeAEErykaaEREAKRATELSDvaRTEAVTAQKE----KDE 834
Cdd:pfam01576 137 EEDILLLEDQNSKLSKERKLLEERISEFTSNL---------AEE-----EEKAKSLSKLKN--KHEAMISDLEerlkKEE 200
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 835 AQRLSMEKL-----AVIERIQRQVDRLEQEKVNLLDEVQKMHKSETDALSKVALLESRVAEREKEIEELMIQSNEqrsst 909
Cdd:pfam01576 201 KGRQELEKAkrkleGESTDLQEQIAELQAQIAELRAQLAKKEEELQAALARLEEETAQKNNALKKIRELEAQISE----- 275
|
250 260 270 280 290
....*....|....*....|....*....|....*....|....*....|....*...
gi 1002243137 910 vhvLESLLSTERAARAEANKRAEALSLQLQSTQSKL-DVL-----HQELTSVRLVETA 961
Cdd:pfam01576 276 ---LQEDLESERAARNKAEKQRRDLGEELEALKTELeDTLdttaaQQELRSKREQEVT 330
|
|
| PTZ00121 |
PTZ00121 |
MAEBL; Provisional |
704-932 |
3.49e-04 |
|
MAEBL; Provisional
Pssm-ID: 173412 [Multi-domain] Cd Length: 2084 Bit Score: 45.13 E-value: 3.49e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 704 SHLEEKEEEMKRLVAKirHAESEESVLAERLQVAES-KAQSHNKETAALK--DEIRELTgklEFLRDRAVSFEKQARMLE 780
Cdd:PTZ00121 1075 SYKDFDFDAKEDNRAD--EATEEAFGKAEEAKKTETgKAEEARKAEEAKKkaEDARKAE---EARKAEDARKAEEARKAE 1149
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 781 QEKNHLQEKFLSECKKYDEAEERYKAAEREAKRATElsDVARTEAVtaqKEKDEAQRLSMEKLAVIERIQRQVDRLEQEK 860
Cdd:PTZ00121 1150 DAKRVEIARKAEDARKAEEARKAEDAKKAEAARKAE--EVRKAEEL---RKAEDARKAEAARKAEEERKAEEARKAEDAK 1224
|
170 180 190 200 210 220 230
....*....|....*....|....*....|....*....|....*....|....*....|....*....|..
gi 1002243137 861 vnLLDEVQKMHKSETDAlskvalLESRVAEREKEIEELMiQSNEQRSSTVHVLESLLSTERAARAEANKRAE 932
Cdd:PTZ00121 1225 --KAEAVKKAEEAKKDA------EEAKKAEEERNNEEIR-KFEEARMAHFARRQAAIKAEEARKADELKKAE 1287
|
|
| CwlO1 |
COG3883 |
Uncharacterized N-terminal coiled-coil domain of peptidoglycan hydrolase CwlO [Function ... |
773-954 |
3.53e-04 |
|
Uncharacterized N-terminal coiled-coil domain of peptidoglycan hydrolase CwlO [Function unknown];
Pssm-ID: 443091 [Multi-domain] Cd Length: 379 Bit Score: 44.05 E-value: 3.53e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 773 EKQARMLEQEKNHLQEKFLSECKKYDEAEERYKAAEREAKRATELSDVARTEAVTAQKEKDEAQRLSMEKLAVIERIQRQ 852
Cdd:COG3883 22 QKELSELQAELEAAQAELDALQAELEELNEEYNELQAELEALQAEIDKLQAEIAEAEAEIEERREELGERARALYRSGGS 101
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 853 VDRLE--------QEKVNLLDEVQKMHKSETDALSKVALLESRVAEREKEIEELMIQSNEQRSStvhvLESLLSTERAAR 924
Cdd:COG3883 102 VSYLDvllgsesfSDFLDRLSALSKIADADADLLEELKADKAELEAKKAELEAKLAELEALKAE----LEAAKAELEAQQ 177
|
170 180 190
....*....|....*....|....*....|
gi 1002243137 925 AEANKRAEALSLQLQSTQSKLDVLHQELTS 954
Cdd:COG3883 178 AEQEALLAQLSAEEAAAEAQLAELEAELAA 207
|
|
| CwlO1 |
COG3883 |
Uncharacterized N-terminal coiled-coil domain of peptidoglycan hydrolase CwlO [Function ... |
821-968 |
3.99e-04 |
|
Uncharacterized N-terminal coiled-coil domain of peptidoglycan hydrolase CwlO [Function unknown];
Pssm-ID: 443091 [Multi-domain] Cd Length: 379 Bit Score: 44.05 E-value: 3.99e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 821 ARTEAVTAQKEKDEAQRLSMEKLAVIERIQRQVDRLEQEKVNLLDEVQKMHKSETDALSKVALLESRVAEREKEIEElMI 900
Cdd:COG3883 14 ADPQIQAKQKELSELQAELEAAQAELDALQAELEELNEEYNELQAELEALQAEIDKLQAEIAEAEAEIEERREELGE-RA 92
|
90 100 110 120 130 140
....*....|....*....|....*....|....*....|....*....|....*....|....*...
