

NCBI Bookshelf. A service of the National Library of Medicine, National Institutes of Health.
Balk E, Adam GP, Kimmel H, et al. Nonsurgical Treatments for Urinary Incontinence in Women: A Systematic Review Update [Internet]. Rockville (MD): Agency for Healthcare Research and Quality (US); 2018 Aug. (Comparative Effectiveness Review, No. 212.)

Nonsurgical Treatments for Urinary Incontinence in Women: A Systematic Review Update [Internet].
Show detailsThe Evidence-based Practice Center conducted the review based on a systematic review of the scientific literature, using established methodologies as outlined in the Agency for Healthcare Research and Quality (AHRQ) Methods Guide for Effectiveness and Comparative Effectiveness Reviews.6 As described below, the contextual question was addressed using a nonsystematic approach. The PROSPERO registration number is CRD42017069903.
Conducting the Systematic Review (Key Questions 1–4)
We included all eligible studies included in the 2012 review. To identify relevant primary research studies published since 2011, we conducted literature searches of studies in MEDLINE®, the Cochrane Central Trials Registry, the Cochrane Database of Systematic Reviews, and Embase® databases. Final searches were conducted on December 4, 2017. We also searched the FDA Web site and ClinicalTrials.gov.
The 2012 AHRQ review identified studies published in English that were entered into electronic databases from 1990 until December 30, 2011. In the 2012 review the grey literature searches were last conducted in May 2010. Based on these search dates, we included new primary studies and existing systematic reviews in electronic databases published between January 2011 to the current search date (December 4, 2017). This time frame provided a 1-year overlap with the search done for the 2012 AHRQ review. Searches of the FDA Web site and ClinicalTrials.gov included studies entered since January 2010. For earlier studies that address the KQs covered by the update, we fully relied on the 2012 AHRQ review, making the assumption that the search for the 2012 AHRQ review was complete and accurate. Furthermore, we included additional eligible studies made known to us by AHRQ, PCORI, peer reviewers, manufacturers (via Supplemental Evidence and Data for Systematic Reviews [SEADS]/Federal Registry Notices), or other stakeholders.
To the extent possible, the current search replicated the search reported by the 2012 AHRQ review. However, we added terms for any eligible interventions that were omitted from the 2012 AHRQ review search strategies. We used the search strategies in Appendix A.
With the exception of studies in the 2012 AHRQ review, studies found from existing systematic reviews were extracted de novo. For studies included in the 2012 AHRQ review, we relied on their extraction and summary data for study level data, including risk of bias assessment.
All citations (abstracts) found by literature searches and other sources were independently screened by at least two researchers. At the start of abstract screening, we implemented a training session, in which all researchers screened the same articles and conflicts were discussed; this process was repeated until the team determined there was adequate consensus. During double-screening, we resolved conflicts by discussion among the team. All screening was done in the open-source, online software Abstrackr (http://abstrackr.cebm.brown.edu/). All potentially relevant studies were rescreened in full text to ensure eligibility.
Eligibility Criteria for the Key Questions
The eligibility criteria for the update are not substantially different from the criteria for the 2012 AHRQ review. The main differences relate to dropping Key Question (KQ) 1 (on diagnosis) from the 2012 AHRQ review, explicitly adding new subpopulations of interest, and making some criteria more explicit (e.g., fleshing out and adding to the list of interventions of interest). The criteria are detailed in Table 2.
Changes from the 2012 AHRQ review include the following:
Population: Based on stakeholder input, we highlighted four specific subpopulations of interest (women athletes and those engaging in high-impact physical activities, older women, women in the military or veterans, and racial and ethnic minorities). Studies that either focused on these subpopulations or provide relevant subgroup data are summarized separately.
In addition, we applied stricter rules about the exclusion criteria, allowing only up to 10 percent of study participants to be among the excluded populations (e.g., men, children, “dry” overactive bladder [without incontinence], institutionalized people); the 2012 AHRQ review allowed up to 25 percent of participants to be men. Studies included in the 2012 AHRQ review that included between 10 and 25 percent men were excluded from the current review. We also excluded other studies included in the 2012 AHRQ review that did not meet either their or our criteria.
