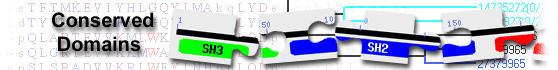


tight junction-associated protein 1 isoform X1 [Homo sapiens]
Protein Classification

List of domain hits
| Name | Accession | Description | Interval | E-value | ||||||
| Pilt super family | cl21271 | Protein incorporated later into Tight Junctions; Pilt is a family of eukaryotic tight ... |
284-556 | 2.27e-61 | ||||||
Protein incorporated later into Tight Junctions; Pilt is a family of eukaryotic tight junction-proteins that binds to guanylate-kinase. Pilt is a component of TJs (Tight junctions) rather than AJs (Adhesin junctions). The protein is incorporated into TJs after TJ strands are formed, thereby suggesting the name Pilt for 'protein incorporated later into TJs'. Pilt binds to the guanylate-kinase region of hDlg otherwise known as Disk large homolog. The actual alignment was detected with superfamily member pfam15453: Pssm-ID: 464725 Cd Length: 362 Bit Score: 206.36 E-value: 2.27e-61
|
||||||||||
| YhaN super family | cl34808 | Uncharacterized conserved protein YhaN, contains AAA domain [Function unknown]; |
6-163 | 1.19e-05 | ||||||
Uncharacterized conserved protein YhaN, contains AAA domain [Function unknown]; The actual alignment was detected with superfamily member COG4717: Pssm-ID: 443752 [Multi-domain] Cd Length: 641 Bit Score: 48.23 E-value: 1.19e-05
|
||||||||||
| Name | Accession | Description | Interval | E-value | ||||||
| Pilt | pfam15453 | Protein incorporated later into Tight Junctions; Pilt is a family of eukaryotic tight ... |
284-556 | 2.27e-61 | ||||||
Protein incorporated later into Tight Junctions; Pilt is a family of eukaryotic tight junction-proteins that binds to guanylate-kinase. Pilt is a component of TJs (Tight junctions) rather than AJs (Adhesin junctions). The protein is incorporated into TJs after TJ strands are formed, thereby suggesting the name Pilt for 'protein incorporated later into TJs'. Pilt binds to the guanylate-kinase region of hDlg otherwise known as Disk large homolog. Pssm-ID: 464725 Cd Length: 362 Bit Score: 206.36 E-value: 2.27e-61
|
||||||||||
| YhaN | COG4717 | Uncharacterized conserved protein YhaN, contains AAA domain [Function unknown]; |
6-163 | 1.19e-05 | ||||||
Uncharacterized conserved protein YhaN, contains AAA domain [Function unknown]; Pssm-ID: 443752 [Multi-domain] Cd Length: 641 Bit Score: 48.23 E-value: 1.19e-05
|
||||||||||
| PRK03918 | PRK03918 | DNA double-strand break repair ATPase Rad50; |
17-168 | 1.06e-04 | ||||||
DNA double-strand break repair ATPase Rad50; Pssm-ID: 235175 [Multi-domain] Cd Length: 880 Bit Score: 45.05 E-value: 1.06e-04
|
||||||||||
| SMC_prok_B | TIGR02168 | chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
50-169 | 2.88e-04 | ||||||
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins] Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 43.89 E-value: 2.88e-04
|
||||||||||
| GAS | pfam13851 | Growth-arrest specific micro-tubule binding; This family is the highly conserved central ... |
34-161 | 2.96e-03 | ||||||
Growth-arrest specific micro-tubule binding; This family is the highly conserved central region of a number of metazoan proteins referred to as growth-arrest proteins. In mouse, Gas8 is predominantly a testicular protein, whose expression is developmentally regulated during puberty and spermatogenesis. In humans, it is absent in infertile males who lack the ability to generate gametes. The localization of Gas8 in the motility apparatus of post-meiotic gametocytes and mature spermatozoa, together with the detection of Gas8 also in cilia at the apical surfaces of epithelial cells lining the pulmonary bronchi and Fallopian tubes suggests that the Gas8 protein may have a role in the functioning of motile cellular appendages. Gas8 is a microtubule-binding protein localized to regions of dynein regulation in mammalian cells. Pssm-ID: 464001 [Multi-domain] Cd Length: 200 Bit Score: 39.12 E-value: 2.96e-03