gi 1002243137 901 QSNEQRSSTVHVLESLLSTERAarAEANKRAEALSLQLQSTQSKLDVLHQELTSVRLVETALDSKLRT 968
Cdd:COG3883 93 RALYRSGGSVSYLDVLLGSESF--SDFLDRLSALSKIADADADLLEELKADKAELEAKKAELEAKLAE 158
|
|
| tolA |
PRK09510 |
cell envelope integrity inner membrane protein TolA; Provisional |
684-835 |
5.66e-04 |
|
cell envelope integrity inner membrane protein TolA; Provisional
Pssm-ID: 236545 [Multi-domain] Cd Length: 387 Bit Score: 43.64 E-value: 5.66e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 684 QEQINKIAHERESGIRAEFASHLEE-KEEEMKRLVA-KIRHAESEESVLAERLQVAESKAQSHNKETAALKDEIREltgk 761
Cdd:PRK09510 78 EEQRKKKEQQQAEELQQKQAAEQERlKQLEKERLAAqEQKKQAEEAAKQAALKQKQAEEAAAKAAAAAKAKAEAEA---- 153
|
90 100 110 120 130 140 150
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....
gi 1002243137 762 lEFLRDRAVSFEKQARMLEQEKNhlQEKFLSECKKYDEAEERYKAAEREAKRATELSDvARTEAVTAQKEKDEA 835
Cdd:PRK09510 154 -KRAAAAAKKAAAEAKKKAEAEA--AKKAAAEAKKKAEAEAAAKAAAEAKKKAEAEAK-KKAAAEAKKKAAAEA 223
|
|
| ERM_helical |
pfam20492 |
Ezrin/radixin/moesin, alpha-helical domain; The ERM family consists of three closely-related ... |
723-837 |
6.05e-04 |
|
Ezrin/radixin/moesin, alpha-helical domain; The ERM family consists of three closely-related proteins, ezrin, radixin and moesin. Ezrin was first identified as a constituent of microvilli, radixin as a barbed, end-capping actin-modulating protein from isolated junctional fractions, and moesin as a heparin binding protein. A tumour suppressor molecule responsible for neurofibromatosis type 2 (NF2) is highly similar to ERM proteins and has been designated merlin (moesin-ezrin-radixin-like protein). ERM molecules contain 3 domains, an N-terminal globular domain, an extended alpha-helical domain and a charged C-terminal domain (pfam00769). Ezrin, radixin and merlin also contain a polyproline linker region between the helical and C-terminal domains. The N-terminal domain is highly conserved and is also found in merlin, band 4.1 proteins and members of the band 4.1 superfamily, designated the FERM domain. ERM proteins crosslink actin filaments with plasma membranes. They co-localize with CD44 at actin filament plasma membrane interaction sites, associating with CD44 via their N-terminal domains and with actin filaments via their C-terminal domains. This is the alpha-helical domain, which is involved in intramolecular masking of protein-protein interaction sites, regulating the activity of this proteins.
Pssm-ID: 466641 [Multi-domain] Cd Length: 120 Bit Score: 40.67 E-value: 6.05e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 723 AESEESVLAERLQVAESKAQSHNKETAALKDEIRELTGKLEFLRDRAVSFEKQARMLEQEKNHLQEKFLSECKKYDEAEE 802
Cdd:pfam20492 4 AEREKQELEERLKQYEEETKKAQEELEESEETAEELEEERRQAEEEAERLEQKRQEAEEEKERLEESAEMEAEEKEQLEA 83
|
90 100 110
....*....|....*....|....*....|....*
gi 1002243137 803 RYKAAEREAKRATELSDVARTEAVTAQKEKDEAQR 837
Cdd:pfam20492 84 ELAEAQEEIARLEEEVERKEEEARRLQEELEEARE 118
|
|
| COG4372 |
COG4372 |
Uncharacterized protein, contains DUF3084 domain [Function unknown]; |
677-962 |
7.08e-04 |
|
Uncharacterized protein, contains DUF3084 domain [Function unknown];
Pssm-ID: 443500 [Multi-domain] Cd Length: 370 Bit Score: 43.35 E-value: 7.08e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 677 LERLASVQEQINKIAHEresgiraefashLEEKEEEMKRLVAKIRHAESEESVLAERLQVAESKAQSHNKETAALKDEIR 756
Cdd:COG4372 37 LFELDKLQEELEQLREE------------LEQAREELEQLEEELEQARSELEQLEEELEELNEQLQAAQAELAQAQEELE 104
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 757 ELTGKLEFLRDRAVSFEKQARMLEQEKNHLQEKFLSECKKYDEAEERYKAAEREAKRATE-----LSDVARTEAVTAQKE 831
Cdd:COG4372 105 SLQEEAEELQEELEELQKERQDLEQQRKQLEAQIAELQSEIAEREEELKELEEQLESLQEelaalEQELQALSEAEAEQA 184
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 832 KDEAQRLSMEKLAVIERIQRQVDRLEQEKVNLLDEV--QKMHKSETDALSKVALLESRVAEREKEIEELMIQSNEQRSST 909
Cdd:COG4372 185 LDELLKEANRNAEKEEELAEAEKLIESLPRELAEELleAKDSLEAKLGLALSALLDALELEEDKEELLEEVILKEIEELE 264
|
250 260 270 280 290
....*....|....*....|....*....|....*....|....*....|...