Interventions: The list of eligible nonpharmacological interventions is the same as in the 2012 AHRQ review, although we have added some specific interventions to the list that were not explicitly listed a priori in the 2012 AHRQ review (e.g., bladder training). Similarly, the list of pharmacological treatments is more complete than the a priori list in the 2012 AHRQ review; additional drugs known to be in use have been added, including calcium channel blockers, TRPV1 (transient receptor potential cation channel subfamily V member 1) antagonists, additional antidepressant classes, and mirabegron (a beta-3 adeno-receptor agonist). Although not listed a priori in the 2012 AHRQ review, calcium channel blockers and resiniferatoxin (a TRPV1 antagonist) were included in the original review. No studies of selective serotonin or serotonin-norepinephrine reuptake inhibitors (SSRI or SNRI) antidepressants or of mirabegron were included in the AHRQ 2012 review.
Comparators: No changes are made from the 2012 AHRQ review.
Outcomes: All outcomes reported in the 2012 AHRQ review’s eligibility criteria (Appendix D of that document) are included in this update, except for urodynamic testing, which is used in practice only for diagnosis, not for followup outcome assessment. As per the 2012 AHRQ review, we included only categorical urinary incontinence outcomes (e.g., cure, improvement). Noneligible outcomes for the current review that were extracted for the 2012 AHRQ review were omitted from this report. For quality of life outcomes, we included both categorical and continuous (i.e., score or scale) outcomes, although the extraction and summarization of these were handled in a more summary manner than in the 2012 AHRQ review. Adverse events were also included. We searched studies for all patient-centered outcomes identified from the contextual question on how patients define outcome success.
Study Design, Timing, Setting: No substantive changes are made from the 2012 AHRQ review, except that the eligibility criteria were applied more completely (e.g., small single group studies included in the 2012 AHRQ review were omitted).
Table 2
Eligibility criteria.
Data Extraction and Data Management
Each new study was extracted by one methodologist. The extraction was reviewed and confirmed by at least one other experienced methodologist. Disagreements were resolved by discussion among the team, as needed. Studies with UI outcome data were extracted into a customized form in Systematic Review Data Repository (SRDR) online system (https://srdr.ahrq.gov/projects/1153). Results data for categorical UI outcomes were extracted into SRDR in full. Results data for quality of life and adverse events were extracted into customized Google sheets spreadsheets. Upon completion of the review, the spreadsheets were uploaded into the SRDR database, which is accessible to the general public (with capacity to read, download, and comment on data). The basic elements and design of the extraction form are similar to those used for other AHRQ comparative effectiveness reviews. They include elements that address population and baseline characteristics; descriptions of the interventions and comparators analyzed; outcome definitions; effect modifiers; enrolled and analyzed sample sizes; study design features; funding source; results; and risk of bias questions.
Upon examination of the quality of life measures extracted for the 2012 AHRQ review and reported among the new studies, it was apparent that there is great heterogeneity of which quality of life instruments and subscales were reported and how these were analyzed. Many of the measures (e.g., Short Form 36) have a large number of subscales and ways of combining these subscales. We determined that the numerical details of differences in quality of life effects as measured by disparate instruments are unlikely to be of particular interest (e.g., a net difference of −2.1 on a scale ranging from 0–100) and will be very difficult to interpret (e.g., the interpretation of a net difference of −2.1 is different relative to a baseline score of 51 than a baseline score of 97). We believe the most pertinent questions are whether there was a statistically significant difference in quality of life between the interventions compared and which intervention is favored. Thus, for each quality of life measure, we first captured whether a statistically significant difference between interventions was found. If no, we extracted only that it was nonsignificant. However, if a significant difference were found, we calculated the net difference and 95 percent confidence interval (if possible) or difference between final values. This was done to assess the direction and magnitude of the difference.
