Accounting for competing risk of non-cardiovascular death
The CG181 model10 accounts for background non-cardiovascular mortality using general population lifetables. A key motivation of this project (see Background) was to improve on this by ensuring that, for any modelled cohort, the competing risk of non-cardiovascular death reflects the life expectancy of people with the specified level of cardiovascular risk. Official lifetables stratify by age and sex; however, the lifetables do not tell us how all-cause mortality might be associated with cause-specific factors, such as cardiovascular risk. Therefore, we needed a method that will enable us, in effect, to estimate cardiovascular risk-specific non-cardiovascular lifetables.
To do this, we fitted a relative survival model to the cardiovascular CPRD data set used in the cardiovascular element of this project (see Chapter 2), using the multiplicative method of Andersen et al.142 This approach is a variant of a Cox proportional hazards model that uses the life expectancy of a reference group (in this case, non-cardiovascular survival in the general population) as a time-varying covariate. For a formal definition of the model, see Appendix 6.
Our rationale for using a relative survival model is threefold. First, we needed some way of not only characterising observed survival in the CPRD data set (which has a median follow-up of 5 years), but also extrapolating to the lifetime horizon of the decision model. Decision-analytic economic models commonly use parametric models to accomplish this type of task; however, such models invariably characterise a discrete cohort of which we can plausibly assume that the members share a survival distribution (e.g. people with newly diagnosed cancer of a given type). In this case, we want to simulate heterogeneous groups of people (e.g. 40-year-old women with a 10-year cardiovascular risk of 2%; 80-year-old men with a 10-year cardiovascular risk of 40%) and it is implausible to assume that we can describe the expected survival of all such groups with a common parametric foundation. With a relative survival model, we do not need to define a functional form, we simply have to estimate a model that we can apply to a baseline drawn from empirical lifetable data, as this will naturally produce survival curves that vary in shape and scale, even though the relative difference between the general population and the modelled cohort is a constant function of the covariates. Second, we wanted an approach we could use to estimate the life expectancy of cohorts for whom the decision to initiate statins takes place in the present day. Characterising the relative relationship between observed survival and expected population survival from contemporaneous lifetables provides us with a model we can then apply to present-day lifetables. In doing this, we make the assumption that, although absolute life expectancy may have changed over time, the extent to which factors of interest affect it generalise across time with minimal bias. Third, relative survival models provide a parsimonious way of summarising complex data. If, as discussed above, we relied on parametric models to extrapolate to lifetime expectation, then we would inevitably need to fit multiple models to discrete subsets of the data; however, if we had chosen too few, then we would have inappropriately lumped people with heterogeneous expectations together, and if we had chosen too many, then we would have generated high-variance estimates with a tendency to overfit to artefacts in uncertain data. In contrast, the relative survival approach enables us to make use of all available data while adjusting for the things that might define groups with different expectations. Another reasonable approach would have been to fit a multistate model to the CPRD data; however, this would not solve the problem of extrapolation beyond the observed evidence and may have given us less flexibility in simulating cohorts with different baseline characteristics and risk profiles.
The output of the relative survival model is the multiplicative difference in time to event (in our case, non-cardiovascular death) between a person in a specific population and someone of the same age and sex in the general population. The coefficients show how this difference varies with each covariate.
For our models, the critical covariate is ΔQ, which we define as the difference between an individual’s predicted 10-year QRISK3 score and the average score for a person of the same age and sex. Because QRISK3 predicted risk is a probability it is bounded between 0 and 1 and, therefore, it becomes mathematically convenient to transform the estimates to a log-odds scale and so we work with Δlogit(Q). Because population lifetables do not provide information on QRISK3 scores we estimated average 10-year risks by age and sex using a regression on the CPRD data set (see Appendix 6, Table 54 and ). Owing to computational constraints, we were unable to fit a single relative survival model to the whole CPRD extract and, therefore, we developed separate models for men and women.
To begin with, we fitted relative survival models with a single coefficient [i.e. Δlogit(Q)].
As lifetables are already stratified by age, it is theoretically not necessary to include a term for it in a relative survival model. However, it is plausible that the effect of other covariates – in this case, Δlogit(Q) – varies with age. Therefore, we also fitted a more complicated model including age and its interaction with Δlogit(Q). At the same time, we explored introducing polynomial terms to account for non-linearity of effect. We found that using quadratic terms for both Δlogit(Q) and age improved the fit of the model (reducing AIC by several hundred points); however, the inclusion of higher-order polynomials provided diminishing returns. Therefore, the linear component of our more complex model takes the form:
shows the results of simple and polynomial models fitted for men and women separately.