gi 1002243137 910 VHVLESLLSTERAARAEANKRAEALSLQLQSTQSKLDVLHQELTSVRLVETAL 962
Cdd:COG4372 265 LAILVEKDTEEEELEIAALELEALEEAALELKLLALLLNLAALSLIGALEDAL 317
|
|
| COG4913 |
COG4913 |
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown]; |
706-911 |
1.35e-03 |
|
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown];
Pssm-ID: 443941 [Multi-domain] Cd Length: 1089 Bit Score: 42.98 E-value: 1.35e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 706 LEEKEEEMKRLVAKIRHAESEESVLaeRLQVAESKAQSHNKETAALKDEIRELTGKLEFLRDRAVSFEKQARMLEQEKNH 785
Cdd:COG4913 257 IRELAERYAAARERLAELEYLRAAL--RLWFAQRRLELLEAELEELRAELARLEAELERLEARLDALREELDELEAQIRG 334
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 786 LQEKFLSECKK-YDEAEERYKAAEREAKRATELSDVARTEAVTAQKEKDEAQRLSMEKLaviERIQRQVDRLEQEKVNLL 864
Cdd:COG4913 335 NGGDRLEQLEReIERLERELEERERRRARLEALLAALGLPLPASAEEFAALRAEAAALL---EALEEELEALEEALAEAE 411
|
170 180 190 200
....*....|....*....|....*....|....*....|....*..
gi 1002243137 865 DEVQKmhksetdalskvalLESRVAEREKEIEELmiqsnEQRSSTVH 911
Cdd:COG4913 412 AALRD--------------LRRELRELEAEIASL-----ERRKSNIP 439
|
|
| Ras_like_GTPase |
cd00882 |
Rat sarcoma (Ras)-like superfamily of small guanosine triphosphatases (GTPases); Ras-like ... |
88-157 |
1.39e-03 |
|
Rat sarcoma (Ras)-like superfamily of small guanosine triphosphatases (GTPases); Ras-like GTPase superfamily. The Ras-like superfamily of small GTPases consists of several families with an extremely high degree of structural and functional similarity. The Ras superfamily is divided into at least four families in eukaryotes: the Ras, Rho, Rab, and Sar1/Arf families. This superfamily also includes proteins like the GTP translation factors, Era-like GTPases, and G-alpha chain of the heterotrimeric G proteins. Members of the Ras superfamily regulate a wide variety of cellular functions: the Ras family regulates gene expression, the Rho family regulates cytoskeletal reorganization and gene expression, the Rab and Sar1/Arf families regulate vesicle trafficking, and the Ran family regulates nucleocytoplasmic transport and microtubule organization. The GTP translation factor family regulates initiation, elongation, termination, and release in translation, and the Era-like GTPase family regulates cell division, sporulation, and DNA replication. Members of the Ras superfamily are identified by the GTP binding site, which is made up of five characteristic sequence motifs, and the switch I and switch II regions.
Pssm-ID: 206648 [Multi-domain] Cd Length: 161 Bit Score: 40.52 E-value: 1.39e-03
10 20 30 40 50 60 70
....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 88 VCGRARQGKSFILNQLLGRSSGfqVASTHRPCTKGLWMWSAPIkrtalDGTEYSLLLLDTEGIDAYDQTG 157
Cdd:cd00882 2 VVGRGGVGKSSLLNALLGGEVG--EVSDVPGTTRDPDVYVKEL-----DKGKVKLVLVDTPGLDEFGGLG 64
|
|
| PRK12704 |
PRK12704 |
phosphodiesterase; Provisional |
707-919 |
1.50e-03 |
|
phosphodiesterase; Provisional
Pssm-ID: 237177 [Multi-domain] Cd Length: 520 Bit Score: 42.46 E-value: 1.50e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 707 EEKEEEMKRLVAKIRHAESEESVLAERLQVAESKAQSHNKETAA---LKDEIRELTGKLEFLRDRAVSFEKQARMLEQEK 783
Cdd:PRK12704 30 EAKIKEAEEEAKRILEEAKKEAEAIKKEALLEAKEEIHKLRNEFekeLRERRNELQKLEKRLLQKEENLDRKLELLEKRE 109
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 784 NHLQEKFLSECKKYDEAEERYKAAER-EAKRATELSDVArteAVTAqkekDEAQRLSMEKLavieriqrqVDRLEQEKVN 862
Cdd:PRK12704 110 EELEKKEKELEQKQQELEKKEEELEElIEEQLQELERIS---GLTA----EEAKEILLEKV---------EEEARHEAAV 173
|
170 180 190 200 210
....*....|....*....|....*....|....*....|....*....|....*..