Assessment of Methodological Risk of Bias of Individual Studies
We assessed the methodological quality of each study based on predefined criteria. For randomized controlled trials (RCTs), we used the same tools used in the 2012 AHRQ review as best we were able to determine from that review. For RCTs, we used the Cochrane risk of bias tool,9 assessing randomization method and adequacy (high/low/unclear risk of bias), allocation concealment method and adequacy (high/low/unclear risk of bias), patient/participant blinding (high/low/unclear risk of bias), outcome assessor blinding (high/low/unclear risk of bias); if the article reported the study was “double blinded,” we assumed that both patient and outcome assessor were blinded. We also captured intention-to-treat (high/low/unclear risk of bias), attrition bias (high/low/unclear risk of bias), group similarity at baseline (high/low/unclear risk of bias), adequate description of interventions (yes/no), and intervention compliance/adherence (high/low/unclear risk of bias). For observational studies, we used relevant questions from the Newcastle Ottawa Scale.10 Note that for observational studies, the 2012 AHRQ review assessed only study strategies to reduce bias and justification of sample size. Thus, assessment of risk of bias of observational studies differs between older and newer studies. For nonrandomized comparative studies (NRCS), we evaluated outcome assessor blinding, attrition bias, group similarity at baseline, whether groups were selected in a similar manner (high/low/unclear risk of bias), whether analyses were adjusted for differences between groups (yes/no), adequate description of interventions, compliance/adherence. For single group studies (for adverse events), we captured information on attrition bias and adequacy of intervention description. For all studies, we also included descriptions of “other” biases or issues.
Data Synthesis
All eligible studies from the 2012 AHRQ review and the updated searches were evaluated together without regard for the source of the study.
All included studies are summarized together in narrative form and in summary tables that tabulate the important features of the study populations, design, intervention, outcomes, and results. In addition, we have included descriptions of the study design, sample size, interventions, followup duration, outcomes, results, and study quality.
We analyzed both specific interventions and categories of interventions. Upon reviewing the list of evaluated interventions, we categorized them as follows:
- Behavioral therapy (nonpharmacological):
- Bladder training, biofeedback, bladder support, cones, education, heat therapy, MBSR (mindfulness-based stress reduction), PFMT (pelvic floor muscle therapy), spheres, weight loss, yoga.
- Intravesical pressure release device (nonpharmacological).
- Neuromodulation (nonpharmacological), “the alteration of nerve activity through targeted delivery of a stimulus, such as electrical stimulation…, to specific neurological sites in the body”:22
- Electroacupuncture, InterStim™, magnetic stimulation, TENS (transcutaneous electrical nerve stimulation, including transvaginal, surface, and related electric stimulation).
- Periurethral bulking (nonpharmacological):
- Autologous fat, carbonated beads, collagen, dextranomer hyaluronate, polyacrylamide, polydimethylsiloxane, porcine collagen.
- Anticholinergics (pharmacological):
- Darifenacin, fesoterodine, flavoxate, oxybutynin, pilocarpine, propantheline, propiverine, solifenacin, tolterodine, trospium.
- Alpha agonist (pharmacological):
- Duloxetine, midodrine, phenylpropanolamine.
- Hormones (pharmacological):
- Vaginal estrogen, oral estrogen, subcutaneous estrogen, transdermal estrogen, raloxifene.
- Onabotulinum toxin A (BTX) (pharmacological)
- Other pharmacological: Pregabalin (antiepileptic).
Urinary Incontinence Outcomes: Network Meta-Analysis
The main assumptions of network meta-analysis are:
- Exchangeability of treatments
- Treatment C in a trial that compares A to C is similar to Treatment C in a trial that compares B to C.
- Exchangeability of patients
- Participants included in the network could, in principle, be randomized to any of the treatments.
- The “missing” treatments in each trial are missing at random or conditional only on known variables.
- Trials do not differ with respect to distribution of effect modifiers
- There are no differences between the observed and unobserved effects beyond random heterogeneity.
A large percentage of the studies (55/140, 39%) combined patients with stress and urgency UI without providing subgroup data. These included studies of treatments commonly used for only stress or only urgency UI. Thus, any analysis of the evidence, whether pairwise or network, would have to mix the two populations. However, we did conduct subgroup analyses of studies that included only patients with stress (60 studies) or urgency (25 studies) UI.
Likewise, in general, studies did not strictly distinguish between 1st, 2nd, and 3rd line therapies. For example, when recruiting patients for a trial of 2nd-line therapies, almost all studies did not report having required patients to have previously failed to improve with a 1st-line therapy. Studies also did not consistently report the severity of UI in the patients, so there was no way to account for that potential heterogeneity of populations in the analyses.