|
||||||||||
| Name | Accession | Description | Interval | E-value | ||||||
| Pilt | pfam15453 | Protein incorporated later into Tight Junctions; Pilt is a family of eukaryotic tight ... |
284-556 | 2.27e-61 | ||||||
Protein incorporated later into Tight Junctions; Pilt is a family of eukaryotic tight junction-proteins that binds to guanylate-kinase. Pilt is a component of TJs (Tight junctions) rather than AJs (Adhesin junctions). The protein is incorporated into TJs after TJ strands are formed, thereby suggesting the name Pilt for 'protein incorporated later into TJs'. Pilt binds to the guanylate-kinase region of hDlg otherwise known as Disk large homolog. Pssm-ID: 464725 Cd Length: 362 Bit Score: 206.36 E-value: 2.27e-61
|
||||||||||
| YhaN | COG4717 | Uncharacterized conserved protein YhaN, contains AAA domain [Function unknown]; |
6-163 | 1.19e-05 | ||||||
Uncharacterized conserved protein YhaN, contains AAA domain [Function unknown]; Pssm-ID: 443752 [Multi-domain] Cd Length: 641 Bit Score: 48.23 E-value: 1.19e-05
|
||||||||||
| PRK03918 | PRK03918 | DNA double-strand break repair ATPase Rad50; |
17-168 | 1.06e-04 | ||||||
DNA double-strand break repair ATPase Rad50; Pssm-ID: 235175 [Multi-domain] Cd Length: 880 Bit Score: 45.05 E-value: 1.06e-04
|
||||||||||
| SMC_prok_B | TIGR02168 | chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
50-169 | 2.88e-04 | ||||||
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins] Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 43.89 E-value: 2.88e-04
|
||||||||||
| PRK03918 | PRK03918 | DNA double-strand break repair ATPase Rad50; |
17-168 | 3.33e-04 | ||||||
DNA double-strand break repair ATPase Rad50; Pssm-ID: 235175 [Multi-domain] Cd Length: 880 Bit Score: 43.51 E-value: 3.33e-04
|
||||||||||
| PRK02224 | PRK02224 | DNA double-strand break repair Rad50 ATPase; |
17-163 | 7.25e-04 | ||||||
DNA double-strand break repair Rad50 ATPase; Pssm-ID: 179385 [Multi-domain] Cd Length: 880 Bit Score: 42.33 E-value: 7.25e-04
|
||||||||||
| COG2433 | COG2433 | Possible nuclease of RNase H fold, RuvC/YqgF family [General function prediction only]; |
40-116 | 1.08e-03 | ||||||
Possible nuclease of RNase H fold, RuvC/YqgF family [General function prediction only]; Pssm-ID: 441980 [Multi-domain] Cd Length: 644 Bit Score: 41.77 E-value: 1.08e-03
|
||||||||||
| rad50 | TIGR00606 | rad50; All proteins in this family for which functions are known are involvedin recombination, ... |
17-204 | 1.17e-03 | ||||||
rad50; All proteins in this family for which functions are known are involvedin recombination, recombinational repair, and/or non-homologous end joining.They are components of an exonuclease complex with MRE11 homologs. This family is distantly related to the SbcC family of bacterial proteins.This family is based on the phylogenomic analysis of JA Eisen (1999, Ph.D. Thesis, Stanford University). Pssm-ID: 129694 [Multi-domain] Cd Length: 1311 Bit Score: 41.96 E-value: 1.17e-03
|
||||||||||
| PRK03918 | PRK03918 | DNA double-strand break repair ATPase Rad50; |
15-169 | 1.27e-03 | ||||||
DNA double-strand break repair ATPase Rad50; Pssm-ID: 235175 [Multi-domain] Cd Length: 880 Bit Score: 41.59 E-value: 1.27e-03
|
||||||||||
| Smc | COG1196 | Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; ... |
41-163 | 1.39e-03 | ||||||
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; Pssm-ID: 440809 [Multi-domain] Cd Length: 983 Bit Score: 41.46 E-value: 1.39e-03
|
||||||||||
| SMC_prok_A | TIGR02169 | chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ... |