gi 1002243137 863 LldevqkMHKSETDAlskvallesrVAEREKEIEELMIQSNeQRSSTVHVLESLLST 919
Cdd:PRK12704 174 L------IKEIEEEA----------KEEADKKAKEILAQAI-QRCAADHVAETTVSV 213
|
|
| Smc |
COG1196 |
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; ... |
693-864 |
1.51e-03 |
|
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 440809 [Multi-domain] Cd Length: 983 Bit Score: 42.62 E-value: 1.51e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 693 ERESGIRAEFASHLEEKEEEMKRLVAKIRHAESEESVLAERLQVAESKAQSHNKETAALKDEIRELTGKLEFLRDRAVSF 772
Cdd:COG1196 609 READARYYVLGDTLLGRTLVAARLEAALRRAVTLAGRLREVTLEGEGGSAGGSLTGGSRRELLAALLEAEAELEELAERL 688
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 773 EKQARMLEQEKNHLQEKFLSECKKYDEAEERYKAAEREAKRATELSDVARTEAVTAQKEKDEAQRLSMEKLAVIERIQRQ 852
Cdd:COG1196 689 AEEELELEEALLAEEEEERELAEAEEERLEEELEEEALEEQLEAEREELLEELLEEEELLEEEALEELPEPPDLEELERE 768
|
170
....*....|....*..
gi 1002243137 853 VDRLEQE-----KVNLL 864
Cdd:COG1196 769 LERLEREiealgPVNLL 785
|
|
| DR0291 |
COG1579 |
Predicted nucleic acid-binding protein DR0291, contains C4-type Zn-ribbon domain [General ... |
706-870 |
2.05e-03 |
|
Predicted nucleic acid-binding protein DR0291, contains C4-type Zn-ribbon domain [General function prediction only];
Pssm-ID: 441187 [Multi-domain] Cd Length: 236 Bit Score: 41.06 E-value: 2.05e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 706 LEEKEEEMKRLVAKIRHAESEESVLAERLQVAESKAQSHNKETAALKDEIRELTGKLEFLRDRAVsfEKQARMLEQEKNH 785
Cdd:COG1579 12 LQELDSELDRLEHRLKELPAELAELEDELAALEARLEAAKTELEDLEKEIKRLELEIEEVEARIK--KYEEQLGNVRNNK 89
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 786 LQEKFLSECkkyDEAEERYKAAEREAKRATELSDVARTEAVTAQKEKDEAQRlsmEKLAVIERIQRQVDRLEQEKVNLLD 865
Cdd:COG1579 90 EYEALQKEI---ESLKRRISDLEDEILELMERIEELEEELAELEAELAELEA---ELEEKKAELDEELAELEAELEELEA 163
|
....*
gi 1002243137 866 EVQKM 870
Cdd:COG1579 164 EREEL 168
|
|
| COG4913 |
COG4913 |
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown]; |
795-940 |
2.25e-03 |
|
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown];
Pssm-ID: 443941 [Multi-domain] Cd Length: 1089 Bit Score: 42.21 E-value: 2.25e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 795 KKYDEAEERYKAAEREAKRATELsdVARTEAVTAQKEKDEAQRLSMEKLAViERIQRQVDRLEQEKVNLLDEVQKmhkse 874
Cdd:COG4913 235 DDLERAHEALEDAREQIELLEPI--RELAERYAAARERLAELEYLRAALRL-WFAQRRLELLEAELEELRAELAR----- 306
|
90 100 110 120 130 140
....*....|....*....|....*....|....*....|....*....|....*....|....*.
gi 1002243137 875 tdALSKVALLESRVAEREKEIEELMIQSNEQRSSTVHVLESLLSTERAARAEANKRAEALSLQLQS 940
Cdd:COG4913 307 --LEAELERLEARLDALREELDELEAQIRGNGGDRLEQLEREIERLERELEERERRRARLEALLAA 370
|
|
| DR0291 |
COG1579 |
Predicted nucleic acid-binding protein DR0291, contains C4-type Zn-ribbon domain [General ... |
795-956 |
2.50e-03 |
|
Predicted nucleic acid-binding protein DR0291, contains C4-type Zn-ribbon domain [General function prediction only];
Pssm-ID: 441187 [Multi-domain] Cd Length: 236 Bit Score: 40.68 E-value: 2.50e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 795 KKYDEAEERYKAAEREAKRATELSDVARTEAVTAQKEKDEAQRLSMEKLAVIERIQRQVDRLEQEkvnlLDEVQKMHksE 874
Cdd:COG1579 17 SELDRLEHRLKELPAELAELEDELAALEARLEAAKTELEDLEKEIKRLELEIEEVEARIKKYEEQ----LGNVRNNK--E 90
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 875 TDALSK-VALLESRVAEREKEIEELMIQSNEqrsstvhvLESLLSTERAARAEANKRAEALSLQLQSTQSKLDVLHQELT 953
Cdd:COG1579 91 YEALQKeIESLKRRISDLEDEILELMERIEE--------LEEELAELEAELAELEAELEEKKAELDEELAELEAELEELE 162
|
...