With these limitations in mind, we used network meta-analyses to summarize the study findings for UI outcomes (cure, improvement, and satisfaction) since studies have compared a large number of specific interventions (53) and categories of interventions (16) and many interventions have not been directly compared with each other. Network meta-analysis combines data from direct (head-to-head) and indirect comparisons through a common comparator. Instead of conducting numerous pairwise meta-analyses solely of interventions that have been directly compared in studies, network meta-analysis simultaneously analyzes all interventions that have been compared across studies. We used this approach because it allows efficient analysis and summarization of the corpus of evidence. It also allows estimates of comparisons that have not been directly compared in studies. For the UI outcomes, studies have compared a large number of specific interventions (51) and categories of interventions (14). Thus, across interventions, there are 1275 possible comparisons of specific interventions and 91 possible comparisons of intervention categories, Not surprisingly, the large majority of these comparisons have not been made directly in studies. Network meta-analysis provides simultaneous estimates of comparative effects among all interventions.
However, we recognize that not all comparisons are of equal interest or are clinically meaningful. We took two major approaches to ensure that our conclusions are consistent with clinical logic together with the evidence base. First, based on current guidelines7,8 we categorized interventions based on whether they are used primarily for stress UI or for urgency UI (or both) and also whether they are typically used as 1st, 2nd, or 3rd line therapy. From the overall network meta-analyses, we summarized six (overlapping) sets of comparisons: 1) stress UI interventions compared to no treatment, 2) 1st and 2nd line therapies used for stress UI compared to each other, 3) 3rd line therapies used for stress UI compared to each other or to 1st or 2nd line therapies, 4) urgency UI interventions compared to no treatment, 5) 1st and 2nd line therapies used for urgency UI compared to each other, and 6) 3rd line therapies used for urgency UI compared to each other or to 1st or 2nd line therapies. Second, we sought and summarized comparisons made (directly) within studies that restricted their study participants to women with either stress UI or urgency UI. In theory, the sets of interventions evaluated by these two different approaches (selected interventions from the overall analysis and evaluated interventions from stress- or urgency-only studies) should have corresponded one to one. However, we found several studies of neuromodulation in women with stress UI, despite its being recommended only for women with urgency UI. Ideally, we would have conducted two sets of network meta-analyses, one for stress UI and one for urgency UI, but as described, the evidence base did not allow for this.
Separate network meta-analyses were conducted for each UI outcome (cure, improvement, and satisfaction). Subgroup network meta-analyses were also conducted for 1) studies of women with stress UI only, 2) studies of women with urgency UI only, and 3) studies of older women, regardless of UI type. We conducted network meta-analyses with mixed effects (random intercepts and fixed intervention slopes) or full-random effects (random intercepts and random slopes) multilevel models within the generalized linear and latent mixed models. We used the normal approximation to discrete likelihoods with a canonical (logit) link function. Treatment effect estimates from such models are odds ratios (OR). We fit models by maximizing the (restricted) likelihood. We assessed the consistency of direct and indirect effect estimates by comparing results from network meta-analyses with pairwise meta-analyses. We also qualitatively compared the results of the overall network meta-analyses with results from network meta-analyses of studies of women with either stress UI or urgency UI. See Appendix J for further details regarding network meta-analysis methodology.
We explored clinical and methodological heterogeneity in subgroup analyses. We did not conduct dose-response meta-analyses because there was substantial heterogeneity in the definitions of intervention intensity (e.g., dose) across studies, particularly among the nonpharmacological interventions. Based on their being sufficient available studies and data, we performed the following subgroup network meta-analyses: women ≥60 years of age, urgency UI only studies, and stress UI only studies. There were insufficient data to evaluate the following subgroups: women with high physical activity levels, military personnel or veterans, racial or ethnic minorities, and women with mixed UI.
Because of the relative sparseness of studies that reported data specific to either those with stress UI or urgency UI, we reevaluated the overall network meta-analyses focusing separately on those intervention categories used primarily for either stress or urgency UI. We allowed interventions to be included in both stress and urgency UI analyses (e.g., behavioral therapy, which is used to manage all types of UI). We further, assessed whether intervention categories are used as either first- or second-line therapy in one group or third-line therapy in another group. The categorization of different interventions was based on recommendations from the UK National Institute for Health and Care Excellence (NICE) and American Urological Association (AUA) guidelines.7,8 For stress UI, we included behavioral therapy (1st line), alpha agonists (2nd line), hormones (2nd line), periurethral bulking (3rd line), and intravesical pressure release devices (3rd line). For urgency UI, we included behavioral therapy (1st line), anticholinergics (2nd line), hormones (2nd line), BTX (3rd line), and neuromodulation (3rd line).