11-163 | 1.95e-03 | ||||||
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins] Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 41.21 E-value: 1.95e-03
|
||||||||||
| COG4372 | COG4372 | Uncharacterized protein, contains DUF3084 domain [Function unknown]; |
40-163 | 2.10e-03 | ||||||
Uncharacterized protein, contains DUF3084 domain [Function unknown]; Pssm-ID: 443500 [Multi-domain] Cd Length: 370 Bit Score: 40.66 E-value: 2.10e-03
|
||||||||||
| SMC_prok_B | TIGR02168 | chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
22-175 | 2.54e-03 | ||||||
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins] Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 40.81 E-value: 2.54e-03
|
||||||||||
| GAS | pfam13851 | Growth-arrest specific micro-tubule binding; This family is the highly conserved central ... |
34-161 | 2.96e-03 | ||||||
Growth-arrest specific micro-tubule binding; This family is the highly conserved central region of a number of metazoan proteins referred to as growth-arrest proteins. In mouse, Gas8 is predominantly a testicular protein, whose expression is developmentally regulated during puberty and spermatogenesis. In humans, it is absent in infertile males who lack the ability to generate gametes. The localization of Gas8 in the motility apparatus of post-meiotic gametocytes and mature spermatozoa, together with the detection of Gas8 also in cilia at the apical surfaces of epithelial cells lining the pulmonary bronchi and Fallopian tubes suggests that the Gas8 protein may have a role in the functioning of motile cellular appendages. Gas8 is a microtubule-binding protein localized to regions of dynein regulation in mammalian cells. Pssm-ID: 464001 [Multi-domain] Cd Length: 200 Bit Score: 39.12 E-value: 2.96e-03
|
||||||||||
| Mplasa_alph_rch | TIGR04523 | helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of ... |
43-167 | 5.50e-03 | ||||||
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of Mycoplasma species. Members average 750 amino acids in length, including signal peptide. Sequences are predicted (Jpred 3) to be almost entirely alpha-helical. These sequences show strong periodicity (consistent with long alpha helical structures) and low complexity rich in D,E,N,Q, and K. Genes encoding these proteins are often found in tandem. The function is unknown. Pssm-ID: 275316 [Multi-domain] Cd Length: 745 Bit Score: 39.62 E-value: 5.50e-03
|
||||||||||
| SMC_prok_A | TIGR02169 | chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ... |
11-166 | 6.03e-03 | ||||||
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins] Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 39.67 E-value: 6.03e-03
|
||||||||||
| HAP1_N | pfam04849 | HAP1 N-terminal conserved region; This family represents an N-terminal conserved region found ... |
40-121 | 6.65e-03 | ||||||
HAP1 N-terminal conserved region; This family represents an N-terminal conserved region found in several huntingtin-associated protein 1 (HAP1) homologs. HAP1 binds to huntingtin in a polyglutamine repeat-length-dependent manner. However, its possible role in the pathogenesis of Huntington's disease is unclear. This family also includes a similar N-terminal conserved region from hypothetical protein products of ALS2CR3 genes found in the human juvenile amyotrophic lateral sclerosis critical region 2q33-2q34. Pssm-ID: 461455 [Multi-domain] Cd Length: 309 Bit Score: 38.85 E-value: 6.65e-03
|
||||||||||
| Smc | COG1196 | Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; ... |
17-169 | 9.69e-03 | ||||||
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; Pssm-ID: 440809 [Multi-domain] Cd Length: 983 Bit Score: 38.76 E-value: 9.69e-03
|
||||||||||
| Blast search parameters | ||||
|