gi 1002243137 954 SVR 956
Cdd:COG1579 163 AER 165
|
|
| COG4372 |
COG4372 |
Uncharacterized protein, contains DUF3084 domain [Function unknown]; |
749-937 |
2.81e-03 |
|
Uncharacterized protein, contains DUF3084 domain [Function unknown];
Pssm-ID: 443500 [Multi-domain] Cd Length: 370 Bit Score: 41.43 E-value: 2.81e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 749 AALKDEIRELTGKLEFLRDRAVSFEKQARMLEQEKNHLQEKFLSECKKYDEAEERYKAAEREAKRATELSDVARTEAVTA 828
Cdd:COG4372 27 AALSEQLRKALFELDKLQEELEQLREELEQAREELEQLEEELEQARSELEQLEEELEELNEQLQAAQAELAQAQEELESL 106
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 829 QKEKDEAQrlsmeklAVIERIQRQVDRLEQEKVNLLDEVQKMHKSETDALSKVALLESRVAEREKEIEELmiQSNEQRSS 908
Cdd:COG4372 107 QEEAEELQ-------EELEELQKERQDLEQQRKQLEAQIAELQSEIAEREEELKELEEQLESLQEELAAL--EQELQALS 177
|
170 180
....*....|....*....|....*....
gi 1002243137 909 TVHVLESLLSTERAARAEANKRAEALSLQ 937
Cdd:COG4372 178 EAEAEQALDELLKEANRNAEKEEELAEAE 206
|
|
| Myosin_tail_1 |
pfam01576 |
Myosin tail; The myosin molecule is a multi-subunit complex made up of two heavy chains and ... |
536-969 |
3.01e-03 |
|
Myosin tail; The myosin molecule is a multi-subunit complex made up of two heavy chains and four light chains it is a fundamental contractile protein found in all eukaryote cell types. This family consists of the coiled-coil myosin heavy chain tail region. The coiled-coil is composed of the tail from two molecules of myosin. These can then assemble into the macromolecular thick filament. The coiled-coil region provides the structural backbone the thick filament.
Pssm-ID: 460256 [Multi-domain] Cd Length: 1081 Bit Score: 41.70 E-value: 3.01e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 536 EDQLELLKRQLEANEAHKSEYLKRYEAAISEKQRVSEDHSAHlANLRTKCSTLDERCLSLSKELDLVRHECTDWRVKYEQ 615
Cdd:pfam01576 11 EEELQKVKERQQKAESELKELEKKHQQLCEEKNALQEQLQAE-TELCAEAEEMRARLAARKQELEEILHELESRLEEEEE 89
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 616 YVTQQKAEQDGFISQLATLESRYSSAEGKlgaareqaaaaqdeatewRDKYE----TAAAQAKAALERLASVQEQINKIA 691
Cdd:pfam01576 90 RSQQLQNEKKKMQQHIQDLEEQLDEEEAA------------------RQKLQlekvTTEAKIKKLEEDILLLEDQNSKLS 151
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 692 HER---ESGIrAEFASHLEEKEEEMKRLvAKIRHA-ESEESVLAERLQVAESKAQSHNK-------ETAALKDEIRELTG 760
Cdd:pfam01576 152 KERkllEERI-SEFTSNLAEEEEKAKSL-SKLKNKhEAMISDLEERLKKEEKGRQELEKakrklegESTDLQEQIAELQA 229
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 761 KLEFLRDRAVSFE---------------------KQARMLEQEKNHLQEKFLSECKKYDEAEERYK-------------- 805
Cdd:pfam01576 230 QIAELRAQLAKKEeelqaalarleeetaqknnalKKIRELEAQISELQEDLESERAARNKAEKQRRdlgeelealktele 309
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 806 ------AAERE--AKRATELSDVARTEAVTAQKEKDEAQRLSMEKLAVIERIQRQVDRLEQEKVNLLDEVQKMHKSETDA 877
Cdd:pfam01576 310 dtldttAAQQElrSKREQEVTELKKALEEETRSHEAQLQEMRQKHTQALEELTEQLEQAKRNKANLEKAKQALESENAEL 389
|
410 420 430 440 450 460 470 480
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 878 LSKVALLESRVAEREKEIEELMIQSNEqrsstvhvLESLLSTERAARAEANKRAEALSLQLQSTQSKLDVLHQELTSVRL 957
Cdd:pfam01576 390 QAELRTLQQAKQDSEHKRKKLEGQLQE--------LQARLSESERQRAELAEKLSKLQSELESVSSLLNEAEGKNIKLSK 461
|
490
....*....|..