Relative survival models: non-cardiovascular mortality as a function of predicted cardiovascular risk and age in men and women
To give a worked example, consider a 60-year-old man with a 10-year QRISK3 predicted CVD risk of 20%. First, using Appendix 6, Table 54, we calculate the average logit(QRISK3) for a person with those characteristics:
On a probability scale, this is a 10-year risk of 14% (i.e. our hypothetical man is subject to higher-than-average risk). Next, we calculate Δlogit(Q), that is the difference between observed and expected risk, and in this case it is logit(0.2) minus −1.815 = 0.429. Plugging this value into our polynomial model gives:
(Note that for summation we use the natural logarithm of the coefficients given in and age is centred around the population mean of 45.43. Therefore, in this case, 60 – 45.43 = 14.57.)
When exponentiated, this value provides a HR of 1.72. Therefore, we estimate that a 60-year-old man with a 10-year QRISK3-predicted CVD risk of 20% is, alongside his raised cardiovascular risk, subject to a hazard of non-cardiovascular death that is more than two-thirds higher than that of an average person of that age and sex. This is the value that we apply to general population lifetables (adjusted to remove cardiovascular deaths) when we simulate the non-cardiovascular life expectancy of a cohort with those characteristics.
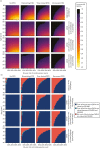
shows estimates of non-cardiovascular mortality generated in the way described above, compared with empirical data across different categories of cardiovascular risk and age. The empirical Kaplan–Meier curves represent observed non-cardiovascular mortality (censored for cardiovascular death) in the CPRD extract for people of the stated age, with baseline QRISK3 predictions in the specified brackets. For our modelled estimates, we start from ONS 3-year lifetables for England and Wales (for this illustration we use 2009–11 tables, as this is in the middle of the period covered by the CPRD data). We adjust these data to remove cardiovascular deaths, estimated using proportions recorded under ICD-10 codes I00–I99 in ONS’s ‘Deaths registered in England and Wales’ series. For each combination of risk and age bracket, we calculate HRs, as described above (for comparability, we fit at the mean QRISK3 prediction and age observed within that category in the CPRD data), and apply the HRs to the ONS curves, and this produces the adjusted curves shown in .
Fitted relative survival models for non-cardiovascular mortality compared with empirical data. (a) Men; and (b) women.
This exercise shows that the approach produces an excellent fit to the observed data. Even though the simple models (i.e. short dash) depend on a single variable, the simple models capture most of the observed variability in non-cardiovascular death. The polynomial models with age interactions (i.e. long dash) improve this fit somewhat further, at least falling within the 95% confidence limits of the observed survival functions in almost all cases. (One exception is 45- to 54-year-old women with a 10-year QRISK3 CVD prediction of 25% ± 2.5%, as these women appear to have better survival than women of the same age with lower cardiovascular risk; however, we consider this an implausible artefact of the relatively small sample of women in the category.)
Note that within each age bracket the unadjusted general population estimate (see ) remains the same across cardiovascular risk categories. Estimating competing-cause mortality on the basis of age and sex alone, without accounting for the way in which it correlates with the risk of interest, is the approach the CG181 model takes,10 but this analysis shows that such an approach can misestimate competing mortality risk to a potentially substantial degree.
For example, for women aged 65–74 years the unadjusted general population estimate suggests that women of this age have around an 84% chance of surviving 10 years without experiencing non-cardiovascular death. However, if a woman in this category had a predicted cardiovascular risk between 7.5% and 12.4%, then she would be uncommonly healthy and so her true 10-year non-cardiovascular survival would be around 91%. Conversely, if a woman had a high QRISK3-predicted risk of the order 27.5%–32.4%, then she would have below-average health and her 10-year non-cardiovascular survival probability would be around only 70%. In the former case, a model relying on unadjusted competing-cause mortality estimates would underestimate likely survival by a non-trivial amount. In the latter case, the bias is reversed. Note that in both cases the unadjusted population expectation is not within the confidence limits of the observed Kaplan–Meier estimate, whereas our adjusted estimates pass closely through them.