To aid the interpretation of these analyses we also present model-based estimates for the mean frequency of an outcome in the examined interventions, as well as forecasts of the frequency of the outcome in a new setting (e.g., a new study or in a population) that is similar to the studies in the meta-analysis. The forecast’s point estimate about the frequency of the outcome is very close to the point estimate of the mean frequency of the outcome over the meta-analyzed studies. However, the 95 percent confidence interval (CI) for a forecast of the frequency of an outcome in a new setting accounts for between-study heterogeneity, and will, thus, be broader than the corresponding 95 percent CI for the mean frequency of the outcome across the analyzed studies.
We assessed inconsistency by comparing the fit of models that do not assume consistent intervention effects versus typical network meta-analysis models that assume consistent treatment effects. Analyses did not identify statistical evidence of inconsistency. Because such analyses are known to be underpowered, we also compared qualitatively the agreement of estimates based only on direct data versus of estimates based on both direct and indirect data. Such estimates were deemed to be congruent.
Quality of Life and Adverse Events
As described above, under Data Extraction and Data Management, quality of life outcomes were extracted and summarized in a semiquantitative manner. Where studies reported no significant difference in quality of life measures between interventions, no further results data were extracted or summarized. Where there were significant differences between interventions, we captured and summarized net difference in quality of life measure (or difference in final values) and full information about the quality of life instrument, including scale and directionality. We calculated and summarized the percentage of people receiving each intervention who reported an adverse even as defined by the individual studies.
Presentation of Results
We present results with plots and tables, namely, evidence graphs, league tables, and comparative effects tables.
Evidence Graphs
We use evidence graphs such as the one in Figure 2 to describe which interventions have been compared with others. An evidence graph comprises nodes, which represent interventions, and edges (depicted by a line linking nodes). Edges connect a pair of nodes only if the corresponding interventions have been directly compared in at least one head-to-head study.
In Figure 2, nodes for interventions from the same intervention category (e.g., alpha agonists) are all within a bubble. For example, nodes C1 (corresponding to the anticholinergic oxybutynin) and C3 (corresponding to the anticholinergic tolterodine) are within the same yellow bubble (anticholinergics).
A “connected subgraph” describes a set of nodes that are connected to each other but not to nodes in other subgraphs. For example, Figure 2 has two connected subgraphs, which include the following nodes:
- B (onabotulinum toxin A) and N2 (InterStim™)
- All remaining nodes in the evidence graph.
Identifying subgraphs is important, because there is no statistical comparison between interventions that belong to different subgraphs.
Figure 3 is an analogous representation of the comparisons among intervention categories for the same network of interventions depicted in Figure 2. When one considers intervention categories, comparisons between interventions that are within the same category are not pertinent. For example, when comparing neuromodulation (node N in the figure) with placebo (node P), the comparison between electroacupuncture (node N1 in Figure 2) and transcutaneous electrical nerve stimulation (TENS, node N4) is not pertinent.
Comparisons of categories of interventions allows more studies to be included in the network meta-analysis than comparisons of individual interventions. In Figure 2, BTX (node B) is in its own subgraph with InterStim™ (node N2), so it cannot be compared with other interventions. However, in Figure 3, InterStim™ (node N2) and TENS (node N4) have been combined into the category neuromodulation (node N) and BTX (node B) is now connected to the other interventions through the intervention category neuromodulation (node N).
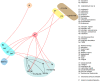
Figure 2
Example evidence graph depicting comparisons between individual interventions. Abbreviations: MBSR = mindfulness-based stress reduction, PFMT = pelvic floor muscle training, TENS = transcutaneous electrical nerve stimulation.
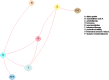
Figure 3
Example evidence graph depicting comparisons between intervention categories.
Comparative Effects Tables
Comparative effects tables describe odds ratio (OR) estimates and 95 percent CIs for all pairwise comparisons in a subgraph. As an example, Table 3 presents the results that correspond to the evidence graph on satisfaction with treatment in Figure 3. The intervention categories being compared are listed across the diagonal line of cells. Each reported OR (95% CI) represents a comparison between the two intervention categories to the left and below the cell. ORs greater than one favor the intervention category to the left of the cell (the row intervention) over the intervention below the cell (the column intervention). Statistically significant ORs are emphasized. Grey shading of the cells indicates that the OR estimate is derived only from indirect evidence (i.e., that no trials directly compared the interventions). For these estimates, the row and column interventions do not have an edge in the evidence graph (e.g., Figure 3). Cells without shading indicate that studies have reported direct (head-to-head) comparisons; the OR estimates reflect a combination of both direct and indirect comparisons from the network meta-analysis.