gi 1002243137 958 VETALDSKLRTT 969
Cdd:pfam01576 462 DVSSLESQLQDT 473
|
|
| COG4913 |
COG4913 |
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown]; |
535-971 |
3.05e-03 |
|
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown];
Pssm-ID: 443941 [Multi-domain] Cd Length: 1089 Bit Score: 41.82 E-value: 3.05e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 535 NEDQLELLKRQLEANEAHkseyLKRYEAAISEKQRVSEDHSAHLANLRTKCSTLD-ERCLSLSKELDLVRHECTDWRVKY 613
Cdd:COG4913 286 AQRRLELLEAELEELRAE----LARLEAELERLEARLDALREELDELEAQIRGNGgDRLEQLEREIERLERELEERERRR 361
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 614 EQYVTQQKAEQDGFISQLATLESRYSSAEGKLGAAREQAAAAQDEATEWRDKYETAAAQAKAALERLASVQEQINKIAHE 693
Cdd:COG4913 362 ARLEALLAALGLPLPASAEEFAALRAEAAALLEALEEELEALEEALAEAEAALRDLRRELRELEAEIASLERRKSNIPAR 441
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 694 RESgIRAEFASHLEEKEEEMKrlvakirhaeseesVLAERLQVAESKAQ------------------SHNKETAALK--D 753
Cdd:COG4913 442 LLA-LRDALAEALGLDEAELP--------------FVGELIEVRPEEERwrgaiervlggfaltllvPPEHYAAALRwvN 506
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 754 EIReLTGKLEFlrDRAVSFEKQARMLEQEKNHLQEKFLSECKKY-DEAEERYKAAEREAK--RATELSDVARteAVTAQ- 829
Cdd:COG4913 507 RLH-LRGRLVY--ERVRTGLPDPERPRLDPDSLAGKLDFKPHPFrAWLEAELGRRFDYVCvdSPEELRRHPR--AITRAg 581
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 830 --------KEKDEAQRL---------SMEKlavIERIQRQVDRLEQEKVNLLDEVQKMhKSETDALSKVALLESRVAER- 891
Cdd:COG4913 582 qvkgngtrHEKDDRRRIrsryvlgfdNRAK---LAALEAELAELEEELAEAEERLEAL-EAELDALQERREALQRLAEYs 657
|
410 420 430 440 450 460 470 480
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 892 ---------EKEIEEL--MIQSNEQRSSTVHVLESLLSTERAARAEANKRAEALSLQLQSTQSKLDVLHQELTSVRLVET 960
Cdd:COG4913 658 wdeidvasaEREIAELeaELERLDASSDDLAALEEQLEELEAELEELEEELDELKGEIGRLEKELEQAEEELDELQDRLE 737
|
490
....*....|.
gi 1002243137 961 ALDSKLRTTTH 971
Cdd:COG4913 738 AAEDLARLELR 748
|
|
| Myosin_tail_1 |
pfam01576 |
Myosin tail; The myosin molecule is a multi-subunit complex made up of two heavy chains and ... |
747-997 |
3.07e-03 |
|
Myosin tail; The myosin molecule is a multi-subunit complex made up of two heavy chains and four light chains it is a fundamental contractile protein found in all eukaryote cell types. This family consists of the coiled-coil myosin heavy chain tail region. The coiled-coil is composed of the tail from two molecules of myosin. These can then assemble into the macromolecular thick filament. The coiled-coil region provides the structural backbone the thick filament.
Pssm-ID: 460256 [Multi-domain] Cd Length: 1081 Bit Score: 41.70 E-value: 3.07e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 747 ETAALKDEIRELTGKLEFLRDRAVSFEKQARMLEQEKNHLQEKFLSECKKYDEAEErykAAEREAKRATELSDVARTEAV 826
Cdd:pfam01576 6 EMQAKEEELQKVKERQQKAESELKELEKKHQQLCEEKNALQEQLQAETELCAEAEE---MRARLAARKQELEEILHELES 82
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 827 TAQKEKDEAQRLSMEKlaviERIQRQVDRLEQ--------------EKVNLLDEVQKMH------KSETDALSKVA-LLE 885
Cdd:pfam01576 83 RLEEEEERSQQLQNEK----KKMQQHIQDLEEqldeeeaarqklqlEKVTTEAKIKKLEedilllEDQNSKLSKERkLLE 158
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 886 SRVAE------REKEIEELMIQSNEQRSSTVHVLESLLSTERAARAEANKRAEALSLQLQSTQSKLDVLHQELTSVRL-- 957
Cdd:pfam01576 159 ERISEftsnlaEEEEKAKSLSKLKNKHEAMISDLEERLKKEEKGRQELEKAKRKLEGESTDLQEQIAELQAQIAELRAql 238
|
250 260 270 280 290
....*....|....*....|....*....|....*....|....*....|.
