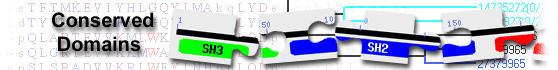tuberin such as human tuberin, encoded by TSC2, that with hamartin (TSC1), form a tumor suppressor heterodimer that inhibits the mammalian target of rapamycin (mTOR) nutrient signaling input; contains an N-terminal DUF3384 domain and a C-terminal RapGAP homology domain responsible for inactivation of Rheb
Tuberin; Tuberous sclerosis complex (TSC) is an autosomal dominant disorder and is ...
552-902
7.45e-166
Tuberin; Tuberous sclerosis complex (TSC) is an autosomal dominant disorder and is characterized by the presence of hamartomas in many organs, such as brain, skin, heart, lung, and kidney. It is caused by mutation either TSC1 or TSC2 tumour suppressor gene. The TSC2 gene codes for tuberin and interacts with hamartin pfam04388, containing two coiled-coil regions, which have been shown to mediate binding to tuberin. These two proteins function within the same pathway(s) regulating cell cycle, cell growth, adhesion, and vesicular trafficking.
:
Pssm-ID: 460965 Cd Length: 349 Bit Score: 506.89 E-value: 7.45e-166
Domain of unknown function (DUF3384); This domain is functionally uncharacterized. This domain ...
54-419
7.18e-89
Domain of unknown function (DUF3384); This domain is functionally uncharacterized. This domain is found in eukaryotes. This presumed domain is typically between 422 to 486 amino acids in length. This domain is found associated with pfam02145.
:
Pssm-ID: 463376 Cd Length: 407 Bit Score: 296.10 E-value: 7.18e-89
Tuberin; Tuberous sclerosis complex (TSC) is an autosomal dominant disorder and is ...
552-902
7.45e-166
Tuberin; Tuberous sclerosis complex (TSC) is an autosomal dominant disorder and is characterized by the presence of hamartomas in many organs, such as brain, skin, heart, lung, and kidney. It is caused by mutation either TSC1 or TSC2 tumour suppressor gene. The TSC2 gene codes for tuberin and interacts with hamartin pfam04388, containing two coiled-coil regions, which have been shown to mediate binding to tuberin. These two proteins function within the same pathway(s) regulating cell cycle, cell growth, adhesion, and vesicular trafficking.
Pssm-ID: 460965 Cd Length: 349 Bit Score: 506.89 E-value: 7.45e-166
Domain of unknown function (DUF3384); This domain is functionally uncharacterized. This domain ...
54-419
7.18e-89
Domain of unknown function (DUF3384); This domain is functionally uncharacterized. This domain is found in eukaryotes. This presumed domain is typically between 422 to 486 amino acids in length. This domain is found associated with pfam02145.
Pssm-ID: 463376 Cd Length: 407 Bit Score: 296.10 E-value: 7.18e-89
Tuberin; Tuberous sclerosis complex (TSC) is an autosomal dominant disorder and is ...
552-902
7.45e-166
Tuberin; Tuberous sclerosis complex (TSC) is an autosomal dominant disorder and is characterized by the presence of hamartomas in many organs, such as brain, skin, heart, lung, and kidney. It is caused by mutation either TSC1 or TSC2 tumour suppressor gene. The TSC2 gene codes for tuberin and interacts with hamartin pfam04388, containing two coiled-coil regions, which have been shown to mediate binding to tuberin. These two proteins function within the same pathway(s) regulating cell cycle, cell growth, adhesion, and vesicular trafficking.
Pssm-ID: 460965 Cd Length: 349 Bit Score: 506.89 E-value: 7.45e-166
Domain of unknown function (DUF3384); This domain is functionally uncharacterized. This domain ...
54-419
7.18e-89
Domain of unknown function (DUF3384); This domain is functionally uncharacterized. This domain is found in eukaryotes. This presumed domain is typically between 422 to 486 amino acids in length. This domain is found associated with pfam02145.
Pssm-ID: 463376 Cd Length: 407 Bit Score: 296.10 E-value: 7.18e-89
Database: CDSEARCH/cdd Low complexity filter: no Composition Based Adjustment: yes E-value threshold: 0.01
References:
Wang J et al. (2023), "The conserved domain database in 2023", Nucleic Acids Res.51(D)384-8.
Lu S et al. (2020), "The conserved domain database in 2020", Nucleic Acids Res.48(D)265-8.
Marchler-Bauer A et al. (2017), "CDD/SPARCLE: functional classification of proteins via subfamily domain architectures.", Nucleic Acids Res.45(D)200-3.
of the residues that compose this conserved feature have been mapped to the query sequence.
Click on the triangle to view details about the feature, including a multiple sequence alignment
of your query sequence and the protein sequences used to curate the domain model,
where hash marks (#) above the aligned sequences show the location of the conserved feature residues.
The thumbnail image, if present, provides an approximate view of the feature's location in 3 dimensions.
Click on the triangle for interactive 3D structure viewing options.
Functional characterization of the conserved domain architecture found on the query.
Click here to see more details.
This image shows a graphical summary of conserved domains identified on the query sequence.
The Show Concise/Full Display button at the top of the page can be used to select the desired level of detail: only top scoring hits
(labeled illustration) or all hits
(labeled illustration).
Domains are color coded according to superfamilies
to which they have been assigned. Hits with scores that pass a domain-specific threshold
(specific hits) are drawn in bright colors.
Others (non-specific hits) and
superfamily placeholders are drawn in pastel colors.
if a domain or superfamily has been annotated with functional sites (conserved features),
they are mapped to the query sequence and indicated through sets of triangles
with the same color and shade of the domain or superfamily that provides the annotation. Mouse over the colored bars or triangles to see descriptions of the domains and features.
click on the bars or triangles to view your query sequence embedded in a multiple sequence alignment of the proteins used to develop the corresponding domain model.
The table lists conserved domains identified on the query sequence. Click on the plus sign (+) on the left to display full descriptions, alignments, and scores.
Click on the domain model's accession number to view the multiple sequence alignment of the proteins used to develop the corresponding domain model.
To view your query sequence embedded in that multiple sequence alignment, click on the colored bars in the Graphical Summary portion of the search results page,
or click on the triangles, if present, that represent functional sites (conserved features)
mapped to the query sequence.
Concise Display shows only the best scoring domain model, in each hit category listed below except non-specific hits, for each region on the query sequence.
(labeled illustration) Standard Display shows only the best scoring domain model from each source, in each hit category listed below for each region on the query sequence.
(labeled illustration) Full Display shows all domain models, in each hit category below, that meet or exceed the RPS-BLAST threshold for statistical significance.
(labeled illustration) Four types of hits can be shown, as available,
for each region on the query sequence:
specific hits meet or exceed a domain-specific e-value threshold
(illustrated example)
and represent a very high confidence that the query sequence belongs to the same protein family as the sequences use to create the domain model
non-specific hits
meet or exceed the RPS-BLAST threshold for statistical significance (default E-value cutoff of 0.01, or an E-value selected by user via the
advanced search options)
the domain superfamily to which the specific and non-specific hits belong
multi-domain models that were computationally detected and are likely to contain multiple single domains
Retrieve proteins that contain one or more of the domains present in the query sequence, using the Conserved Domain Architecture Retrieval Tool
(CDART).
Modify your query to search against a different database and/or use advanced search options