Note that all estimates of OR are derived from the network meta-analysis. In Table 3, the comparison between anticholinergics and behavioral therapy in informed by the studies that directly compared the two intervention categories and all the indirect comparisons from the network. These estimates are generally close to, but may not be identical to, standard pairwise meta-analysis results. Often confidence intervals are narrower.
Table 3
Example odds ratio table comparing intervention categories.
League Tables
League tables such as Table 4, describe additional measures derived from the network meta-analyses. The “mean percent” represents the average percentage of women with the outcome of interest for each intervention (or intervention category) across the included trials (i.e., the absolute rate). The “forecasted percent” represents an estimate of what percentage of women would have the outcome in a new setting (e.g., in a new study) that is analogous to the settings of the analyzed studies. The forecasted percent is a more conservative, less precise estimate (with wider 95% CI) than the mean percent. In this example, on average 51 percent of women treated with anticholinergics were satisfied with treatment, compared with only 29 percent of women treated with sham therapy. However, the estimates are imprecise. For the women included in the trials, on average the percent who were satisfied with anticholinergics is likely to be somewhere between 32 to 70 percent (the 95% CI). For similar women in a future trial (or in a similar setting), it is likely that between 10 and 91 percent will be satisfied. This wider interval factors in the heterogeneity (differences) among studies.
Table 4
Example mean and forecasted outcome rates by intervention category.
Grading the Strength of Evidence
We grade the strength of the total body of evidence (from the combined 2012 AHRQ review and update) as per the AHRQ Methods Guide on assessing the strength of evidence (SoE).11 We assessed the strength of evidence for each outcome category (UI outcomes, quality of life, and adverse events). Many thousands of comparisons can be estimated based on the network meta-analyses, and we do not characterize the strength of evidence for each one separately. Instead, we characterized the strength of evidence for our main conclusion statements across all intervention categories. For each strength of evidence assessment, we considered the number of studies, their study designs, the study limitations (i.e., risk of bias and overall methodological quality), the directness of the evidence to the KQs, the consistency of study results, the precision of any estimates of effect, the likelihood of reporting bias, other limitations, and the overall findings across studies. Based on these assessments, we assigned a strength of evidence rating as being either high, moderate, or low, or there being insufficient evidence to estimate an effect. The data sources, basic study characteristics, and each strength of evidence dimensional rating are summarized in a “Summary of Evidence Reviewed” table detailing our reasoning for arriving at the overall strength of evidence rating.
Addressing the Contextual Question
To address the contextual question, we followed the general guidance of the U.S. Preventive Services Task Force.5 During abstract screening, we identified any potentially relevant studies that were opportunistically found during the systematic review searches for KQs 1 to 4. To supplement the published literature, we also solicited input (via email) from several clinical and research experts in female urinary incontinence known to the authors via the Society of Gynecologic Surgeons, its Systematic Review Group, the American Urogynecologic Society, and colleagues suggested by selected members of the PCORI stakeholder panel. They were asked for their thoughts on how “patients define successful outcomes for the treatment of UI (i.e., how do patients measure treatment success)”, for suggestions of relevant articles, and for any other thoughts or comments on the issue.
Based on data and input garnered from these sources, we answered the contextual question in a narrative format. We did not systematically extract or review all eligible studies, create summary tables, or assess the strength of evidence. We did not conduct a survey or focus group of women with UI. In summarizing the evidence, we prioritized the findings with a “best evidence” approach, based on the degree to which each study appropriately evaluated ault women with UI, and their opinions and preferences.
The results of the contextual question were fed back into the assessment of studies and of the evidence base. We reviewed the list of included outcomes based on women’s conceptions of what defines a successful outcome.
- Methods - Nonsurgical Treatments for Urinary Incontinence in Women: A Systematic...Methods - Nonsurgical Treatments for Urinary Incontinence in Women: A Systematic Review Update
Your browsing activity is empty.
Activity recording is turned off.
See more...