gi 1002243137 958 ------VETAL----DSKLRTTTHGKRLRENEVGMESVQ-DMDIDRPERSR 997
Cdd:pfam01576 239 akkeeeLQAALarleEETAQKNNALKKIRELEAQISELQeDLESERAARNK 289
|
|
| PRK02224 |
PRK02224 |
DNA double-strand break repair Rad50 ATPase; |
740-979 |
3.10e-03 |
|
DNA double-strand break repair Rad50 ATPase;
Pssm-ID: 179385 [Multi-domain] Cd Length: 880 Bit Score: 41.56 E-value: 3.10e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 740 KAQSHNKETAALKDEIRELTGKLEFLRDRAVSFEKQARMLEQEKNHLQEKFLSECKKYDEAEERYKAAE--REAKRATEL 817
Cdd:PRK02224 193 KAQIEEKEEKDLHERLNGLESELAELDEEIERYEEQREQARETRDEADEVLEEHEERREELETLEAEIEdlRETIAETER 272
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 818 SDVARTEAVTAQKEKDEAQRLSMEKL--------AVIERIQRQVDRLEQEKVNLLDEVQ------KMHKSETDALSKVAL 883
Cdd:PRK02224 273 EREELAEEVRDLRERLEELEEERDDLlaeaglddADAEAVEARREELEDRDEELRDRLEecrvaaQAHNEEAESLREDAD 352
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 884 -LESRVAEREKEIEEL--MIQSN----EQRSSTVHVLESLLSTERAARAEANKRAEALSLQLQSTQSKLDVLHQELTSVR 956
Cdd:PRK02224 353 dLEERAEELREEAAELesELEEAreavEDRREEIEELEEEIEELRERFGDAPVDLGNAEDFLEELREERDELREREAELE 432
|
250 260
....*....|....*....|...
gi 1002243137 957 lvetaldSKLRTTThgKRLRENE 979
Cdd:PRK02224 433 -------ATLRTAR--ERVEEAE 446
|
|
| MukB |
COG3096 |
Chromosome condensin MukBEF, ATPase and DNA-binding subunit MukB [Cell cycle control, cell ... |
678-938 |
3.71e-03 |
|
Chromosome condensin MukBEF, ATPase and DNA-binding subunit MukB [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 442330 [Multi-domain] Cd Length: 1470 Bit Score: 41.48 E-value: 3.71e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 678 ERLASVQE---QINKIAHERESgiraefashLEEKEEemkrlvakiRHAESEESV--LAERLQVAESKAQSHNKETAALK 752
Cdd:COG3096 334 DHLNLVQTalrQQEKIERYQED---------LEELTE---------RLEEQEEVVeeAAEQLAEAEARLEAAEEEVDSLK 395
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 753 DEIRELTGKLEFLRDRAVSFEKQARMLEQEKNHLQEKFLSEckkyDEAEERYKAAEREAKRATE----------LSDVAR 822
Cdd:COG3096 396 SQLADYQQALDVQQTRAIQYQQAVQALEKARALCGLPDLTP----ENAEDYLAAFRAKEQQATEevleleqklsVADAAR 471
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 823 TE---------AVTAQKEKDEAQRLSMEKL-------AVIER---IQRQVDRLEQ------EKVNLLDEVQKMHKSETDA 877
Cdd:COG3096 472 RQfekayelvcKIAGEVERSQAWQTARELLrryrsqqALAQRlqqLRAQLAELEQrlrqqqNAERLLEEFCQRIGQQLDA 551
|
250 260 270 280 290 300
....*....|....*....|....*....|....*....|....*....|....*....|....*..
gi 1002243137 878 LSKVALLESRVAEREKEIEELMIQSNEQRSSTVHVLESLLS--TERAARA----EANKRAEALSLQL 938
Cdd:COG3096 552 AEELEELLAELEAQLEELEEQAAEAVEQRSELRQQLEQLRAriKELAARApawlAAQDALERLREQS 618
|
|
| Cast |
pfam10174 |
RIM-binding protein of the cytomatrix active zone; This is a family of proteins that form part ... |
727-980 |
5.65e-03 |
|
RIM-binding protein of the cytomatrix active zone; This is a family of proteins that form part of the CAZ (cytomatrix at the active zone) complex which is involved in determining the site of synaptic vesicle fusion. The C-terminus is a PDZ-binding motif that binds directly to RIM (a small G protein Rab-3A effector). The family also contains four coiled-coil domains.
Pssm-ID: 431111 [Multi-domain] Cd Length: 766 Bit Score: 40.58 E-value: 5.65e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 727 ESVLAERLQVAESKAQSHNKETAALKDEIRELTGKLEFLRDRAVSFekQARMLEQEK--NHLQEKFLSECKKYDEAEERY 804
Cdd:pfam10174 442 EEALSEKERIIERLKEQREREDRERLEELESLKKENKDLKEKVSAL--QPELTEKESslIDLKEHASSLASSGLKKDSKL 519
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 805 KAAEREAKRATELSDVARTEAVTAQkEKDEAQRLSMEKLAVIERIQRQVDRLEQEKVN-------LLDEVQKMHKSETDA 877
Cdd:pfam10174 520 KSLEIAVEQKKEECSKLENQLKKAH-NAEEAVRTNPEINDRIRLLEQEVARYKEESGKaqaeverLLGILREVENEKNDK 598
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 878 LSKVALLESRVAEREKE--IEELMIQSNEQ---RSSTVHVLESLLSTERAARAEANKRAEALSLQLQSTQSKLDVLHQEL 952
Cdd:pfam10174 599 DKKIAELESLTLRQMKEqnKKVANIKHGQQemkKKGAQLLEEARRREDNLADNSQQLQLEELMGALEKTRQELDATKARL 678
|
250 260
....*....|....*....|....*...
gi 1002243137 953 TSVRLVETALDSKLRTTTHGKRLRENEV 980
Cdd:pfam10174 679 SSTQQSLAEKDGHLTNLRAERRKQLEEI 706
|
|
| EnvC |
COG4942 |
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, ... |
528-771 |
8.70e-03 |
|
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 443969 [Multi-domain] Cd Length: 377 Bit Score: 39.75 E-value: 8.70e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 528 FALKYRSNEDQLELLKRQLEANEAHKSEYLKRYEAAISEKQRVSEDhsahLANLRTKCSTLDERCLSLSKELDLVRHECT 607
Cdd:COG4942 11 LALAAAAQADAAAEAEAELEQLQQEIAELEKELAALKKEEKALLKQ----LAALERRIAALARRIRALEQELAALEAELA 86
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 608 DWRVKYEQYVTQQKAEQDGFISQLATLE--SRYSSAEGKLGAAREQAAAAQDEAtewrdkYETAAAQAKAALERLASVQE 685
Cdd:COG4942 87 ELEKEIAELRAELEAQKEELAELLRALYrlGRQPPLALLLSPEDFLDAVRRLQY------LKYLAPARREQAEELRADLA 160
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 686 QINKIAHERESgIRAEFASHLEEKEEEMKRLVAKIRHAESEESVLAERLQVAESKAQSHNKETAALKDEIRELTGKLEFL 765
Cdd:COG4942 161 ELAALRAELEA-ERAELEALLAELEEERAALEALKAERQKLLARLEKELAELAAELAELQQEAEELEALIARLEAEAAAA 239
|
....*.
gi 1002243137 766 RDRAVS 771
Cdd:COG4942 240 AERTPA 245
|
|
| sbcc |
TIGR00618 |
exonuclease SbcC; All proteins in this family for which functions are known are part of an ... |
520-958 |
9.11e-03 |
|
exonuclease SbcC; All proteins in this family for which functions are known are part of an exonuclease complex with sbcD homologs. This complex is involved in the initiation of recombination to regulate the levels of palindromic sequences in DNA. This family is based on the phylogenomic analysis of JA Eisen (1999, Ph.D. Thesis, Stanford University). [DNA metabolism, DNA replication, recombination, and repair]
Pssm-ID: 129705 [Multi-domain] Cd Length: 1042 Bit Score: 40.34 E-value: 9.11e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 520 EAESERTSFALKYRSN-EDQLELLKRQLEANEAHKSEYLKRYEA-------AISEKQRVSEDHSAHLANLRTkcsTLDER 591
Cdd:TIGR00618 318 SKMRSRAKLLMKRAAHvKQQSSIEEQRRLLQTLHSQEIHIRDAHevatsirEISCQQHTLTQHIHTLQQQKT---TLTQK 394
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 592 CLSLSKELDLVRHEC----------TDWRVKYEQYVTQQKAEQDGFISQLATLESRYSSAEGKLGAAREQAAAAQDEATE 661
Cdd:TIGR00618 395 LQSLCKELDILQREQatidtrtsafRDLQGQLAHAKKQQELQQRYAELCAAAITCTAQCEKLEKIHLQESAQSLKEREQQ 474
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 662 WRDKYETAAAQAKAALERLASVQEQ-----------INKIAHERESGIRAEFASHLEEKEEEMKRLVAKIRHAESEESVL 730
Cdd:TIGR00618 475 LQTKEQIHLQETRKKAVVLARLLELqeepcplcgscIHPNPARQDIDNPGPLTRRMQRGEQTYAQLETSEEDVYHQLTSE 554
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 731 AERLQVAESKAQSHNKETAAL-------KDEIRELTGKLEFLRDRAVSFEKQARMLEQEKNHLQEKFLSECKKYDEAEER 803
Cdd:TIGR00618 555 RKQRASLKEQMQEIQQSFSILtqcdnrsKEDIPNLQNITVRLQDLTEKLSEAEDMLACEQHALLRKLQPEQDLQDVRLHL 634
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1002243137 804 YKAAEREAKRATELsdvARTEAVTAQKEKDEAQRlsmeklavieRIQRQVDRLEQEKVNLLDEVQKMHKSETDALSKVAL 883
Cdd:TIGR00618 635 QQCSQELALKLTAL---HALQLTLTQERVREHAL----------SIRVLPKELLASRQLALQKMQSEKEQLTYWKEMLAQ 701
|
410 420 430 440 450 460 470
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*
gi 1002243137 884 LESRVAEREKEIEELMIQSNEQrSSTVHVLESLLSTERAARAEANKRAEAlslqLQSTQSKLDVLHQELTSVRLV 958
Cdd:TIGR00618 702 CQTLLRELETHIEEYDREFNEI-ENASSSLGSDLAAREDALNQSLKELMH----QARTVLKARTEAHFNNNEEVT 771
|
|
| |